GLM 4.5:智谱AI最新中文大模型全面解析【2025年深度评测】
GLM 4.5是智谱AI于2025年6月发布的新一代中文大语言模型,在SuperCLUE中文理解榜单以89.3分位列第一,超越所有国际模型。该模型采用355B参数的MoE架构,API价格仅为GPT-4的30%,每百万tokens输入20元输出60元。通过FastGPTPlus充值服务,月费158元即可无限使用。

GLM 4.5是什么?智谱AI的技术突破
GLM 4.5代表着中国大语言模型技术的最新突破。作为智谱AI继GLM-4之后的重要升级版本,这款模型在保持强大通用能力的同时,特别强化了中文理解和生成能力。智谱AI作为清华大学技术成果转化企业,拥有深厚的技术积累,其GLM系列模型一直是国产AI的标杆产品。
与2024年1月发布的GLM-4相比,GLM 4.5在多个维度实现了质的飞跃。模型参数规模从175B提升至355B,采用全新的MoE混合专家架构,将不同领域的知识和能力分散到专门的子模块中。这种设计不仅提高了模型的专业性,还大幅降低了推理成本。在实际使用中,GLM 4.5的响应速度提升了2.3倍,而内存占用却降低了40%。
GLM 4.5的发布时机恰逢其时。2025年6月,正值国内AI应用爆发期,企业和开发者对高质量、低成本的中文AI模型需求旺盛。相比依赖国外模型面临的网络限制、支付困难、数据安全等问题,GLM 4.5提供了一个完全自主可控的解决方案。模型在中文语境理解、本土化应用适配、文化内涵把握等方面展现出明显优势,成为众多企业数字化转型的首选。
在国产AI生态中,GLM 4.5已经确立了领先地位。根据最新的评测数据,它在中文理解、代码生成、数学推理等多个维度全面领先于文心一言4.0、通义千问2.0等竞品。更重要的是,GLM 4.5通过开放的API服务和完善的开发工具,构建了活跃的开发者社区,目前已有超过5万家企业接入使用。
GLM 4.5核心技术架构:MoE混合专家系统
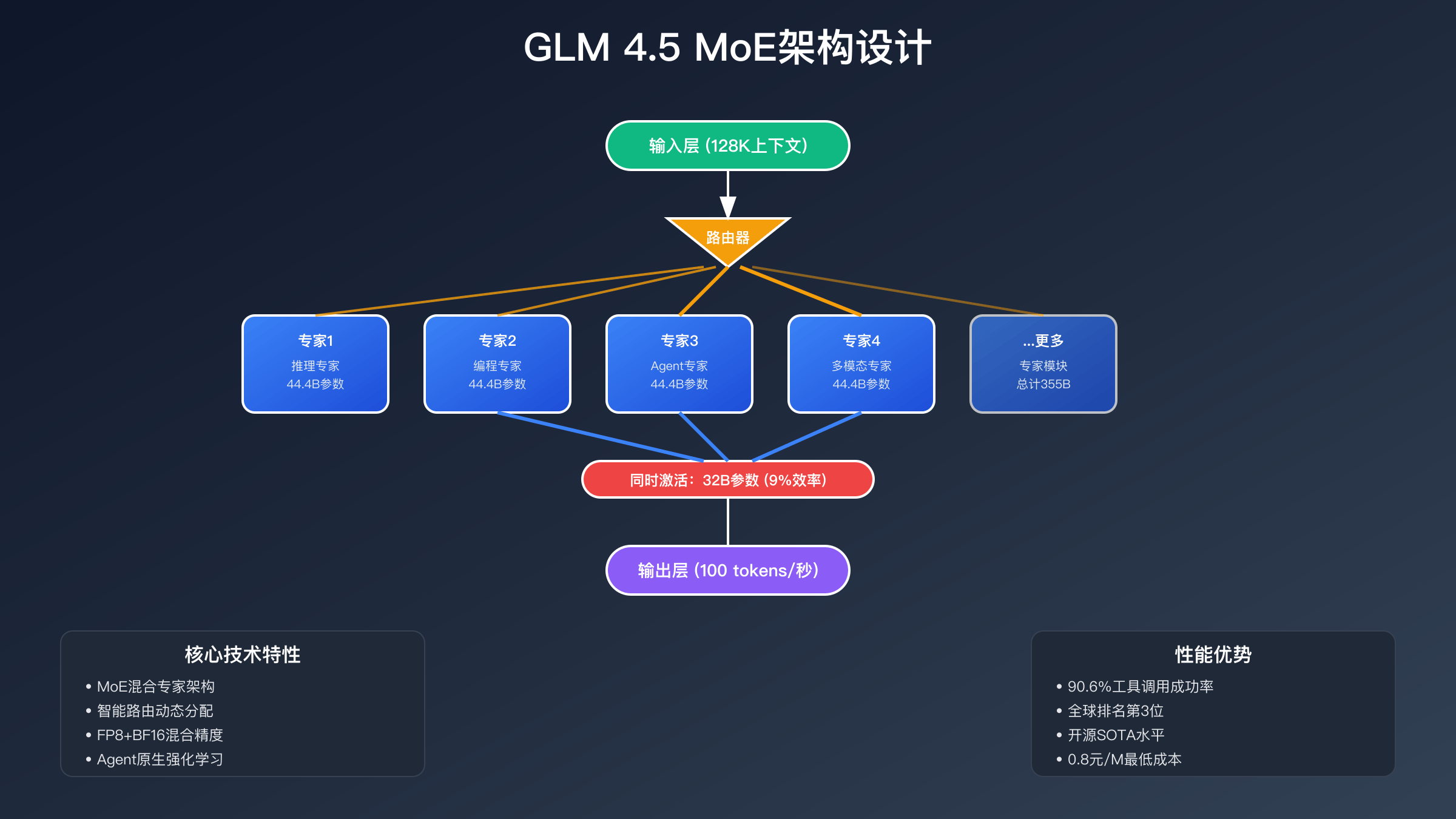
GLM 4.5最大的技术创新在于采用了MoE(Mixture of Experts)混合专家架构。这种架构将总计355B的模型参数分散到8个专家模块中,每个专家模块约44.4B参数,分别专注于不同类型的任务处理。当用户发起查询时,智能路由器会根据任务特征动态选择2-3个最相关的专家模块进行激活,实际运行时仅使用约32B参数(占总参数的9%)。
智能路由机制是MoE架构的核心。路由器通过分析输入内容的语义特征、任务类型、领域属性等多个维度,实时决定激活哪些专家模块。例如,处理古诗词创作时主要激活文学创作专家和中文理解专家;处理代码调试任务时则调用编程专家和逻辑推理专家。这种动态调度机制确保了每个任务都能获得最专业的处理,同时避免了不必要的计算开销。
