GPT-4o图像生成API全解析:最新进展、功能与使用指南(2025年4月更新)
GPT-4o作为OpenAI最新推出的多模态大模型,其强大的图像生成能力震撼了整个AI界。本文将深入解析GPT-4o图像生成API的最新进展、功能特点、应用场景,并提供详细的接入指南和最佳实践,帮助开发者快速掌握这一革命性技术。根据最新信息,OpenAI已宣布将在未来几周内逐步向开发者开放GPT-4o图像生成API的访问权限。
一、GPT-4o图像生成API最新进展
根据OpenAI社区最新讨论和官方公告,GPT-4o图像生成API的发布正在积极筹备中。以下是当前的进展情况:
- 发布时间表:OpenAI官方宣布将在”未来几周内”向开发者逐步开放GPT-4o图像生成API
- 功能范围:预计支持文本到图像(text-to-image)生成,有可能包括图像到图像(image-to-image)和对话式图像编辑功能
- 访问方式:目前API尚未正式发布,但预计将通过现有的OpenAI API平台提供访问
- 价格模型:虽然具体定价尚未公布,但社区讨论预测可能采用类似于音频token的高密度定价模式
截至2025年4月中旬,OpenAI尚未发布具体的API上线日期,但开发者社区的兴趣持续高涨。最新的OpenAI API直播活动也未透露具体发布日期,建议开发者持续关注OpenAI的更新日志获取最新信息。
二、GPT-4o图像生成技术解析
GPT-4o的图像生成能力代表了AI视觉创作的新高度,与DALL-E 3和其他主流图像生成模型相比具有显著优势:
1. 关键技术特点
- 多模态上下文理解:与仅接受文本提示的DALL-E 3不同,GPT-4o能够理解完整的对话上下文,创建更符合用户意图的图像
- 详细程度与真实感:生成的图像细节更丰富,真实感更强,特别是在人物表情、复杂场景和文字渲染方面表现出色
- 创意理解能力:能更准确理解抽象概念和创意需求,减少对提示工程的依赖
- 一致性维持:在多轮对话中能保持场景、角色和风格的一致性,适合连续创作场景
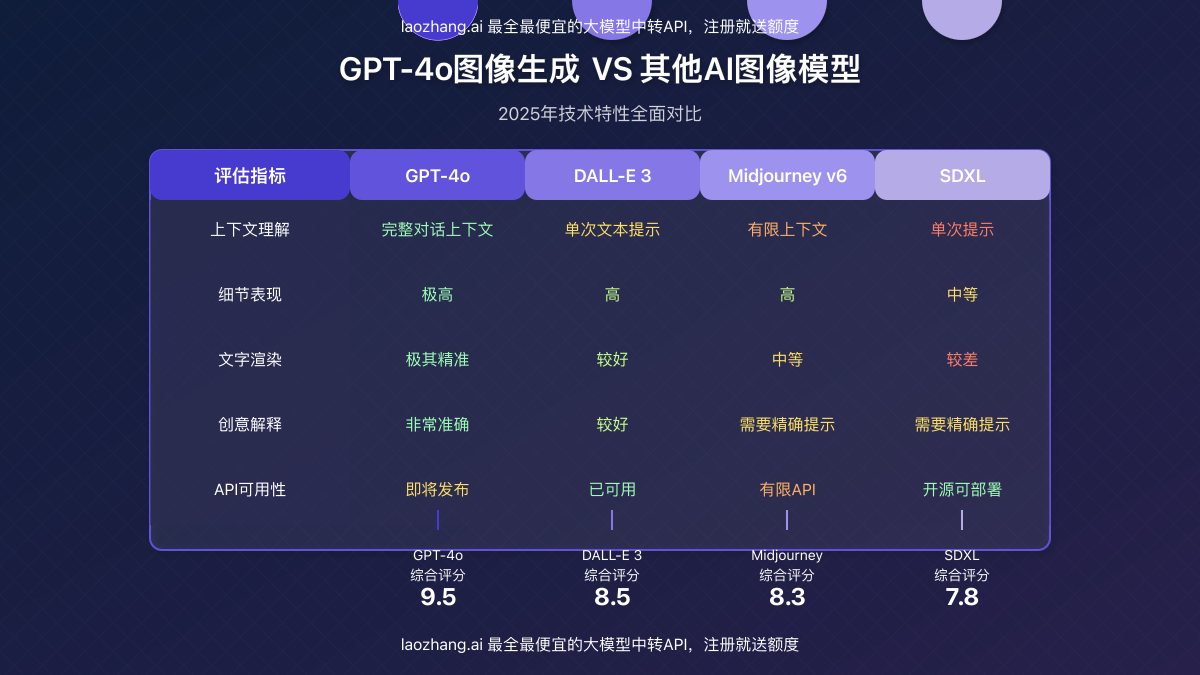
2. 与DALL-E 3及其他模型的对比
| 功能特性 | GPT-4o | DALL-E 3 | Midjourney v6 | SDXL |
|---|---|---|---|---|
| 上下文理解 | 完整对话上下文 | 单次文本提示 | 有限上下文 | 单次提示 |
| 细节表现 | 极高 | 高 | 高 | 中等 |
| 文字渲染 | 极其精准 | 较好 | 中等 | 较差 |
| 创意解释 | 非常准确 | 较好 | 需要精确提示 | 需要精确提示 |
| API可用性 | 即将发布 | 已可用 | 有限API | 开源可部署 |
3. 性能与限制
根据社区用户体验报告,GPT-4o图像生成在ChatGPT中表现出以下性能特点:
- 生成速度:单张图像生成时间约3-5秒,明显快于DALL-E 3的10-15秒
