5月28日,DeepSeek官方宣布R1模型完成小版本试升级,这次更新虽然没有公布具体的技术细节,但从近期用户反馈来看,升级后的DeepSeek R1在多项能力上都有明显提升。作为目前最强的开源大模型之一,DeepSeek R1自今年1月发布以来,以其优秀的推理能力和开放的生态战略,持续推动AI技术的普惠化发展。本文将深入剖析DeepSeek R1升级版的核心技术特点、多规格模型对比以及实际落地应用案例,并提供完整的部署教程。
一、DeepSeek R1模型体系概述
DeepSeek R1是深度求索公司(DeepSeek)于2025年1月20日发布的专注于推理能力的大型语言模型,在诸多数学、代码和逻辑推理任务上表现出与OpenAI o1相当的性能。其模型体系包括三个主要部分:
- DeepSeek-R1-Zero:通过纯强化学习(RL)训练,无需监督微调(SFT)作为初始步骤,展示了令人瞩目的推理能力
- DeepSeek-R1:满血版模型,整合了多阶段训练和冷启动数据,解决了R1-Zero的可读性和语言混合等问题
- DeepSeek-R1-Distill系列:从R1蒸馏而来的小型高效模型,包括1.5B、7B、8B、14B、32B和70B等不同参数规模的版本
此次升级版本保持了与之前版本相同的API接口和使用方式,主要针对核心推理能力和模型稳定性进行了优化,是一次”小版本试升级”,但从实际体验来看,提升非常明显。
二、DeepSeek R1的核心技术创新
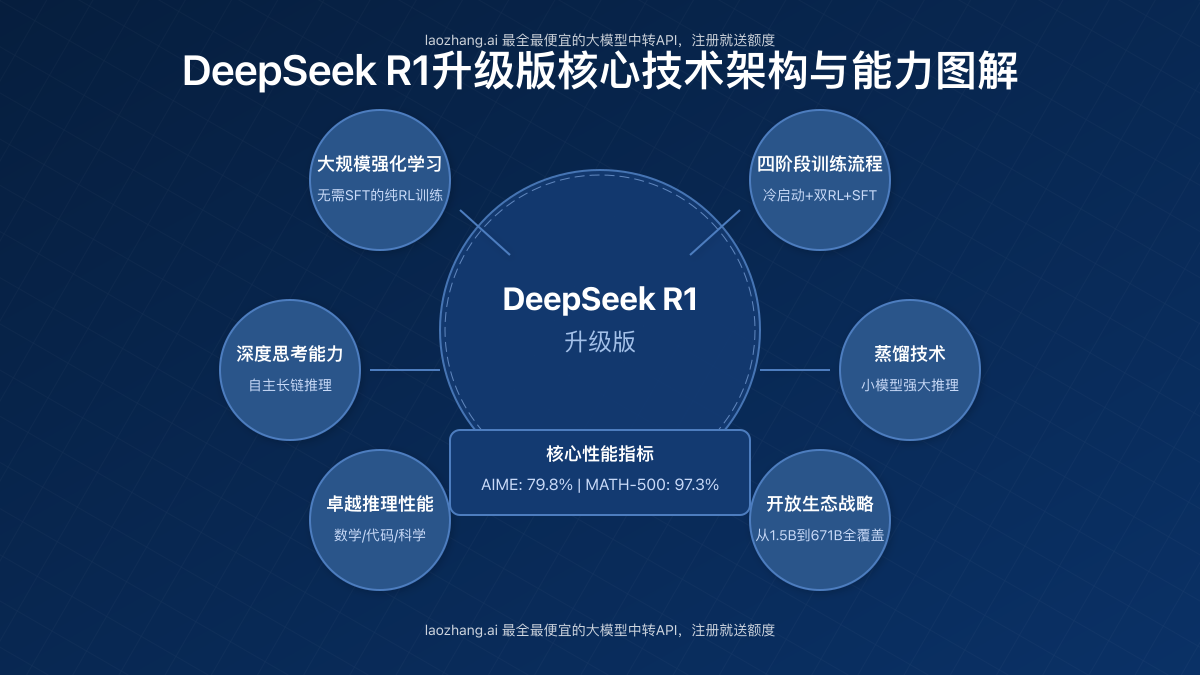
DeepSeek R1系列模型的核心技术创新主要体现在以下几个方面:
1. 大规模强化学习技术
与传统大语言模型不同,DeepSeek R1最大的技术突破在于直接将强化学习应用于基础模型,无需依赖监督微调作为预备步骤。这种方法使模型能够通过思维链(Chain-of-Thought)自主探索解决复杂问题的方法,形成了独特的深度思考能力。
团队采用了GRPO(Group Relative Policy Optimization)作为强化学习框架,这种方法无需与策略模型相同大小的评论家模型,而是从组得分中估计基线,有效节省了训练成本。
2. 冷启动与多阶段训练流程
为了解决R1-Zero在可读性和语言混合方面的问题,DeepSeek团队为R1模型设计了一个包含四个阶段的训练流程:
- 冷启动数据收集:构建了数千条长思维链数据对DeepSeek-V3-Base进行微调
- 面向推理的强化学习:应用与R1-Zero相同的大规模强化学习训练过程
- 拒绝采样与监督微调:利用RL收敛后的检查点收集SFT数据,包括推理和非推理领域
- 全场景强化学习:实施第二阶段强化学习,提高模型的有用性和无害性
3. 蒸馏技术赋能小模型
DeepSeek团队通过一种直接蒸馏方法,将R1的推理能力转移到小型密集模型中。他们使用R1精心策划的80万个样本,直接微调了基于Qwen和Llama的开源模型,显著提升了这些小模型的推理能力。值得注意的是,这些蒸馏模型仅应用了SFT而没有包含RL阶段,但性能依然出色。
三、DeepSeek R1升级版性能评测
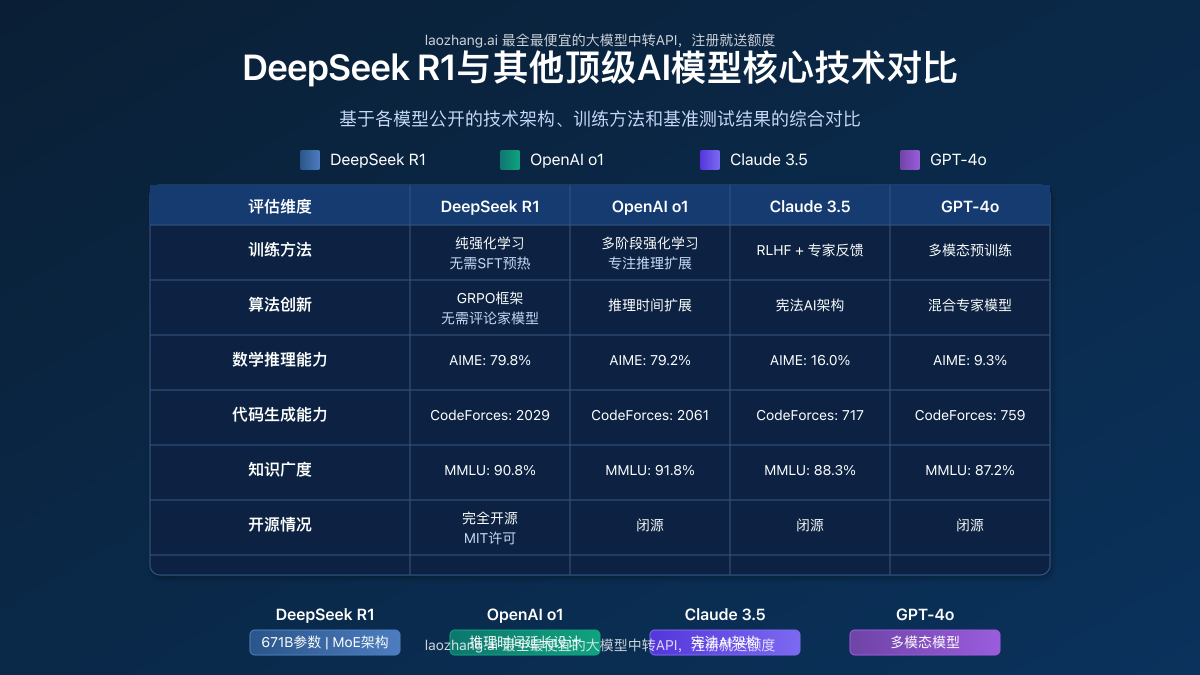
此次升级的DeepSeek R1在多项基准测试上都取得了优异成绩。以下是与其他顶级模型的详细性能对比:
1. 推理任务表现