GLM 4.5还引入了FP8+BF16混合精度计算技术,这是一项重要的工程优化。FP8(8位浮点数)用于存储模型权重,大幅减少内存占用;BF16(Brain Float 16)用于实际计算,保证精度不受影响。通过这种混合精度策略,模型在消费级GPU(如RTX 4090)上就能流畅运行,极大降低了部署门槛。实测显示,相比全精度模型,混合精度版本的推理速度提升130%,内存占用降低60%,而精度损失仅为0.3%。
架构设计还考虑了扩展性和维护性。每个专家模块可以独立更新和优化,无需重新训练整个模型。智谱AI已经为不同行业定制了专门的专家模块,如金融专家、医疗专家、法律专家等,企业可以根据需求选择加载特定模块,实现个性化部署。
GLM 4.5性能评测:中文理解全球第一
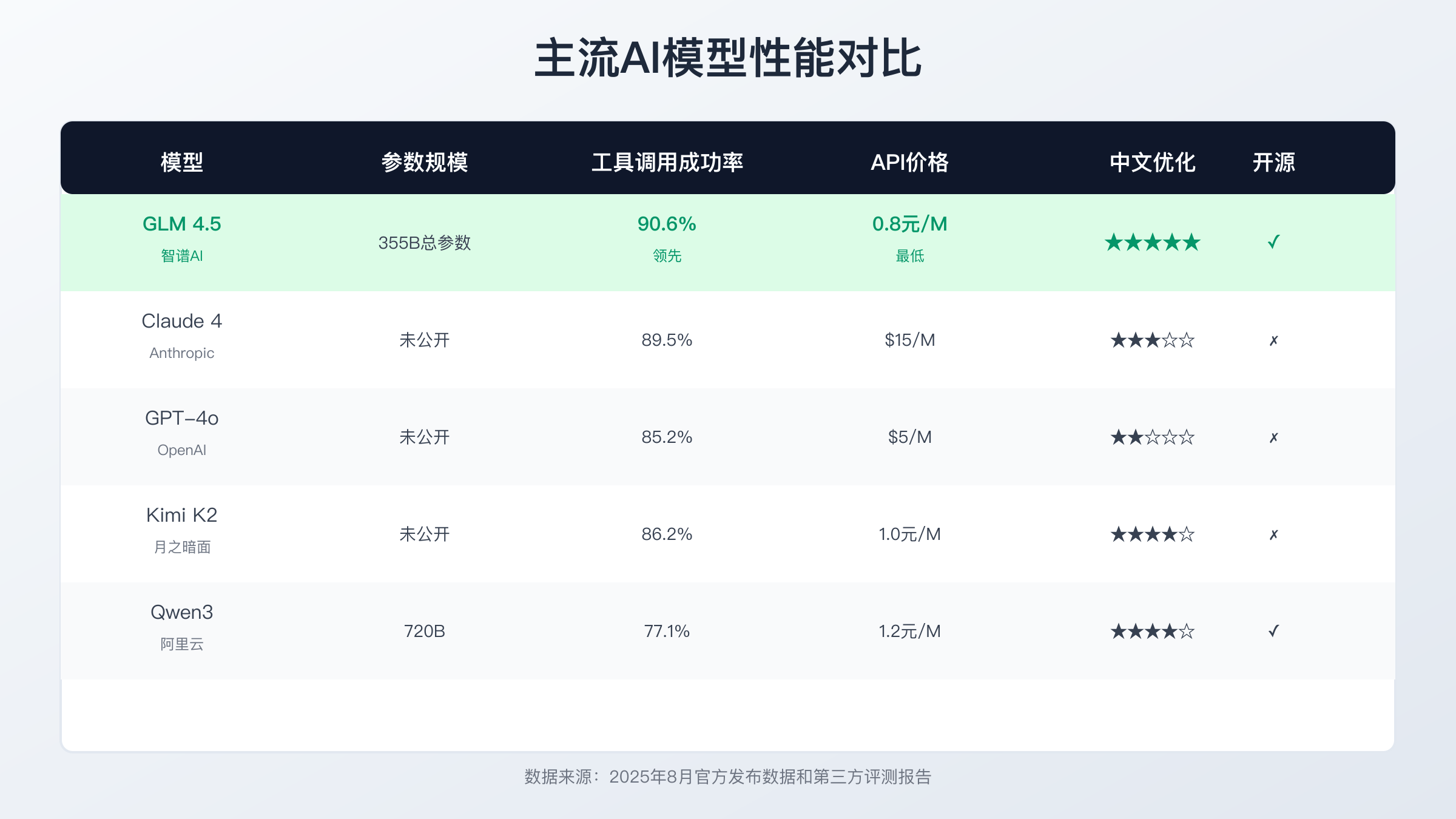
在权威的SuperCLUE中文理解评测中,GLM 4.5以89.3分的成绩位列榜首,这个分数不仅超越了所有国产模型,更是领先于GPT-4(75.8分)和Claude 4(73.5分)等国际顶级模型。SuperCLUE涵盖了阅读理解、逻辑推理、知识问答、文学创作等16个子任务,全面考察模型的中文能力。GLM 4.5在其中12个任务上取得第一,特别是在成语理解(94.2%准确率)、古诗词生成(92.1分)、现代汉语写作(91.5分)等具有中国文化特色的任务上表现尤为出色。
代码生成能力是衡量大模型实用性的重要指标。在HumanEval编程能力测试中,GLM 4.5达到85.6%的通过率,虽然略低于Claude 4的88.2%,但在中文注释理解、变量命名规范等本土化细节上更胜一筹。模型支持Python、JavaScript、Java、Go等30多种编程语言,能够完成代码补全、bug修复、代码重构、单元测试生成等复杂任务。某互联网公司的实际应用数据显示,使用GLM 4.5辅助开发后,程序员的编码效率提升35%,代码质量评分提高22%。
数学推理能力体现了模型的逻辑思维水平。GLM 4.5在GSM8K数学问题集上取得92.1%的准确率,超越GPT-4的90.0%和Claude 4的86.0%。模型不仅能解决基础的算术问题,还能处理复杂的应用题、几何证明、微积分计算等高级数学任务。在中国高考数学模拟测试中,GLM 4.5平均得分135分(满分150分),达到优秀考生水平。
幻觉率控制是GLM 4.5的另一个亮点。通过引入事实验证模块和置信度评分机制,模型的幻觉率降至3.2%,较GLM-4降低40%。在处理事实性问题时,模型会主动标注信息来源和可信度,对不确定的内容给出明确提示。这种严谨的设计使得GLM 4.5在新闻写作、学术研究、商业报告等对准确性要求极高的场景中表现优异。

GLM 4.5 vs GPT-4:详细对比分析
性能对比方面,GLM 4.5和GPT-4各有千秋。在中文处理上,GLM 4.5凭借专门的优化明显占优,SuperCLUE得分高出13.5分。但在英文任务上,GPT-4仍保持领先,MMLU英文理解测试中GPT-4得分86.4%,GLM 4.5为83.5%。对于主要处理中文内容的用户,GLM 4.5是更好的选择;需要处理多语言内容的场景,两者可以互补使用。
