




Google在2025年推出的Gemini 2.5系列大模型实现了突破性的百万级Token上下文窗口,一举超越了行业内所有主流大模型。Gemini 2.5 Pro和Flash版本均支持高达1,048,576个输入Token和65,536个输出Token,这意味着在单次对话中,模型可以处理大约70万英文单词的文本内容,相当于一本完整的《战争与和平》长篇小说。
这种超大规模的上下文窗口为AI应用带来革命性变革,使复杂文档分析、全书理解、大型代码库审查等应用场景成为可能。本文将详细解析Gemini 2.5的Token限制、与其他模型的对比、关键应用场景以及如何通过API高效利用这一能力。
Gemini 2.5模型的Token限制概览
对于大语言模型而言,Token是文本处理的基本单位,通常一个英文单词大约等于1.5个Token,一个汉字大约等于1个Token。模型的上下文窗口越大,能够处理的文本量就越多,理解和推理能力也越强。
根据Google AI官方文档,Gemini 2.5系列的Token限制如下:
- Gemini 2.5 Pro:输入Token上限1,048,576,输出Token上限65,536
- Gemini 2.5 Flash:输入Token上限1,048,576,输出Token上限65,536
- Gemini 2.0 Flash:输入Token上限128,000,输出Token上限8,192
值得注意的是,Gemini 2.5 Pro目前提供了两个版本:标准版支持100万Token上下文,增强版即将支持200万Token。这一规模远超竞争对手,建立了行业新标准。
主流大语言模型Token上下文窗口对比
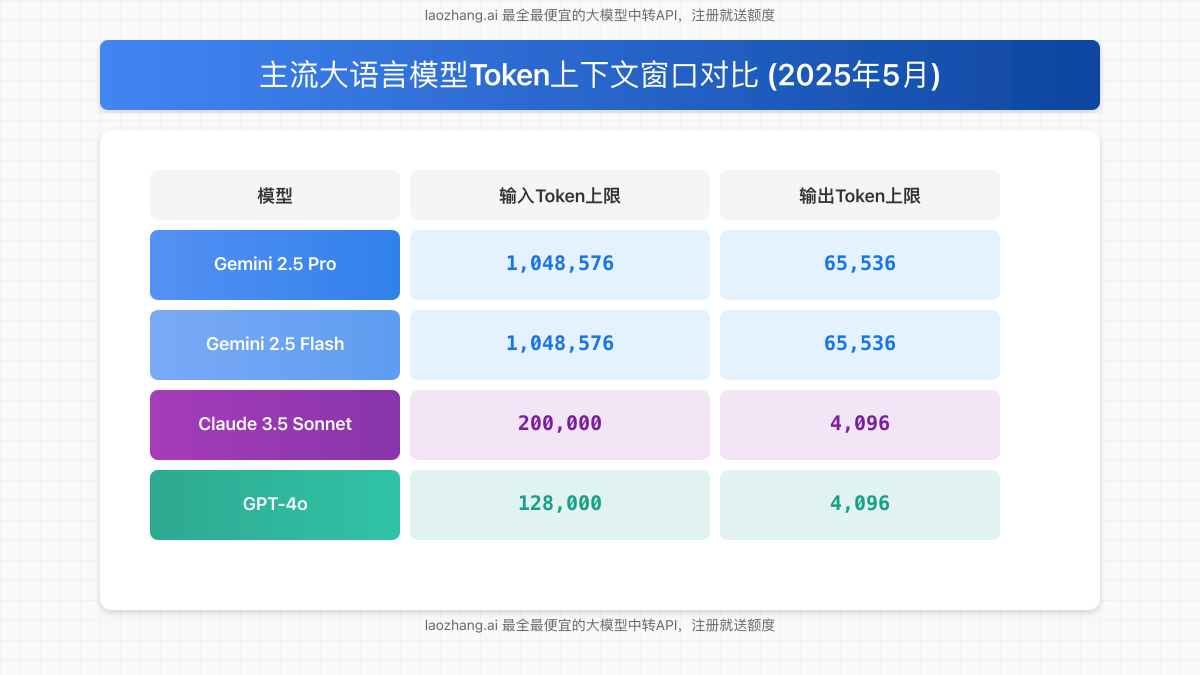
为了更直观地了解Gemini 2.5的优势,我们将其与市场上其他主流大模型进行对比:
| 模型 | 输入Token上限 | 输出Token上限 | 适用场景 |
|---|---|---|---|
| Gemini 2.5 Pro | 1,048,576 | 65,536 | 复杂推理、全书分析、大型代码库理解 |
| Gemini 2.5 Flash | 1,048,576 | 65,536 | 高效率长文本处理、低延迟应用 |
