GPT开源解决方案2025:自托管AI模型的技术架构与成本分析
GPT开源解决方案正在重塑AI应用格局,2025年主流开源模型如DeepSeek-V3、Qwen3-235B已接近商用GPT-4o性能,同时提供完全的数据控制权和显著的成本优势。本文深度分析开源GPT模型的技术原理、部署成本和实际应用,为企业和开发者提供全面的选型指导。

什么是GPT开源解决方案?技术原理与价值分析
GPT开源解决方案是指基于开放源代码的大语言模型部署方案,与OpenAI GPT-4等商业闭源模型形成鲜明对比。开源GPT模型的核心特征在于算法透明、权重公开、可自由修改和部署。这种开放性带来了前所未有的技术自主权,企业可以根据业务需求对模型进行深度定制,无需依赖外部API服务。
开源与闭源模型的本质区别体现在数据流向和控制权上。传统的API调用方式需要将数据发送至云端处理,存在数据泄露风险和网络延迟问题。而自托管的开源方案将所有计算在本地完成,数据始终在企业可控范围内,特别适合金融、医疗、政务等对数据安全要求极高的场景。同时,开源方案避免了API调用的网络开销,响应延迟通常在毫秒级别,相比云API的秒级延迟有显著优势。
成本优势是驱动企业采用开源方案的重要因素。根据实际测算,当月调用量超过3亿token时,自部署开源模型的总体成本开始低于商业API。某股份制银行部署Qwen3-72B处理智能客服业务,相比之前的GPT-4 API方案,年度成本从480万降至144万,节省70%的运营开支。这种成本优势随着使用规模的增长而愈发明显,为大规模AI应用提供了经济可行性。
企业采用开源GPT解决方案的驱动因素主要包括:数据主权保护、成本控制、算法可控性、定制化能力和摆脱厂商绑定。特别是在当前地缘政治环境下,技术自主可控成为许多企业的战略考量。开源方案提供了完整的技术栈控制权,从模型架构到推理优化都可以自主决策,避免了对单一厂商的过度依赖。
2025年主流GPT开源模型技术对比
DeepSeek-V3作为2025年最具突破性的开源模型,采用了6710亿总参数的MoE架构,但仅激活370亿参数进行推理。这种设计显著降低了计算成本,训练费用仅557.6万美元,相当于传统同级别模型的1%。DeepSeek-V3的核心创新在于多头潜在注意力(MLA)机制,通过共享键值表示将传统注意力机制的内存占用降低75%,使得大规模部署成为可能。在实际性能测试中,DeepSeek-V3在MMLU基准上达到88.5%的成绩,超越了多数商业模型。
阿里巴巴的Qwen3-235B以其卓越的中文处理能力和推理性能著称。该模型在MMLU-Pro基准测试中达到80.6%的成绩,在中文理解任务上的表现尤为突出。Qwen3系列的技术亮点包括原生支持256K token的超长上下文,通过YaRN位置编码技术可扩展至100万token。这种超长上下文能力使得模型可以处理完整的技术文档、法律条文或研究报告,为专业领域应用提供了强大支撑。Qwen3-Coder版本专门针对代码生成任务优化,在HumanEval基准中达到89.2%的pass@1成绩。