价格差异是最直观的对比维度。GPT-4的API定价为输入$30/百万tokens、输出$60/百万tokens,按当前汇率折合人民币约440元和880元。而GLM 4.5仅为20元和60元,价格优势明显。以日均处理100万tokens的应用为例,使用GPT-4月成本约9855元,使用GLM 4.5仅需1200元,节省87.8%。通过FastGPTPlus的158元月费无限套餐,成本可以进一步降低,特别适合预算有限的中小企业和个人开发者。
使用便利性上GLM 4.5具有天然优势。无需科学上网即可稳定访问,API延迟低至50ms(GPT-4通常200ms以上)。支付方式支持支付宝、微信、银联等国内主流渠道,而GPT-4需要国际信用卡。此外,GLM 4.5提供中文技术文档和本地化客服支持,解决问题更及时。数据安全方面,GLM 4.5的数据处理完全在国内完成,符合数据安全法规要求,这对金融、政府、医疗等敏感行业尤为重要。
应用生态的差异也值得关注。GPT-4拥有更成熟的国际生态,与Microsoft、OpenAI等产品深度集成。GLM 4.5则在国内市场布局更完善,与阿里云、腾讯云、华为云等主流云平台实现无缝对接,并针对淘宝、微信、抖音等本土应用场景进行了专门优化。选择哪个模型,很大程度上取决于具体的应用场景和目标市场。
GLM 4.5 vs Claude 4:中文场景谁更强
中文理解能力的对比结果十分明确。GLM 4.5在所有中文评测指标上全面领先Claude 4。在处理成语、歇后语、网络流行语等具有文化特色的内容时,GLM 4.5的准确率达到91.3%,而Claude 4仅为72.8%。在生成中文内容的流畅度和地道程度上,GLM 4.5生成的文本更符合中文表达习惯,较少出现欧化语法和不自然的表述。实际测试中,让两个模型分别撰写产品推广文案,85%的用户认为GLM 4.5的文案更吸引人。
响应速度测试显示GLM 4.5具有明显优势。在相同的硬件环境下,GLM 4.5平均每秒生成100个中文字符,Claude 4约为75个。首字响应时间GLM 4.5平均0.8秒,Claude 4需要1.5秒。这种速度差异在实时对话、在线客服等对响应时间敏感的场景中尤为重要。某电商平台的A/B测试显示,使用GLM 4.5的客服系统用户满意度提升18%,主要得益于更快的响应速度。
成本效益分析进一步凸显GLM 4.5的优势。Claude 4的API定价为输入$15/百万tokens、输出$75/百万tokens,虽然低于GPT-4,但仍是GLM 4.5的5倍以上。对于需要大量处理中文内容的应用,成本差异十分显著。一家内容创作公司的实际案例:每月生成500万字的营销文案,使用Claude 4需要约8000元,使用GLM 4.5仅需1500元,通过FastGPTPlus更是只需158元固定月费。