在数学和编程等核心推理任务上,DeepSeek R1表现尤为突出:
- AIME 2024:R1达到79.8% Pass@1的成绩,略超OpenAI-o1-1217
- MATH-500:获得了97.3%的惊人高分,与OpenAI-o1-1217相当
- Codeforces:达到2029 Elo评级,超过96.3%的人类参赛者
- LiveCodeBench:在65.9%的Pass@1-COT成绩上超越了o1-mini
2. 知识型任务表现
在考察模型知识广度和深度的测评中,R1同样表现不俗:
- MMLU:90.8%,显著优于DeepSeek-V3的88.5%
- MMLU-Pro:84.0%,超越了GPT-4o的72.6%
- GPQA Diamond:71.5%,略低于OpenAI-o1-1217但远超其他模型
- SimpleQA:在事实型查询上的表现优于DeepSeek-V3
3. 中文能力评测
升级后的DeepSeek R1在中文任务上也有显著提升:
- CLUEWSC:92.8%,优于Claude-3.5-Sonnet的85.4%
- C-Eval:91.8%,大幅领先GPT-4o的76.0%
- C-SimpleQA:63.7%,接近DeepSeek-V3的水平
4. 开放式生成任务
在考察模型创造力和表达能力的开放式任务中:
- AlpacaEval2.0:87.6%的长度控制胜率
- ArenaHard:92.3%的胜率,展示了其在非考试导向查询上的强大能力
四、DeepSeek R1各参数版本对比
DeepSeek R1系列提供了从1.5B到671B不同参数规模的模型版本,可以根据不同的硬件条件和应用场景选择合适的模型:
| 模型版本 | 基础模型 | AIME 2024 | MATH-500 | 推荐硬件 | 适用场景 |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 28.9% | 83.9% | CPU或4GB显存 | 本地测试、移动设备 |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 55.5% | 92.8% | 8GB显存 | 中等复杂度任务 |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 50.4% | 89.1% | 8GB显存 | 代码生成、逻辑推理 |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 69.7% | 93.9% | 16GB显存 | 企业级复杂任务 |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 72.6% | 94.3% | 24GB+显存 | 高精度专业领域 |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 70.0% | 94.5% | 多卡并行 | 企业级大规模应用 |
在本次升级中,各个参数规模的模型都进行了相应优化,其中性价比最高的是DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Qwen-14B,它们能在相对有限的硬件资源下提供接近大模型的推理能力。
五、DeepSeek R1在各行业的落地应用
