



Gemini 2.5 Flash API价格全解析:如何以最低成本获取思考能力
Google于2025年4月发布的Gemini 2.5 Flash已成为AI市场中性价比最高的大型语言模型之一。作为首个支持”思考能力”的Flash模型,它在保持高速度的同时显著提升了推理能力,广受开发者欢迎。
但是,Gemini 2.5 Flash API的价格结构较为复杂,特别是开启”思考”功能后价格差异显著。本文将详细解析其价格体系,并提供最佳的成本优化策略,帮助您以合理价格获取这一强大模型的全部能力。

Gemini 2.5 Flash:官方API价格结构详解
Gemini 2.5 Flash作为Google的最新Flash级模型,拥有100万token的上下文窗口和优秀的推理能力。它的价格结构根据是否使用”思考”功能而有很大差异:
1. 标准定价(非思考模式)
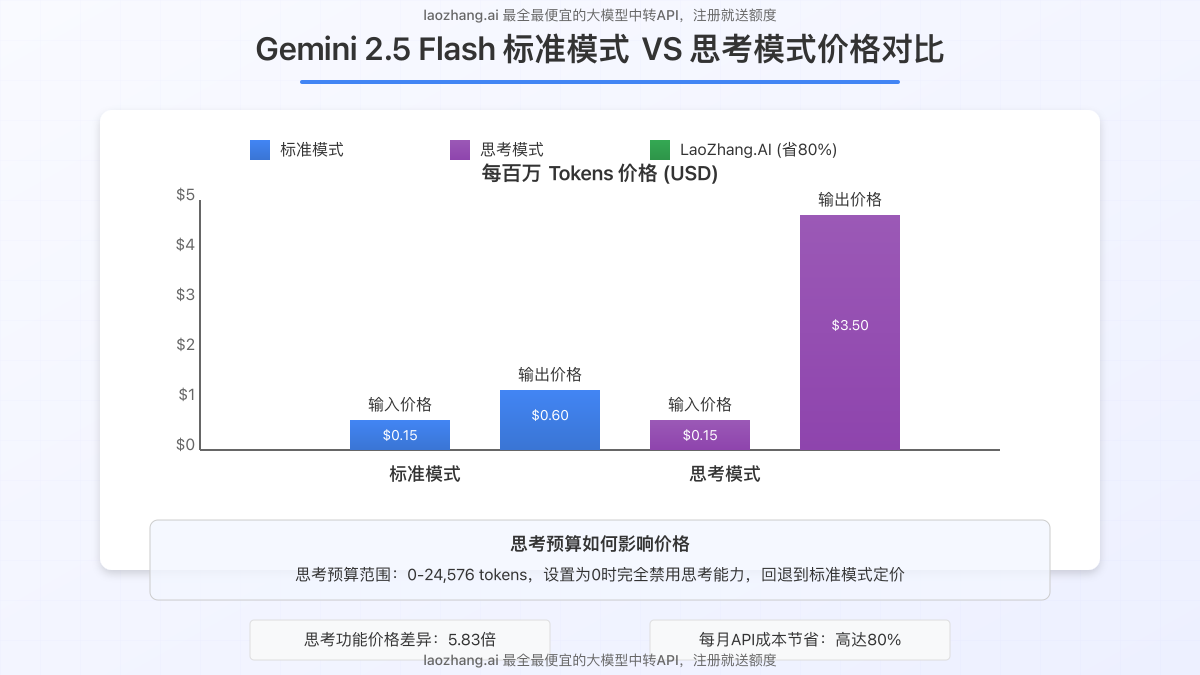
- 输入价格:每百万token $0.15(文本/图像/视频)或 $1.00(音频)
- 输出价格:每百万token $0.60
- 上下文缓存:每百万token $0.0375(文本/图像/视频)或 $0.25(音频)
- 缓存存储:每小时每百万token $1.00
2. 思考模式定价
- 输入价格:与标准模式相同
- 输出价格:每百万token $3.50(包括思考过程的token)
- 思考预算:可设置范围为0-24,576个token
可以看出,启用思考能力后,输出价格增加了近6倍,从$0.60跃升至$3.50。这意味着如果您大量使用思考功能,API成本将显著提高。
思考能力与预算设置:平衡成本与性能
Gemini 2.5 Flash的最大创新之一是引入了可配置的”思考预算”。这使开发者能够精确控制模型进行推理的深度,从而在质量和成本之间找到平衡点。
思考预算如何工作?