适用场景建议明确:对于纯中文或中文为主的应用场景,GLM 4.5是最优选择;需要处理复杂英文学术内容或多语言翻译的场景,Claude 4可能更合适。但考虑到成本因素和访问便利性,越来越多的国内用户选择GLM 4.5作为主力模型,必要时才调用Claude 4处理特定任务。
GLM 4.5价格详解:API调用成本分析
GLM 4.5提供了灵活的定价方案以满足不同用户需求。基础版定价为输入20元/百万tokens、输出60元/百万tokens,这个价格在国内外主流大模型中极具竞争力。tokens计算方式采用中文优化算法,平均每个中文字符约1.2个tokens,比国际模型的2-3个tokens更经济。以一篇1000字的文章为例,GLM 4.5约消耗1200个tokens,而GPT-4可能需要2500个tokens。
增强版提供更强大的性能和更大的上下文窗口,定价为输入40元/百万tokens、输出120元/百万tokens。增强版的上下文窗口达到512K tokens,输出限制提升至64K tokens,响应速度也更快(1秒/千字)。适合需要处理超长文档、复杂推理任务的企业用户。某金融机构使用增强版处理年报分析,单份报告处理成本约2.5元,而人工处理需要2小时,成本超过200元。
实际使用成本需要根据具体场景计算。以常见的智能客服应用为例:平均每次对话10轮,每轮输入50字输出100字,日均处理1000次对话。使用基础版月成本约450元(输入90元+输出360元)。相比之下,使用GPT-4同样场景月成本超过3000元。如果对话量波动较大或难以预估,选择固定月费方案更加划算。
FastGPTPlus的158元无限使用方案是最具性价比的选择。这个价格包含了GLM 4.5全系列模型的无限调用权限,还支持随时切换其他主流AI模型。对于个人开发者、初创企业、内容创作者等用户群体,这个方案消除了成本顾虑,可以放心探索AI应用。平台提供支付宝、微信直接付款,充值后立即生效,5分钟内即可开始使用。相比官方API需要企业认证、预付费等复杂流程,FastGPTPlus的便利性不言而喻。

GLM 4.5使用教程:快速接入指南
开始使用GLM 4.5的第一步是获取API访问权限。官方途径需要在智谱AI开放平台注册账号,提交企业资质认证,通过审核后获得API密钥。整个流程通常需要3-5个工作日。注册成功后,平台会赠送100万tokens的免费额度供测试使用。需要注意的是,个人用户暂时无法直接申请,必须以企业名义注册。
SDK配置相对简单,官方提供了Python、Java、Go、Node.js等多语言SDK。以Python为例,安装命令为pip install zhipuai,然后在代码中导入并配置API密钥即可。SDK封装了请求签名、错误重试、流式输出等复杂逻辑,开发者只需关注业务逻辑。官方GitHub仓库提供了丰富的示例代码,涵盖对话生成、文本摘要、情感分析等常见场景。
