DeepSeek R1作为中国顶尖AI企业DeepSeek(深度求索)在2025年1月20日推出的推理大模型,凭借其卓越的推理能力和开源策略,迅速在全球AI领域崭露头角。5月28日晚,DeepSeek官方在交流群中宣布,DeepSeek R1模型已完成小版本试升级,此次更新保持了API接口和使用方式的一致性,同时对模型核心能力进行了显著提升。本文将深入解析此次更新的主要内容、技术特点以及对用户的实际影响。
DeepSeek R1模型概述与发展历程
在深入了解此次更新前,我们有必要回顾DeepSeek R1的基本情况。作为DeepSeek公司继V3之后推出的专注推理能力的大模型,R1采用了创新的大规模强化学习训练方法,无需预先进行监督微调就能显著提升模型的推理能力。
DeepSeek R1自发布以来,在MMLU-Pro、GPQA、AIME等多个权威基准测试中表现出色,特别是在数学和代码生成领域的能力甚至超越了OpenAI的o1模型。更值得一提的是,DeepSeek还推出了多个蒸馏版本,如DeepSeek-R1-Distill-Qwen系列和DeepSeek-R1-Distill-Llama系列,使小型设备也能获得强大的推理能力。
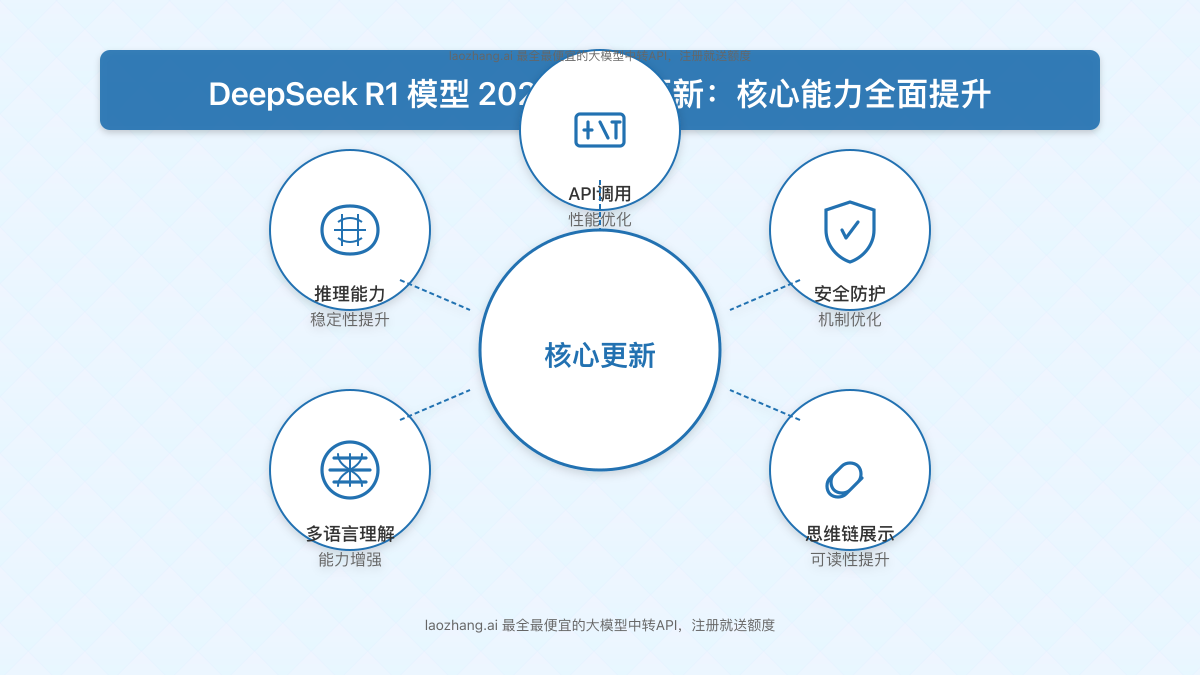
DeepSeek R1五月更新的核心改进
根据官方公告和用户反馈,此次DeepSeek R1的小版本更新主要集中在以下几个方面:
1. 推理能力的稳定性提升
此次更新显著改善了模型在长时间推理过程中的稳定性,解决了之前版本在处理复杂多步骤推理时可能出现的中断或逻辑跳跃问题。特别是在数学证明和算法设计等领域,模型能够更连贯地完成复杂推理链。
2. 安全防护机制优化
针对今年2月和3月发布的多份安全评估报告指出的漏洞,此次更新强化了R1的安全防护机制。中国联通发布的《中文环境下DeepSeek模型安全性评估》和其他安全机构的研究均指出R1存在被”越狱”(jailbreak)的风险。此次更新明显提升了模型抵御恶意提示的能力,尤其是对”恶意越狱”技术的防护。
3. 多语言理解能力增强
尽管R1的核心优势在于推理能力,但此次更新也改善了其多语言处理能力,特别是在中英文混合输入场景下的表现。模型现在能更准确地理解和处理中英混合提示,同时保持推理质量。
4. 更好的思维链展示
DeepSeek R1的一大特色是透明的思维过程展示,此次更新优化了思维链的可读性和逻辑性,使用户能更清晰地理解模型的推理路径。这不仅增强了用户对模型输出的信任,也为教育和学习提供了宝贵资源。
5. API调用性能优化
本次更新还针对API调用进行了优化,提升了响应速度和并发处理能力,特别是在高负载情况下的稳定性。这对于将R1集成到生产环境的企业用户来说是一项重要改进。
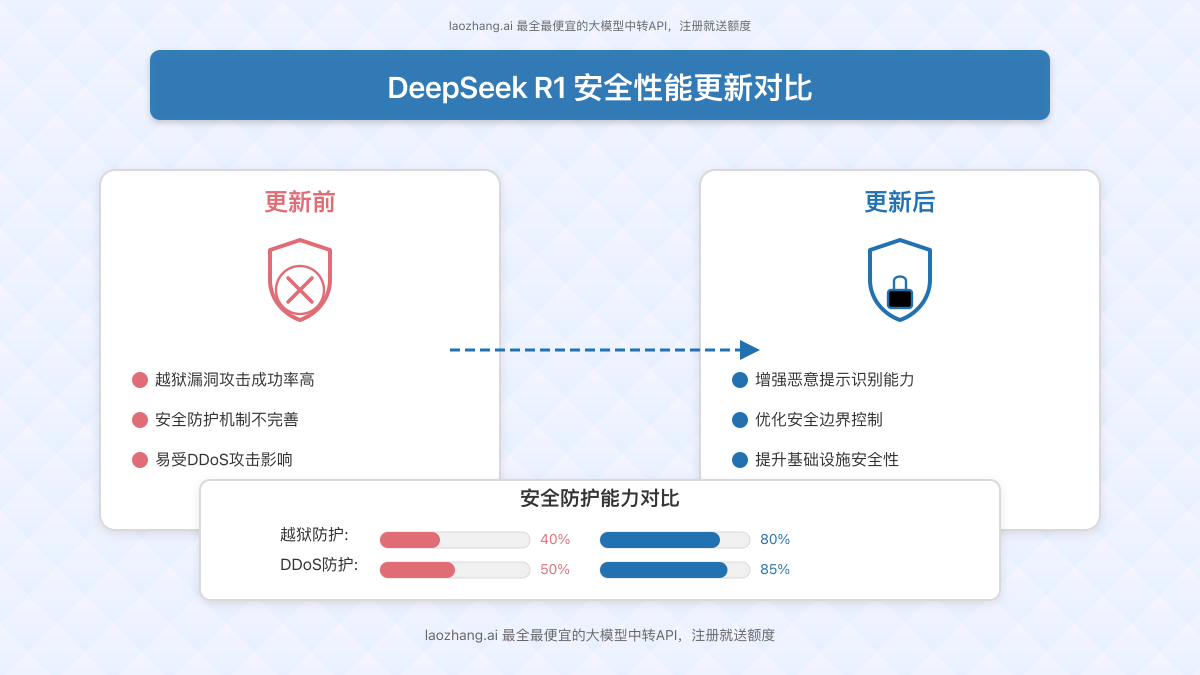
安全性改进:应对之前的漏洞挑战
安全性一直是大模型领域的重要议题,DeepSeek R1也不例外。今年早些时候,多家安全公司和研究机构对R1进行了安全评估,发现了一些值得关注的问题:
1. 越狱漏洞:思科子公司Robust Intelligence与宾夕法尼亚大学的研究显示,DeepSeek-R1在处理有害提示时的攻击成功率较高。
2. 安全防护不足:360安全、帕洛阿尔托网络等公司的测试表明,R1的安全防护机制相比其他主流模型还有提升空间。
3. DDoS攻击风险:由于R1的火爆,其服务曾遭受大规模DDoS攻击,这凸显了基础设施安全的重要性。
此次更新针对这些安全挑战进行了专项优化,特别是在防御恶意提示方面。根据初步测试,新版本R1在面对常见越狱技术时表现出了更强的抵抗力,这对于企业用户而言是一个重要的安全保障。
API接口优化与调用示例
虽然此次更新保持了API接口的一致性,但在性能和稳定性方面有所提升。以下是使用laozhang.ai中转API调用DeepSeek R1的示例代码:
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "deepseek-r1",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "请分析以下数学问题并一步步求解: 一个正方形的面积是64平方厘米,求它的周长。"}
]
}'对于需要引导模型进行深度推理的场景,建议在提示中明确要求模型展示思考过程,例如:
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "deepseek-r1",
"stream": false,
"messages": [
{"role": "system", "content": "请以开始你的思考过程,并在完成思考后以 结束。然后给出最终答案。"},
{"role": "user", "content": "解决以下问题:有一个圆形游泳池,直径为10米。如果一个人每分钟能游50米,那么他沿着游泳池边缘游一圈需要多少时间?"}
]
}'用户体验反馈与实际效果
尽管官方没有详细公布此次更新的具体内容,但根据社区用户的初步反馈,新版本在以下方面有明显改善:
- 更稳定的长链推理:在处理多步骤数学证明和复杂算法设计时,新版本能够保持更连贯的思维链。
- 减少幻觉问题:在事实性知识回答中,幻觉现象有所减少。
- 更流畅的多轮对话:在延续上下文的多轮对话中,模型能更好地保持一致性。
- 更好的指令遵循:对于复杂的多部分指令,模型的遵循能力有所提升。
- 响应速度提升:尤其在使用官方渠道(网页、App、小程序)访问时,响应速度有明显改善。
企业应用最佳实践
对于计划在企业环境中应用DeepSeek R1的用户,我们建议以下最佳实践:
1. 温度参数设置
根据官方建议,为获得最佳性能,建议将温度参数设置在0.5-0.7范围内(推荐0.6),以防止无限重复或不连贯的输出。
2. 提示词优化
避免在系统提示中添加指令,而是将所有指令放在用户提示中。对于数学问题,建议在提示中加入”请逐步推理,并将最终答案放在\boxed{}中”。
3. 多次评估
在评估模型性能时,建议进行多次测试并取平均结果,以获得更可靠的评估。