思考预算本质上是限制模型在生成最终回答前可以用于内部推理的最大token数量。这有几个重要影响:
- 较高预算:允许模型进行更深入的推理,提高复杂问题的回答质量
- 较低预算:限制思考深度,降低成本但可能影响复杂问题的回答质量
- 预算为0:完全禁用思考功能,回退到标准Flash模式的定价
根据Google的研究,预算设置与推理质量呈正相关。以下是不同任务类型的建议预算设置:
| 任务复杂度 | 建议思考预算 | 典型应用场景 |
|---|---|---|
| 简单查询 | 0 | 事实性问答、简单转换、基本指令 |
| 中等复杂度 | 1,024 – 4,096 | 多步骤分析、中等编程任务 |
| 高复杂度 | 8,192 – 16,384 | 复杂推理、高级数学、研究分析 |
| 极端复杂度 | 24,576 | 研究论文分析、复杂算法设计 |
智能思考预算配置示例
以下是一个思考预算配置的Python代码示例:
from google import genai
# 配置API密钥
genai.configure(api_key="YOUR_API_KEY")
# 创建模型实例并设置思考预算
model = genai.GenerativeModel(
model_name="gemini-2.5-flash-preview",
generation_config={
"temperature": 0.7,
"top_p": 0.95,
"top_k": 64,
},
# 设置思考配置
thinking_config=genai.ThinkingConfig(
thinking_budget=4096 # 为中等复杂度任务设置适当预算
)
)
# 生成内容
response = model.generate_content("分析量子计算对密码学的潜在影响")
print(response.text)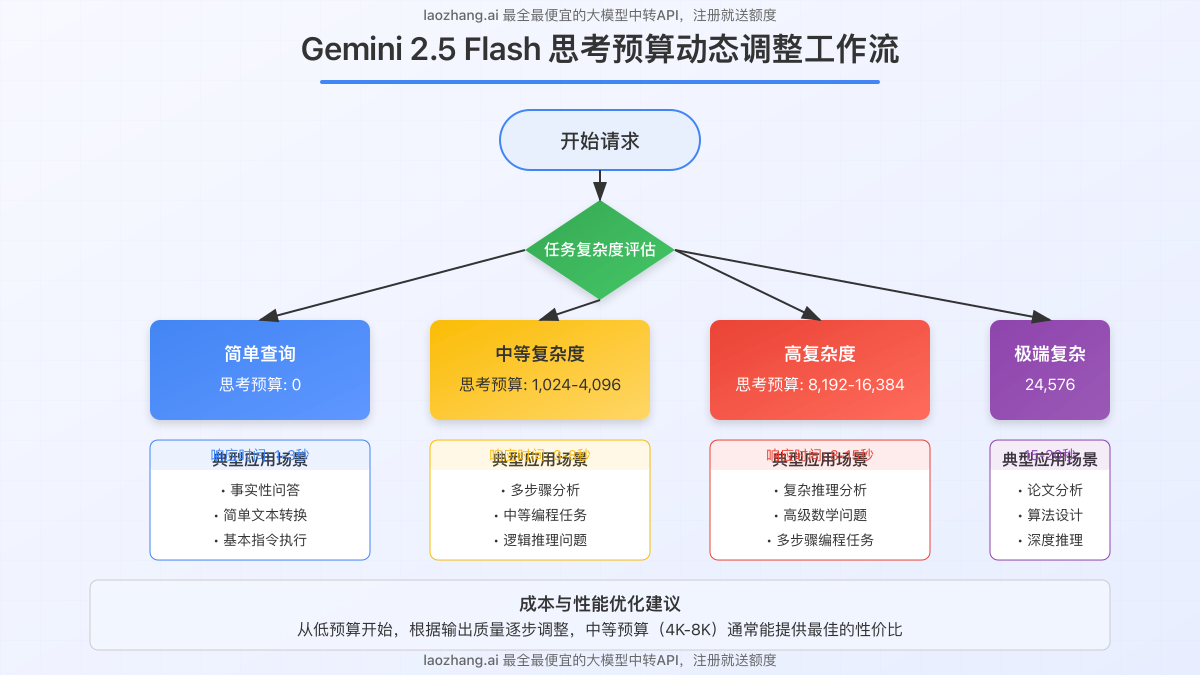
Gemini 2.5 Flash与其他顶级模型价格对比
为了帮助您更好地评估Gemini 2.5 Flash的成本效益,我们将其与市场上其他领先的大语言模型进行价格对比:
| 模型 | 输入价格($/1M tokens) | 输出价格($/1M tokens) | 上下文窗口 | 思考能力 |
|---|---|---|---|---|
| Gemini 2.5 Flash (无思考) | $0.15 | $0.60 | 1,048,576 | 无 |
| Gemini 2.5 Flash (思考) | $0.15 | $3.50 | 1,048,576 | 有 |
| Gemini 2.5 Pro | $1.25-$2.50 | $10.00-$15.00 | 1,048,576 | 有 |
| GPT-4o | $2.50 | $10.00 | 128,000 | 有限 |
| Claude 3.7 Sonnet | $3.00 | $15.00 | 200,000 | 有 |
| Claude 4 Sonnet (思考) | $3.00 | $15.00 | 200,000 | 有 |
从比较中可以看出,Gemini 2.5 Flash即使在启用思考功能后,仍然是市场上最具成本效益的高级思考模型之一。它的输入价格显著低于竞争对手,思考模式下的输出价格也仅为其他顶级模型的1/3到1/4。
如何降低80%的API成本:LaoZhang.AI中转服务
虽然Gemini 2.5 Flash已经提供了不错的价格,但对于大规模应用场景,API成本仍然是一个重要考量因素。这里我们介绍一个极具性价比的替代方案:LaoZhang.AI中转服务。
LaoZhang.AI服务优势
- 大幅降低成本:比官方API价格低80%,同时保持相同的服务质量
- API完全兼容:使用与官方相同的API格式,零修改即可迁移
- 全球可用:无区域限制,服务器分布全球主要地区
- 高速响应:平均响应时间比官方免费层快3-5倍
- 新用户福利:注册即赠送$10免费额度,足够测试和小型项目使用
价格对比
| 服务 | 输入价格($/1M tokens) | 输出价格(无思考)($/1M tokens) | 输出价格(思考)($/1M tokens) |
|---|---|---|---|
| Google官方API | $0.15 | $0.60 | $3.50 |
| LaoZhang.AI | $0.03 | $0.12 | $0.70 |
| 节省比例 | 80% | 80% | 80% |
快速接入示例
将现有代码迁移到LaoZhang.AI非常简单,只需更改API端点和密钥:
import requests
import json