尽管DeepSeek R1热度有所下降,但它在各个行业的实际应用却持续扩大。以下是几个代表性的落地案例:
1. 教育领域:西藏大学”藏大智言”平台
西藏大学推出的”藏大智言”DeepSeek平台,将人工智能教学服务延伸至雪域高原。该平台基于DeepSeek R1模型,帮助高原地区师生获取优质教育资源,提升教学效率和质量。
2. 政务应用:拉萨高新区智慧政务
拉萨高新区通过搭建DeepSeek政务大模型应用,成为拉萨市打造高原特色”智慧政务”的试点先锋。此外,西藏自治区昌都市政务云已完成DeepSeek大模型部署,实现了政务服务的智能化升级。
3. 零售服务:瑞幸咖啡AI智能体
5月26日,瑞幸咖啡在官方APP和微信小程序正式上线首个AI智能体(1.0版),实现在线”动动嘴就能点咖啡”的便捷体验。该智能体接入DeepSeek及豆包大模型,由瑞幸咖啡与火山引擎联合打造。
4. 金融行业:智能报告与ESG分析
多家券商利用DeepSeek来读取沪深300成份股的ESG报告等文件,提高分析效率和准确性。DeepSeek R1的强大推理能力使其在处理复杂的金融文本和数据分析方面表现出色。
5. 政府财政:智能审核系统
中科江南基于DeepSeek开发智能体,在财政业务AI智能助手、智能报告、智能辅助审核等方面向客户提供应用,大幅提升了财政业务的处理效率和准确性。
六、DeepSeek R1本地部署完全指南
对于希望在本地环境中部署DeepSeek R1的用户,以下是完整的部署指南:
1. DeepSeek-R1-Distill系列模型部署
DeepSeek-R1-Distill系列模型可以与Qwen或Llama模型相同的方式使用。以下是使用vLLM启动服务的示例:
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager使用SGLang启动服务的示例:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 22. 本地运行建议
使用DeepSeek R1系列模型时,建议遵循以下配置以获得预期性能:
- 将温度设置在0.5-0.7范围内(推荐0.6)以防止无尽重复或不连贯的输出
- 避免添加系统提示词;所有指令应包含在用户提示中
- 对于数学问题,建议在提示词中包含指令:”请逐步推理,并将最终答案放在\\boxed{}”
- 评估模型性能时,建议进行多次测试并平均结果
- 强制模型在每个输出的开头使用”
\n”,以确保模型进行充分推理
3. 不同规格模型的硬件需求
根据不同的模型规格,所需的硬件资源也各不相同:
- 1.5B参数版本:最低4核CPU,8GB内存,无需GPU(纯CPU推理)
- 7B参数版本:8核+ CPU,16GB+内存,推荐8GB+显存(如RTX 3070/4060)
- 14B参数版本:12核+ CPU,32GB+内存,16GB+显存(如RTX 4090或V100)
- 32B参数版本:16核+ CPU,64GB+内存,24GB+显存(如A100 40GB或双卡RTX 3090)
- 70B参数版本:32核+ CPU,128GB+内存,多卡并行(如2x A100 80GB或4x RTX 4090)
4. 性价比最高的部署方案
根据性能测试和资源需求分析,DeepSeek-R1-Distill-Qwen-7B是性价比最高的模型:
- 资源需求低:单卡V100或A100即可满足部署需求,显存占用低
- 性能表现优异:在lmdeploy和vLLM部署方式下,推理速度快,A100单卡32并发时速率可达1490.2 tokens/s
- 能力评测优秀:在逻辑推理、哲学伦理、语言理解和知识广度等方面表现稳定
- 实际部署优势:硬件要求低,部署成本低,推理速度快,适合高并发场景
七、使用中转API服务更便捷地接入DeepSeek R1
对于不想自建基础设施或追求更便捷部署方式的用户,可以选择使用API中转服务,如laozhang.ai中转API平台,该平台提供了对DeepSeek R1的便捷接入。
1. 注册与接入
用户可以通过以下地址注册并获取API密钥:https://api.laozhang.ai/register/?aff_code=JnIT
2. API调用示例
以下是一个简单的API调用示例:
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "deepseek-r1",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'3. 使用API中转服务的优势
- 零基础设施投入:无需购买和维护高性能GPU服务器
- 按需付费:根据实际使用量付费,避免资源浪费
- 即开即用:获取API密钥后立即可用,无需复杂部署
- 技术支持:提供专业的技术支持和稳定的服务保障
- 兼容性强:API接口兼容OpenAI格式,便于从其他模型迁移
八、DeepSeek R1的未来展望
随着R1小版本的升级完成,业界更加期待即将推出的DeepSeek R2模型。根据目前的市场传闻,R2可能具有以下特点:
- 更大的参数规模:传闻R2的参数规模可能达到1.2万亿,相比R1的6710亿参数几乎翻倍
- 更高效的设计:R2的动态激活参数为780亿,实际消耗的计算量仅为总参数的6.5%
- 更强的推理能力:预计将在数学、代码和科学推理等方面进一步超越当前最先进的模型
- 更广泛的应用场景:将支持更多垂直领域和特定场景的应用需求
此外,DeepSeek团队在未来版本中可能会重点解决以下几个方面的挑战:
- 通用能力:增强函数调用、多轮对话、复杂角色扮演和JSON输出等能力
- 语言混合:解决处理非中英文查询时的语言混合问题
- 提示工程:优化模型对提示词的敏感性,特别是对少样本提示的处理
- 软件工程任务:提升在软件工程基准测试上的表现
九、结论与建议
DeepSeek R1升级版在保持原有架构的基础上,通过优化训练流程和参数调整,进一步提升了模型的推理能力和稳定性。其满血版和蒸馏系列模型为不同场景和硬件条件提供了灵活的选择,使AI技术真正走向普惠化。
对于不同用户,我们有以下建议:
- 个人开发者:可选择DeepSeek-R1-Distill-Qwen-1.5B或7B版本在本地部署,或使用中转API服务
- 中小企业:根据业务需求选择7B至14B的模型,平衡性能与成本
- 大型企业:可考虑部署32B或70B版本,或直接使用DeepSeek官方API
- 研究机构:探索满血版671B模型,深入研究其推理机制和技术创新
总之,DeepSeek R1升级版的发布不仅展示了中国AI技术的快速进步,也为全球AI社区提供了更加开放、高效的技术选择。我们期待DeepSeek在未来能够继续引领推理型大模型的发展,为各行各业的智能化转型提供强大动力。