- 上下文容量:虽然能够理解对话上下文,但上下文窗口可能有所限制,不如GPT-4的主文本上下文容量大
- 连续生成能力:支持连续生成相关图像,保持场景和人物一致性
- 当前限制:仅支持英文提示效果最佳;部分复杂场景仍有改进空间;具体API限制尚未公布
注意:由于GPT-4o图像生成API尚未正式发布,上述性能分析基于ChatGPT界面的用户体验报告,实际API性能可能有所不同。
三、GPT-4o图像生成API应用场景
GPT-4o的图像生成API一旦发布,将为众多行业和应用场景带来革命性变革。以下是几个主要的潜在应用领域:
1. 内容创作与媒体
- 实时内容插图:为博客、新闻和社交媒体内容快速生成定制插图
- 视频脚本可视化:将视频创意和脚本快速转换为预览图或分镜脚本
- 广告素材批量生成:根据产品描述自动生成多样化的广告创意和素材
- 电子书和教材插图:为教育内容生成精准的概念图和教学插图
2. 产品设计与电商
- 产品概念可视化:将产品创意快速转换为视觉呈现,加速设计迭代
- 电商产品展示:生成不同场景、角度的产品展示图,增强购物体验
- 包装设计方案:基于产品描述提供多样化的包装设计概念
- 室内设计可视化:将空间设计理念转化为视觉效果图
3. 交互式应用
- 智能图像聊天机器人:创建能够理解并生成图像内容的交互式助手
- 教育辅助工具:根据学生需求生成定制化教学插图和视觉解释
- 游戏资产生成:快速创建游戏原型、角色设计和场景概念图
- 创意协作平台:多人协作环境中实时可视化创意和想法
行业洞察:与DALL-E 3等纯图像生成API相比,GPT-4o图像生成API的最大优势在于其对上下文的深入理解,这使得创建连贯一致的视觉叙事变得可能,特别适合需要多轮交互的应用场景。
四、GPT-4o图像API接入指南
虽然OpenAI尚未正式发布GPT-4o图像生成API,但基于现有的ChatGPT界面实现和OpenAI API的一般模式,我们可以预测其可能的接入方式。以下是接入准备和预期使用方法:
1. 接入准备
- OpenAI API密钥:确保您已注册OpenAI开发者账户并获取API密钥
- API额度管理:预期GPT-4o图像生成将消耗较多的API额度,做好预算规划
- 技术栈准备:熟悉RESTful API调用、JSON处理和图像处理库
- 内容政策合规:了解OpenAI的使用政策,确保应用符合内容安全要求
推荐中转服务:laozhang.ai
对于国内开发者,可以通过laozhang.ai提供的中转API服务接入GPT-4o图像生成功能,该服务具有以下优势:
- 稳定可靠的API中转,解决国内访问限制问题
- 更灵活的计费模式,注册即送免费额度
- 完全兼容OpenAI原生API格式,无需修改代码
- 提供技术支持和使用指导,降低接入门槛
注册地址:https://api.laozhang.ai/register/?aff_code=JnIT
技术咨询微信:ghj930213