| Claude 3.5 Sonnet | 200,000 | 4,096 | 长文档理解、多轮对话 |
| GPT-4o | 128,000 | 4,096 | 多模态理解、中等长度文档分析 |
| Gemini 1.5 Pro | 1,000,000 | 8,192 | 长文档理解、代码分析 |
从数据对比可以看出,Gemini 2.5系列在上下文长度和输出能力上都显著领先于竞争对手。尤其在输出Token方面,65,536的限制让模型能够生成更加全面、连贯和详细的内容,适合复杂文档生成和深度分析报告。
如何利用百万级Token上下文窗口
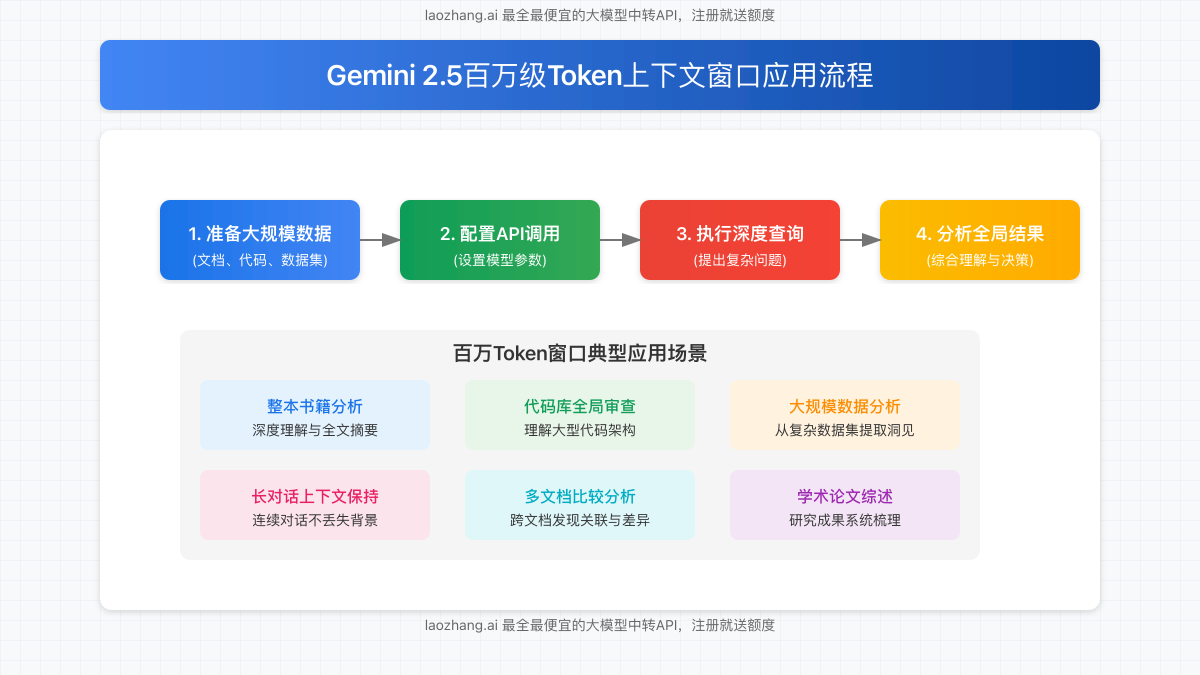
要充分发挥Gemini 2.5超长上下文窗口的优势,需要遵循以下工作流程:
- 准备大规模数据:整合需要分析的文档、代码、数据集等资料,可以是整本书籍、完整代码库或大量历史对话记录。
- 配置API调用:选择合适的模型变体(Pro或Flash),并设置适当的请求参数,包括思考预算控制。
- 执行深度查询:提出复杂、需要全局理解的问题,充分利用模型的长期记忆能力。
- 分析全局结果:接收模型综合大量信息后生成的回答,获取跨文档、跨时间段的深层洞察。
通过laozhang.ai提供的中转API,您可以轻松接入Gemini 2.5系列模型,享受百万级Token的强大能力,同时获得更优惠的价格和稳定的服务。
Gemini 2.5的核心功能特性
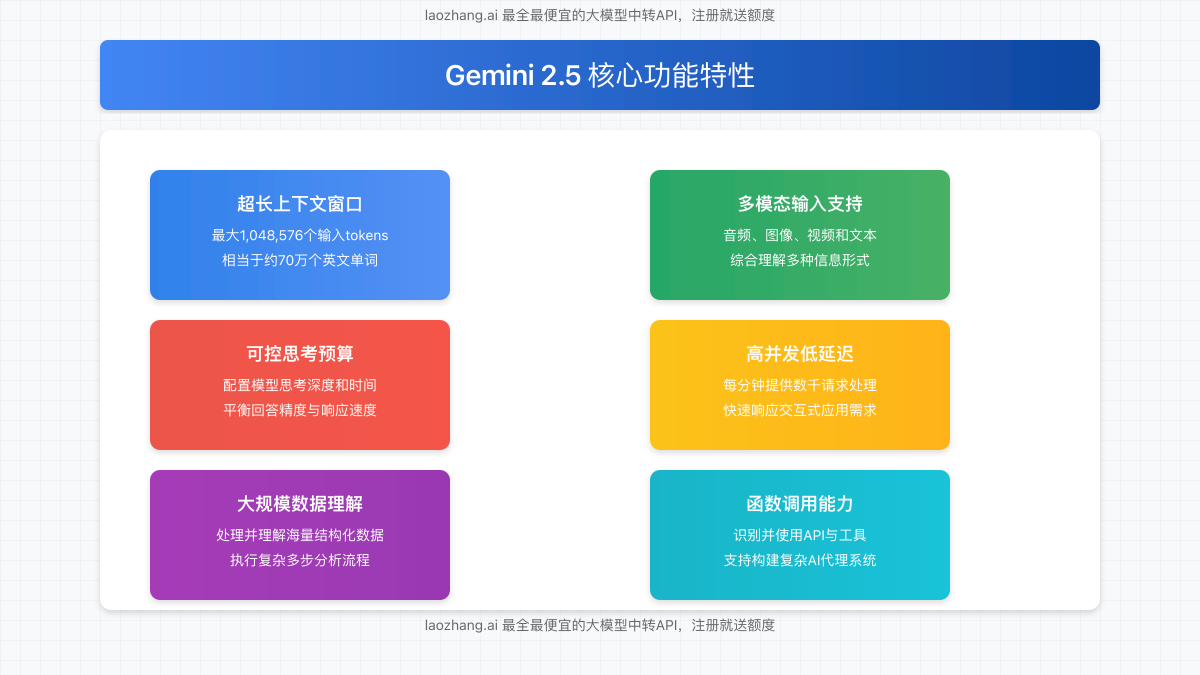
除了超长的上下文窗口外,Gemini 2.5还具备多项强大功能:
超长上下文窗口
最大支持1,048,576个输入Token,相当于约70万英文单词,可处理整本书籍或完整代码库。
多模态输入支持
能够同时处理文本、图像、音频和视频输入,实现跨模态理解和分析。
可控思考预算
允许用户配置模型思考深度和时间,在速度与精度之间找到最佳平衡点。
高并发低延迟
支持高频率API调用,每分钟处理数千请求,适合构建交互式应用。
大规模数据理解
能够处理和理解海量结构化数据,执行复杂多步分析流程。
函数调用能力