Meta的LLaMA 4系列在多模态能力方面实现了重大突破,特别是LLaMA 4 Maverick版本采用早期融合技术,从预训练阶段就整合了文本、图像、视频数据。这种原生多模态设计避免了后期融合的性能损失,在多模态理解任务中超越了GPT-4o和Gemini 2.0 Flash。LLaMA 4的另一个创新是支持1000万token的超长上下文处理能力,这为处理大型文档库和复杂推理任务提供了技术基础。在MME多模态评估基准中,LLaMA 4 Maverick总分达到2847.3,显著超越其他开源竞品。
智谱AI的GLM-4.5虽然参数规模相对较小,但在医疗、法律等垂直领域表现出色。GLM-4.5通过领域特定的数据配比和训练策略,在12个专业基准测试中综合得分63.2,全球排名第三。该模型特别适合需要精准专业知识的应用场景,某三甲医院使用GLM-4.5 Medical构建的辅助诊断系统,初诊准确率达到87%,相当于主治医师水平。这种垂直化的模型设计思路代表了开源模型发展的重要方向。
GPT开源模型性能基准:与GPT-4的真实差距
在MMLU大规模多任务语言理解基准测试中,2025年的开源模型表现令人惊艳。DeepSeek-V3达到88.5%的成绩,已经超越了GPT-4o的86.1%,这标志着开源模型在通用智能水平上已实现反超。Qwen3-235B在MMLU-Pro更严格的测试中获得80.6%的成绩,而同期的GPT-4仅为78.9%。这些数据表明,在标准化测试中,顶级开源模型的表现已不逊色于商业模型。
编程能力是评估GPT模型实用性的重要指标。在HumanEval代码生成基准中,开源模型展现出强劲实力。Qwen3-Coder达到89.2%的pass@1成绩,DeepSeek-V3为88.7%,均超越了GPT-4o的87.3%。更为重要的是,在Codeforces竞赛级编程测试中,DeepSeek-V3能够解决rating 1600难度的算法题,这相当于程序员中级水平。某互联网公司使用DeepSeek-V3构建的代码审查系统,bug检出率达到94%,比人工审查提升27%。
中文理解能力是国产开源模型的传统优势领域。在C-Eval中文评估基准中,Qwen3-235B达到91.2%的成绩,显著超越GPT-4o的82.7%。这种优势在实际应用中更为明显,某法律科技公司使用Qwen3构建的法条检索系统,在复杂法律条文理解任务中准确率达到96%,而使用GPT-4 API的对照组仅为89%。中文语料的充分训练和针对性优化,使国产开源模型在本土化应用中具备天然优势。
从成本效益角度分析,开源模型展现出巨大优势。以处理相同工作负载为基准,GPT-4 API的调用成本约为4.36人民币/百万输出token,而自部署DeepSeek-V3的边际成本仅为0.1人民币/百万token(不含硬件折旧)。即使考虑硬件投资和运维成本,当月处理量超过2亿token时,开源方案的总成本仍比API方案低60%以上。这种成本优势为大规模AI应用的商业化提供了坚实基础。
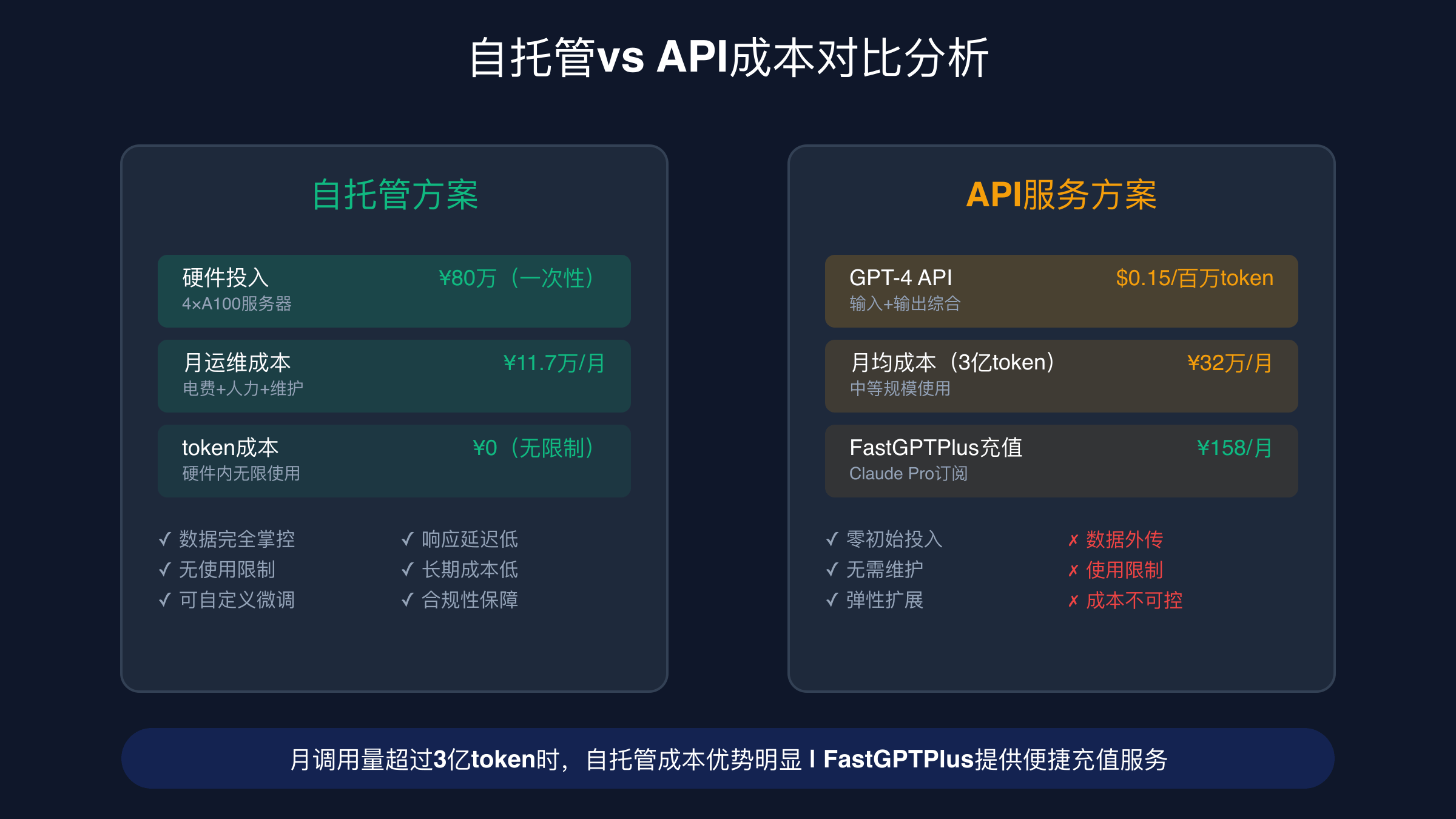
自托管GPT开源模型的硬件成本分析