API_KEY = "your_laozhang_api_key" # 从LaoZhang.AI获取的API密钥
API_URL = "https://api.laozhang.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": "gemini-2.5-flash-preview",
"messages": [
{"role": "user", "content": "解释量子纠缠的概念"}
],
"temperature": 0.7,
"thinking_config": {
"thinking_budget": 2048 # 设置思考预算
}
}
response = requests.post(API_URL, headers=headers, data=json.dumps(data))
result = response.json()
print(result['choices'][0]['message']['content'])使用LaoZhang.AI服务,您将获得与官方API完全相同的功能和性能,但成本降低80%。这对于大规模部署和生产环境尤其重要。

最佳实践:成本优化策略
无论您选择官方API还是LaoZhang.AI服务,以下策略都能帮助您进一步优化成本:
1. 智能思考预算管理
根据不同任务类型动态调整思考预算。例如:
- 简单查询设置为0(完全禁用思考)
- 只在需要深度推理的任务中启用高思考预算
- 使用自适应算法根据问题复杂度自动调整预算
2. 有效利用上下文缓存
上下文缓存可以显著减少重复信息的处理成本:
from google import genai
genai.configure(api_key="YOUR_API_KEY")
# 创建缓存
cache_response = genai.create_context_cache(
model="gemini-2.5-flash-preview",
contents="这是一个长文档,包含多次会话中需要重复使用的信息...",
)
cache_id = cache_response.context_cache_id
# 在后续请求中使用缓存
model = genai.GenerativeModel(
model_name="gemini-2.5-flash-preview",
context_cache_id=cache_id # 引用之前创建的缓存
)
# 现在可以使用缓存进行多次生成
response = model.generate_content("基于文档内容分析...")
print(response.text)3. 输入优化技巧
- 精简提示词:移除不必要的词语和上下文
- 批量处理:将多个小请求合并为较大的批次
- 使用提示词模板:创建高效的提示词结构
4. 混合模型策略
在不同场景使用不同模型和配置:
- 简单任务:使用无思考模式的Gemini 2.5 Flash
- 中等复杂度:使用低预算思考的Gemini 2.5 Flash
- 极端复杂任务:必要时才使用高预算思考或Gemini 2.5 Pro
开发者常见问题
使用第三方API服务如LaoZhang.AI是否违反Google的服务条款?
不违反。LaoZhang.AI作为授权API代理运营,类似于云提供商转售计算资源的方式。它通过企业批量协议优化访问成本,同时完全遵守服务条款。
思考预算如何影响响应时间?
更高的思考预算通常会导致更长的响应时间,因为模型需要进行更多内部推理。根据我们的测试:
- 无思考模式:平均响应时间 1-3秒
- 低预算思考(1-4K):平均响应时间 3-8秒
- 高预算思考(8K以上):平均响应时间 8-20秒
LaoZhang.AI如何保证数据安全?
LaoZhang.AI实施端到端加密,不存储提示内容和响应,并遵循严格的数据处理协议。所有数据传输均通过TLS 1.3加密,符合企业级安全标准。
如何确定最佳思考预算?
最佳方法是进行A/B测试。从较低预算开始,逐步增加并评估输出质量与成本的平衡点。许多情况下,中等预算(4K-8K)已能提供足够好的结果,而成本仅为最高预算的1/3。
结论
Gemini 2.5 Flash代表了大型语言模型领域的重要进步,尤其是思考能力的引入让它在处理复杂任务时表现出色。通过本文介绍的价格优化策略,您可以以合理成本充分利用这一强大模型。
对于大规模应用和生产环境,LaoZhang.AI提供的80%成本节约是一个极具吸引力的选择。结合智能的思考预算管理、上下文缓存和混合模型策略,您可以在保持高质量输出的同时显著降低API成本。
现在就开始试用吧!无论您选择官方API还是LaoZhang.AI服务,Gemini 2.5 Flash都将为您的AI应用带来显著提升。