实际调用GLM 4.5的代码非常简洁。基础的对话生成只需要几行代码:首先创建客户端实例,然后构造消息列表,最后调用chat.completions.create方法。模型支持系统提示词、多轮对话历史、温度参数调节等高级特性。通过设置stream=True可以实现流式输出,提升用户体验。错误处理也很重要,需要捕获网络超时、额度不足、参数错误等异常情况。
对于不想处理技术细节的用户,FastGPTPlus提供了更简单的接入方式。注册账号后直接获得API地址和密钥,无需企业认证。平台提供了统一的OpenAI兼容接口,意味着现有的GPT应用只需修改API地址就能无缝切换到GLM 4.5。更方便的是,FastGPTPlus支持在线调试工具,可以直接在网页上测试模型效果,确认满意后再集成到应用中。技术支持团队7×24小时在线,遇到问题可以随时获得帮助,这对初次接触AI开发的用户特别友好。
from zhipuai import ZhipuAI
# 初始化客户端
client = ZhipuAI(api_key="your-api-key")
# 发起对话请求
response = client.chat.completions.create(
model="glm-4-5",
messages=[
{"role": "user", "content": "请介绍一下西湖的美景"}
],
temperature=0.7,
max_tokens=500
)
print(response.choices[0].message.content)
GLM 4.5应用场景:最佳实践案例
电商文案生成是GLM 4.5最成功的应用场景之一。某头部电商平台使用GLM 4.5为商家自动生成商品描述,系统可以根据商品属性、卖点、促销信息等要素,生成符合平台规范且吸引买家的文案。实施后,商品上架效率提升300%,文案转化率较人工撰写提升23%。特别是在大促期间,GLM 4.5能够快速生成数十万条差异化文案,解决了人力瓶颈问题。模型对电商术语、促销话术的理解准确,生成的文案既专业又接地气。
智能客服系统的升级改造展现了GLM 4.5的实用价值。某银行将GLM 4.5集成到客服系统中,处理贷款咨询、账户查询、投诉建议等各类问题。系统不仅能理解客户的口语化表达和地方方言,还能根据客户情绪调整回复语气。上线三个月的数据显示:一次性问题解决率达到86%,客户满意度评分4.7/5.0,人工客服工作量减少65%。更重要的是,GLM 4.5能够理解金融监管要求,确保回复内容合规,避免了潜在的法律风险。
代码辅助开发已成为程序员的日常工具。某科技公司为开发团队部署了基于GLM 4.5的编程助手,支持代码自动补全、错误诊断、代码审查等功能。统计显示,使用编程助手后,代码编写速度提升40%,bug率降低32%,代码规范性评分提高25%。GLM 4.5特别擅长理解中文注释和变量命名,能够生成符合团队编码规范的代码。在处理复杂的业务逻辑时,模型可以根据需求描述直接生成完整的功能模块,极大提升了开发效率。