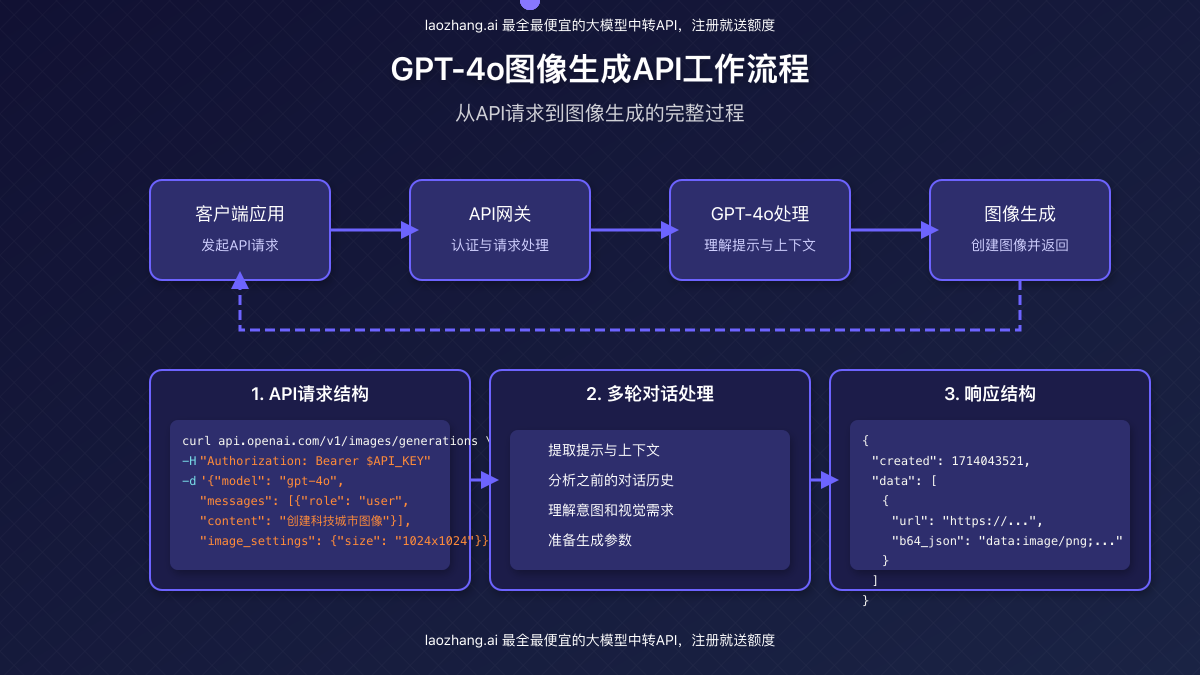
2. 预期API结构
基于OpenAI现有API模式和社区讨论,GPT-4o图像生成API可能的调用结构如下:
curl https://api.openai.com/v1/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个专业的图像生成助手。"},
{"role": "user", "content": "创建一幅科技感十足的智能城市夜景图。"}
],
"max_tokens": 4096,
"temperature": 0.7,
"image_settings": {
"size": "1024x1024",
"format": "png",
"quality": "standard"
}
}'通过laozhang.ai中转服务的调用方式几乎完全相同,只需更改API端点:
curl https://api.laozhang.ai/v1/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个专业的图像生成助手。"},
{"role": "user", "content": "创建一幅科技感十足的智能城市夜景图。"}
],
"max_tokens": 4096,
"temperature": 0.7,
"image_settings": {
"size": "1024x1024",
"format": "png",
"quality": "standard"
}
}'注意:上述API结构仅为预测,实际发布的API可能在参数和结构上有所不同。OpenAI发布官方文档后应以官方文档为准。
3. 预期功能参数
基于OpenAI现有API和GPT-4o在ChatGPT中的表现,我们可以预期以下功能参数:
- 图像尺寸选项:可能支持多种尺寸比例,如正方形(1024×1024)、横向(1792×1024)和纵向(1024×1792)
- 风格控制参数:可能提供风格引导功能,如写实、卡通、油画等
- 上下文数量限制:可能限制单次请求中的消息数量或总token数
- 图像质量设置:标准质量和高质量选项,影响生成时间和API额度消耗
- 多图生成:同一提示生成多个变体的能力
4. 错误处理与最佳实践
在实际应用中,建议遵循以下最佳实践:
- 实现重试机制:处理临时错误和速率限制,使用指数退避策略
- 提示词优化:提供详细、结构化的提示,特别是对于复杂场景
- 上下文管理:精简历史消息,只保留必要的上下文信息
- 并发控制:管理并发请求数量,避免触发API限制
- 结果缓存:缓存常用图像生成结果,减少重复请求
Node.js示例代码
// 使用OpenAI npm包调用GPT-4o图像生成API
const { OpenAI } = require('openai');
// 初始化OpenAI客户端