识别并使用外部API和工具,支持构建复杂AI代理系统。
百万级Token窗口的行业应用场景
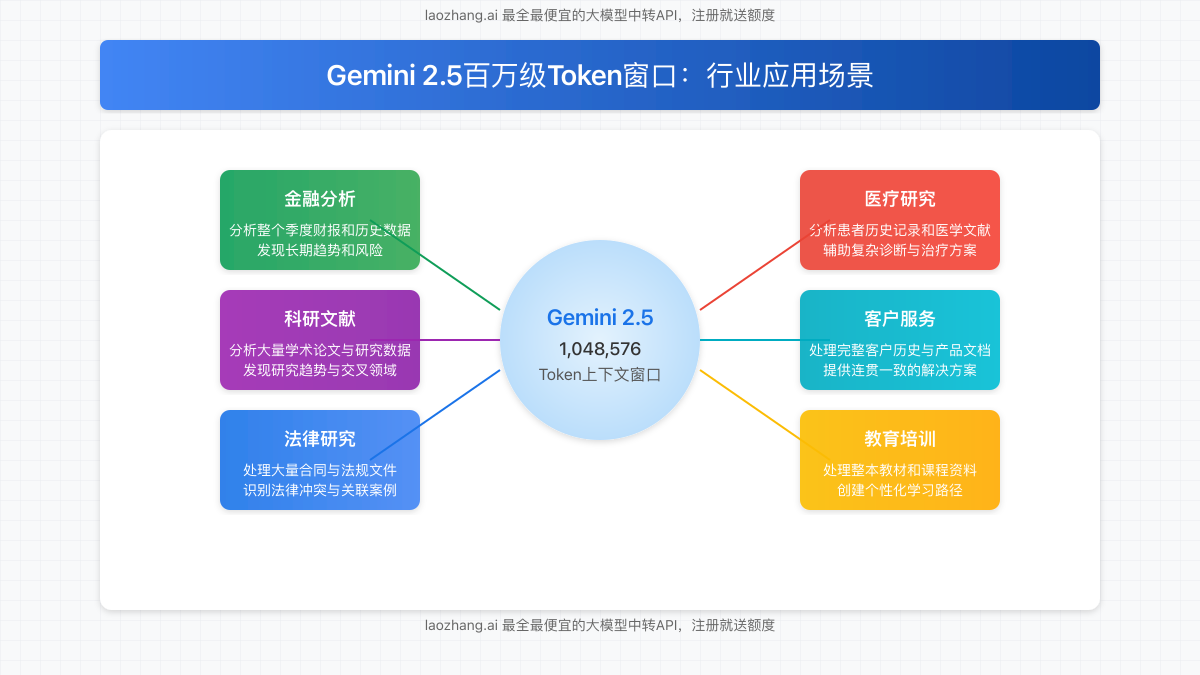
Gemini 2.5的超长上下文窗口为各行业带来了前所未有的应用可能性:
金融分析
分析整个季度的财务报告和历史数据,发现长期趋势和潜在风险,提供更全面的投资建议。
医疗研究
同时处理患者完整病历和相关医学文献,辅助医生制定更准确的诊断和个性化治疗方案。
法律研究
分析大量合同、法规和相关案例,识别潜在法律冲突,提供全面法律意见。
教育培训
处理整本教材和课程资料,创建个性化学习路径,根据学生历史表现提供针对性指导。
科研文献
分析数十甚至上百篇学术论文,发现研究趋势和交叉领域,加速科研突破。
客户服务
全面了解客户历史和产品文档,提供连贯一致的解决方案,大幅提升客户满意度。
通过laozhang.ai快速接入Gemini 2.5 API
要利用Gemini 2.5的百万级Token能力,您可以通过laozhang.ai提供的中转API服务快速接入。laozhang.ai是最全最便宜的大模型中转API服务商,提供稳定可靠的接口和优惠的价格。
注册地址:https://api.laozhang.ai/register/?aff_code=JnIT
以下是通过laozhang.ai调用Gemini 2.5 API的示例:
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gemini-2.5-pro",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "帮我分析这份长文档并总结主要观点..."}
]
}'您只需将API密钥替换为您的实际密钥,并根据需要修改请求参数,即可开始使用Gemini 2.5的强大能力。
Gemini 2.5 API的速率限制
使用Gemini 2.5 API时,需要注意以下速率限制:
- Gemini 2.5 Pro Preview:每分钟最多150个请求,每天最多2,000,000个请求
- Gemini 2.5 Flash Preview:每分钟最多1,000个请求,每天最多1,000,000个请求