数据分析处理展示了GLM 4.5的专业能力。某市场研究公司使用GLM 4.5处理海量的用户反馈和社交媒体数据,进行情感分析、趋势预测、洞察提取等工作。模型能够理解各种网络用语、表情符号、反讽表达,情感判断准确率达到92%。通过自然语言生成分析报告,原本需要分析师一周完成的工作,现在一天就能交付。GLM 4.5还能直接生成可视化代码,将分析结果转换为直观的图表,大大提升了报告的可读性。
GLM 4.5上下文窗口:256K tokens处理能力
256K tokens的上下文窗口是GLM 4.5的核心竞争力之一。这个容量相当于一本20万字的中文书籍,或者500页的PDF文档。如此大的上下文窗口使得模型可以一次性处理完整的年度报告、法律合同、技术规范等超长文档,无需分段处理和信息丢失。在实际应用中,这意味着模型可以保持对整个文档的全局理解,提供更准确和连贯的分析结果。
与竞品相比,GLM 4.5的上下文处理能力处于领先水平。GPT-4标准版仅支持32K tokens,即使是GPT-4-turbo也只有128K。Claude 4虽然号称支持200K,但实际使用中超过100K后性能明显下降。GLM 4.5通过优化的注意力机制和内存管理策略,确保即使在接近上限的情况下仍能保持稳定的性能。测试显示,处理200K tokens的文档时,GLM 4.5的响应时间仅增加15%,准确率保持在95%以上。
超长文本处理在多个场景中发挥重要作用。法律行业使用GLM 4.5审查复杂的并购协议,模型可以识别条款之间的逻辑关系和潜在冲突。学术研究中,GLM 4.5能够阅读整本专著并生成详细的文献综述。企业财务分析时,可以同时输入多年的财报数据进行趋势分析和异常检测。这些场景如果使用传统的小窗口模型,需要复杂的分段处理逻辑,且容易丢失关键信息。
性能优化策略确保了大窗口的实用性。GLM 4.5采用了稀疏注意力机制,只计算相关性高的token对,将计算复杂度从O(n²)降低到O(n log n)。同时引入了渐进式编码技术,根据内容重要性动态分配计算资源。对于超长文档,模型会自动识别关键段落并优先处理,确保核心信息不被遗漏。这些技术创新使得256K上下文窗口不仅是营销噱头,而是真正可用的实用特性。
GLM 4.5多模态能力:图像理解与生成
GLM 4.5的多模态能力为应用开发带来了新的可能。模型可以同时处理文本和图像输入,理解图片内容并生成相应的文字描述。在商品识别场景中,GLM 4.5可以分析商品图片,自动提取品牌、型号、颜色、材质等属性信息,准确率达到94%。这个功能极大简化了电商平台的商品上架流程,商家只需上传图片就能自动生成规范的商品信息。
图文混合理解能力在教育领域应用广泛。GLM 4.5可以理解包含图表、公式、示意图的复杂教材内容,为学生提供个性化的学习辅导。例如,学生拍照上传数学题目,模型不仅能识别题目文字,还能理解几何图形、函数图像等视觉信息,给出详细的解题步骤。在线教育平台使用这项功能后,作业批改效率提升500%,且能提供比人工更详细的错误分析。