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: 'https://api.laozhang.ai/v1', // 使用laozhang.ai中转服务
});
async function generateImage(prompt) {
try {
const response = await openai.images.generate({
model: 'gpt-4o',
messages: [
{ role: 'system', content: '你是一个专业的图像生成助手。' },
{ role: 'user', content: prompt }
],
max_tokens: 4096,
image_settings: {
size: '1024x1024',
format: 'png'
}
});
return response.data;
} catch (error) {
console.error('图像生成失败:', error);
throw error;
}
}
// 调用示例
generateImage('创建一幅未来城市场景,有飞行汽车和全息广告')
.then(imageData => console.log('生成的图片URL:', imageData.url))
.catch(err => console.error('错误:', err));五、实际应用案例与效果展示
虽然GPT-4o图像生成API尚未正式发布,但通过ChatGPT界面已有不少用户展示了其强大的图像生成能力。以下是几个典型应用场景的效果展示:
1. 产品设计概念可视化
一位产品设计师通过对话式交互,逐步细化和完善一款智能家居设备的设计概念:
初始提示:设计一款未来风格的智能语音助手设备,适合放在客厅。
后续细化:增加环形触控屏,顶部有呼吸灯,整体采用哑光白色。
进一步调整:展示它在现代简约风格客厅的使用场景,显示它正在播放音乐。
→ GPT-4o能够在每一轮对话中保持设计元素的一致性,同时整合新的需求。
2. 教育内容图解生成
一位教育工作者使用GPT-4o为复杂的科学概念创建易于理解的图解:
初始提示:创建一张介绍光合作用过程的图解,适合高中生理解。
后续细化:在图中标注关键分子名称,使用明亮的色彩区分明暗反应。
进一步调整:添加箭头显示能量流动,在旁边增加简短文字说明。
→ 最终生成的图解准确反映了科学概念,同时保持视觉吸引力和教育价值。
3. 多轮场景构建
一位故事创作者通过连续对话构建了一个奇幻世界的视觉形象:
初始提示:绘制一座建在巨大树上的精灵城市,有螺旋式的楼梯和发光的灯笼。
后续细化:展示城市中心的市集,有各种精灵在交易魔法物品。
角色添加:展示一位戴着花冠、穿绿色长袍的精灵女王站在高处俯瞰市集。
天气变化:现在让场景变成黄昏时分,天空呈现紫红色,灯笼开始发光。
→ GPT-4o展示了出色的场景连贯性和要素记忆能力,每一轮都保持了前序元素。
六、常见问题与解答
Q1: GPT-4o图像生成API的预计价格是多少?