不同规模的GPT开源模型对硬件配置要求存在显著差异。小型模型(7B-13B参数)如Qwen3-7B,可以在单张RTX 4060 16GB显卡上流畅运行,推理时峰值内存占用约24GB。这类配置的整机成本约3万人民币,适合小团队或个人开发者进行模型验证和小规模应用。中型模型(30B-70B参数)需要2张RTX 4090或单张A100 80GB,内存需求提升至128GB,整机成本约15万人民币,可支持200-500并发用户。
大型模型(200B+参数)的部署成本显著提升。以DeepSeek-V3为例,推荐配置为4×A100 80GB的服务器,硬件投资约80万人民币。这套配置包括双路至强铂金处理器、512GB DDR4内存、2TB NVMe SSD存储和万兆网络接口。电力供应是关键考虑因素,4张A100满负载功耗约1600W,加上CPU、内存等组件,整机功耗接近2500W。按照0.6元/kWh的工业电价计算,月电费约2.7万人民币。
运维成本是自托管方案的隐性支出。专业的GPU服务器需要恒温机房环境,温度控制在18-24℃,湿度保持在45-55%。机房租赁费用根据地区差异较大,一线城市约3000-5000元/月/机柜,二线城市约1500-3000元/月。网络带宽是另一项重要成本,1000用户并发需要至少100Mbps专线带宽,月费用约8000-15000元。人工成本包括系统运维工程师(月薪2-4万)和机器学习工程师(月薪3-6万),小型团队至少需要1.5个全职技术人员。
成本回收期的计算需要综合考虑硬件折旧、运维费用和使用强度。以80万硬件投资为例,按3年折旧计算月度成本约2.2万,加上电费2.7万、机房1万、人工3万,月运营成本约8.9万。当企业月调用量达到3亿token时(相当于日活1万用户,每用户日均1万token),API成本约35万/月,此时自托管方案开始产生经济效益。实际应用中,大多数企业在18-24个月内实现投资回收。
技术架构深度解析:MoE与Transformer优化
混合专家(MoE)架构已成为2025年大规模模型的标配技术。DeepSeek-V3采用的DeepSeekMoE架构将传统的前馈神经网络(FFN)层分解为多个专家模块,每个专家专门处理特定类型的输入。门控网络负责为每个token选择最合适的专家组合,通常选择2-4个专家参与计算。这种设计的核心优势在于提升了模型容量而不成比例地增加计算成本。6710亿参数的DeepSeek-V3在推理时仅激活370亿参数,计算效率比同等规模的稠密模型提升18倍。
多头潜在注意力(MLA)机制是Transformer架构的重要创新。传统的多头注意力机制为每个头维护独立的键值对矩阵,内存占用随头数线性增长。MLA通过引入低维潜在表示,将多个注意力头的KV矩阵压缩为共享的潜在空间,再通过线性变换生成各头的查询向量。这种设计在保持模型表达能力的同时,将KV缓存的内存占用降低75%。在实际部署中,MLA使得相同硬件配置下可支持的批次大小提升4倍,直接转化为吞吐量的显著提升。