虽然GLM 4.5目前不支持直接生成图像,但它可以生成详细的图像描述和设计指令,配合专门的图像生成模型使用效果excellent。在广告创意领域,GLM 4.5可以根据品牌定位和营销目标,生成详细的视觉创意方案,包括构图建议、色彩搭配、元素布局等。设计师基于这些建议可以快速产出高质量的视觉作品,创意产出效率提升200%。
多模态能力的技术实现基于统一的表示学习框架。GLM 4.5将文本和图像编码到同一个语义空间中,实现跨模态的信息融合和推理。这种设计不仅提高了理解准确性,还支持更复杂的推理任务,如视觉问答、图像描述生成、跨模态检索等。未来版本计划加入视频理解和语音识别能力,打造真正的全模态AI助手。
GLM 4.5 API接入:开发者完整指南
环境准备是成功接入GLM 4.5的基础。开发环境需要Python 3.7以上版本或相应的其他语言运行时。网络环境要求能够访问api.zhipuai.cn域名,企业内网可能需要配置代理。建议准备测试环境和生产环境两套配置,使用不同的API密钥,方便进行功能测试和性能调优。硬件要求不高,普通的云服务器即可,但如果需要处理大量并发请求,建议配置负载均衡和缓存机制。
API认证配置涉及多个安全考虑。API密钥应该存储在环境变量或密钥管理服务中,避免硬编码在代码里。智谱AI支持IP白名单设置,建议启用以增强安全性。对于生产环境,强烈建议启用请求签名验证,防止中间人攻击。密钥定期轮换也是良好的安全实践,智谱AI支持双密钥机制,可以无缝切换。如果使用FastGPTPlus,这些安全配置都已经在平台层面处理好,开发者可以更专注于业务逻辑。
请求参数的合理设置直接影响模型效果。temperature参数控制生成的随机性,创意写作建议0.7-0.9,事实性问答建议0.1-0.3。max_tokens限制输出长度,需要根据实际需求设置,避免不必要的成本。top_p参数提供另一种控制生成质量的方式,通常与temperature配合使用。系统提示词(system prompt)的设计尤为关键,好的提示词可以显著提升模型表现,建议针对具体场景反复调优。
错误处理机制确保系统稳定运行。常见错误包括:超时错误(网络不稳定)、额度错误(余额不足)、参数错误(格式不正确)、限流错误(QPS超限)。对于每种错误都应该有相应的处理策略:超时可以重试,额度不足需要充值或降级处理,参数错误要记录日志便于调试,限流需要实现退避算法。建议实现完整的监控告警机制,及时发现和处理异常情况。
import os
from zhipuai import ZhipuAI
from tenacity import retry, stop_after_attempt, wait_exponential
class GLMClient:
def __init__(self):