OpenAI尚未公布具体定价。根据社区讨论,预计GPT-4o图像生成API的价格可能高于文本服务,类似于音频处理的高密度token定价模式。一种可能的情况是采用”每次生成”计费,而非基于token数量。通过laozhang.ai等中转服务可能获得更灵活的定价选择。
Q2: GPT-4o图像生成API与DALL-E 3 API有什么区别?
主要区别在于上下文理解能力。GPT-4o能够理解完整的对话历史,实现连续交互和图像迭代优化;而DALL-E 3每次生成都是独立的,不保留历史上下文。此外,GPT-4o在文字渲染、复杂场景表现和创意理解方面普遍优于DALL-E 3。
Q3: 使用中转服务如laozhang.ai是否会影响API性能?
专业的中转服务通常对性能影响极小,laozhang.ai等服务采用高速网络和优化的代理技术,通常只增加几十毫秒的延迟。考虑到图像生成本身需要数秒时间,这一延迟几乎不会被感知。对于国内用户,中转服务实际上可能提供比直接访问更稳定的连接。
Q4: GPT-4o图像生成API是否支持图像编辑功能?
基于社区讨论,GPT-4o在ChatGPT中已展示了一定的图像编辑能力,能够基于上下文理解修改已生成的图像。但尚不清楚API版本是否会完整支持此功能,还是类似DALL-E 3只支持生成而不支持编辑。目前为止,DALL-E 2是唯一在API中支持图像编辑的OpenAI模型。
Q5: 如何优化GPT-4o图像生成的提示词?
与DALL-E 3相比,GPT-4o对提示词的依赖较小,能更好地理解自然语言请求。最佳实践包括:(1)清晰描述主体和场景;(2)指定想要的艺术风格;(3)提供关键细节;(4)在多轮对话中逐步细化;(5)使用明确的视觉参考。与普通提示词不同,GPT-4o能够从上下文中累积理解,无需在每次请求中重复所有细节。
Q6: GPT-4o图像生成API有哪些内容限制?
预计GPT-4o图像生成API将延续OpenAI现有的内容政策,包括禁止生成暴力、仇恨、成人内容、名人肖像、著作权材料等。同时,GPT-4o的安全措施进一步强化,对有害请求的拒绝率更高,内容过滤更严格。企业开发者可能需要申请内容审核调整以适应特定应用场景。
七、结论与展望
GPT-4o图像生成API的即将发布标志着AI图像生成技术进入了一个新阶段。其强大的上下文理解能力、卓越的细节表现和自然的交互方式,将为开发者提供前所未有的创意表达工具。
关键优势总结
- 多轮对话式图像创作,保持视觉元素的连贯性和一致性
- 卓越的文字渲染和复杂场景表现能力
- 更自然的提示词理解,降低提示工程难度
- 更快的生成速度,提升用户体验
- 与现有OpenAI生态系统的无缝集成
未来展望
随着GPT-4o图像生成API的正式发布,我们可以期待以下发展趋势:
- 多模态应用的爆发性增长,将文本、图像、视频融为一体
- 创意行业工作流程的深度变革,从构思到实现的时间大幅缩短
- 个性化视觉内容的普及,满足用户定制化需求
- API功能的持续迭代,可能加入更多媒体类型如动态图像
- 社区开发的工具和框架生态系统的形成
对于希望抢先体验这一技术的开发者,我们推荐通过laozhang.ai等专业中转服务提前做好技术准备。这些服务不仅能在API正式发布后提供稳定可靠的访问通道,还能通过技术支持和优化的计费模式,帮助开发者更高效地利用这一革命性技术。
随着技术的不断演进,我们期待看到GPT-4o图像生成API在创意表达、教育、产品设计等领域带来的深远影响,开启AI辅助视觉创作的新纪元。