4. 强制思考模式
为确保模型进行彻底推理,建议强制模型在每次输出开始时使用”
5. API集成安全实践
在将DeepSeek R1集成到企业应用中时,建议实施额外的安全措施,如输入验证、输出过滤和敏感信息处理,以增强整体安全性。
与其他主流大模型的对比
DeepSeek R1更新后,与其他主流推理模型的差异主要体现在以下几个方面:
| 模型 | 推理能力 | 开源状态 | 安全性 | API成本 |
|---|---|---|---|---|
| DeepSeek R1(更新后) | ★★★★★ | MIT许可 | ★★★★☆ | 低 |
| OpenAI o1 | ★★★★★ | 闭源 | ★★★★★ | 高 |
| Claude 3.5 Sonnet | ★★★★☆ | 闭源 | ★★★★★ | 中 |
| Gemini Pro 1.5 | ★★★★☆ | 闭源 | ★★★★★ | 中 |
综合来看,更新后的DeepSeek R1在推理能力上与OpenAI的o1相当,但成本大幅降低;在安全性方面虽有提升但仍有改进空间;最大的优势在于其开源特性,允许用户进行自定义微调和部署。
通过laozhang.ai中转API使用DeepSeek R1的优势
通过laozhang.ai中转API使用DeepSeek R1可以获得以下优势:
- 更稳定的访问体验:避免官方API可能的拥堵和限流问题
- 简化的API调用流程:与OpenAI兼容的API格式,降低集成成本
- 更低的使用成本:相比直接调用官方API,laozhang.ai提供更经济的价格方案
- 多模型统一接口:一个API密钥可以访问多种大模型,方便对比和选择
- 技术支持服务:提供专业的技术支持,解决集成过程中的问题
如需使用laozhang.ai中转API,可以通过以下链接注册:https://api.laozhang.ai/register/?aff_code=JnIT
未来发展展望
DeepSeek R1的此次小版本更新为未来大版本更新奠定了基础。根据业内消息,DeepSeek正在研发R2模型,有望在推理能力、多模态理解、知识更新等方面取得进一步突破。
同时,DeepSeek也在持续改进其开源生态系统,为开发者提供更丰富的工具和资源。随着R1系列蒸馏模型的不断优化,我们有理由相信,DeepSeek将继续引领中国大模型的创新发展。
结论
DeepSeek R1的5月小版本更新虽然没有带来革命性的变化,但在推理能力、安全性、多语言处理等方面的渐进式改进,反映了DeepSeek团队对产品质量的不懈追求。这次更新也表明,中国大模型企业正在持续缩小与国际顶尖模型的差距,并在某些领域展现出独特优势。
对于企业用户而言,更新后的DeepSeek R1提供了一个兼具高性能和低成本的选择,特别适合需要强大推理能力的应用场景。通过laozhang.ai等中转服务,企业可以更便捷、经济地将这一先进模型集成到自己的应用中。
随着AI技术的持续发展,我们期待DeepSeek等中国AI企业继续创新,为全球AI生态系统做出更多贡献。