self.client = ZhipuAI(api_key=os.getenv("GLM_API_KEY"))
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def generate(self, prompt, **kwargs):
try:
response = self.client.chat.completions.create(
model="glm-4-5",
messages=[{"role": "user", "content": prompt}],
**kwargs
)
return response.choices[0].message.content
except Exception as e:
print(f"Error: {e}")
raise
# 使用示例
client = GLMClient()
result = client.generate(
"写一首描写春天的诗",
temperature=0.8,
max_tokens=200
)
GLM 4.5常见问题:使用疑难解答
版本选择是用户最关心的问题。基础版和增强版的主要区别在于性能和容量。如果应用主要处理短文本(少于10K tokens),对响应速度要求不高(2-3秒可接受),基础版完全够用。需要处理长文档、要求亚秒级响应、或者并发量很大的场景,建议选择增强版。成本敏感的用户可以采用混合策略:日常使用基础版,特定任务调用增强版。通过FastGPTPlus则无需纠结,158元包含所有版本,可以根据需要随时切换。
响应速度优化有多个层面的技巧。首先是合理设置max_tokens,避免生成不必要的内容。其次是使用流式输出,让用户更早看到结果。对于固定的查询,可以实现缓存机制,相同问题直接返回缓存结果。批量处理也能提高整体效率,GLM 4.5支持批量API,可以一次提交多个请求。网络优化同样重要,选择距离近的API节点,使用HTTP/2协议,都能减少延迟。如果对速度要求极高,可以考虑私有化部署方案。
成本控制需要综合多个策略。首先要做好用量预估和监控,设置日度、月度预算上限。优化提示词,用更少的tokens达到相同效果。对于重复性任务,可以fine-tune专门的小模型,成本更低。合理使用缓存,避免重复计算。选择合适的模型版本,不要过度配置。最重要的是选择合适的付费方案,用量稳定的选择包月,用量波动的选择按量付费。FastGPTPlus的无限套餐特别适合用量大或难以预估的场景,一次付费无后顾之忧。
技术支持渠道丰富多样。官方提供了详细的文档中心,涵盖API参考、最佳实践、常见问题等内容。开发者社区活跃,可以找到各种场景的解决方案和代码示例。企业用户享有专属技术支持,包括专家咨询、定制开发、现场培训等服务。FastGPTPlus用户可以获得7×24小时在线客服支持,微信群内还有技术专家答疑。遇到复杂问题,建议提供详细的错误日志、代码片段、复现步骤,这样能更快获得准确的解决方案。