通过laozhang.ai中转API服务,您可以获得更优惠的价格和更稳定的服务体验,而且注册即送额度,让您无负担体验Gemini 2.5的强大功能。
结语:百万Token窗口开启AI应用新时代
Gemini 2.5的百万级Token上下文窗口代表了大语言模型技术的重大飞跃,为AI应用开辟了全新领域。通过更全面的理解能力和更深入的分析能力,AI终于可以处理真正复杂的任务,而不再受限于短期记忆。
无论是分析整本书籍、审查大型代码库、研究学术文献集,还是维持长时间连贯对话,Gemini 2.5都能提供前所未有的能力。通过laozhang.ai中转API,这些强大能力现在已经触手可及。立即注册体验,享受最全最便宜的大模型中转服务!
常见问题解答
Gemini 2.5的Token上限是多少?
Gemini 2.5 Pro和Flash版本均支持1,048,576个输入Token和65,536个输出Token,是目前行业最大的上下文窗口之一。
1,048,576个Token大约相当于多少文字?
大约相当于70万英文单词,或者一本完整的《战争与和平》长篇小说。对于中文而言,大约相当于100万字左右。
Gemini 2.5 Free和Advanced版本的Token限制有何不同?
Gemini 2.5 Advanced版本能够使用完整的100万Token上下文窗口,而Free版本的限制较低,通常在32K-128K范围内。
如何有效利用这么大的上下文窗口?
最佳实践是批量处理相关文档、保持对话连贯性、提出全局性问题,以及结合特定领域知识进行深度分析。
使用大量Token会影响响应速度吗?
是的,Token数量越多,模型处理时间通常越长。Gemini 2.5 Flash版本针对长文本进行了优化,提供更好的响应速度。
如何优化API调用成本?
使用laozhang.ai中转API服务可以获得更优惠的价格。此外,合理使用缓存、按需加载上下文、定期清理不相关历史等策略也可以降低成本。
立即体验Gemini 2.5百万Token的强大能力
通过laozhang.ai提供的中转API服务,低成本接入Gemini 2.5,享受稳定可靠的服务和优惠价格。现在注册即送额度!
联系方式:微信 ghj930213