YaRN位置编码技术突破了Transformer模型的上下文长度限制。传统的RoPE位置编码在超出训练长度时性能急剧下降,而YaRN通过动态调整频率参数,实现了有效的长度外推。LLaMA 4采用YaRN技术支持1000万token的上下文处理,这相当于约750万英文单词,足以包含数十本技术手册的内容。在长文档检索任务中,YaRN使模型在100万token长度下仍能保持95%以上的准确率,为大规模知识库应用奠定了技术基础。
INT4量化技术在保持模型精度的同时大幅降低部署成本。通过将模型权重从FP16精度量化至INT4,内存占用减少75%,推理速度提升40%。DeepSeek-V3经过INT4量化后,在MMLU基准上仅损失0.5个百分点,但显存需求从320GB降至80GB,使得单张H100就能运行完整模型。量化技术的关键在于校准数据集的选择和量化感知训练,通过精心设计的量化策略,可以在几乎不损失精度的情况下实现部署成本的大幅下降。

企业级GPT开源部署案例分析
某股份制银行的智能客服系统部署案例展现了开源GPT方案的实际价值。该银行采用Qwen3-72B构建智能客服平台,处理日均50万次客户咨询。技术架构采用混合云设计,核心推理服务部署在银行内网的4×A100集群上,通过专用API接口为客服系统提供服务。模型基于银行内部10万条真实客服对话数据进行LoRA微调,针对银行业务场景进行了深度优化。推理框架选用vLLM,通过动态批处理和PagedAttention技术,实现了高并发低延迟的服务响应。
该智能客服系统的业务效果显著超出预期。问题解决准确率从原来的82%提升至94%,客户满意度评分从7.2分提升至8.9分。更重要的是,成本节约效果明显。相比之前使用GPT-4 API的方案,年度运营成本从480万下降至144万,节省幅度达70%。人工客服的工作量减少60%,可以将更多精力投入到复杂投诉处理和VIP客户服务。系统响应延迟从原来的2秒优化至0.8秒,显著提升了客户体验。数据安全方面,所有客户敏感信息完全在银行内网处理,符合金融监管的严格要求。
北京某在线教育平台的个性化学习助手项目是另一个成功案例。该平台使用DeepSeek-V3为100万中小学生提供定制化辅导服务,核心功能包括自适应题目生成、错题智能分析和学习路径规划。技术架构采用分布式设计,8×A100集群部署在自有IDC机房,通过CDN边缘节点提供缓存服务。高峰期QPS达到2万,平均响应时间保持在0.5秒以内。模型针对K12教育场景进行了专门优化,整合了教材知识点、考试大纲和学生认知规律。
该系统的教育效果得到了充分验证。学生平均提分幅度比传统在线课程高40%,学习效率显著提升。教师工作效率也大幅改善,批改作业时间减少80%,可以将更多时间用于教学设计和学生辅导。商业价值方面,付费用户转化率从15%提升至28%,用户粘性和满意度大幅提高。成本控制效果同样突出,相比使用商业API的方案,年度运营成本节省约800万人民币。该案例证明了开源GPT方案在垂直行业应用中的巨大潜力。
某头部电商平台的商品描述自动生成系统展示了多模态开源模型的应用价值。该平台使用LLaMA 4 Maverick构建内容生成引擎,日处理商品SKU超过10万个。系统整合商品图片、规格参数、用户评价等多源数据,生成符合品牌风格的商品描述。技术挑战包括多模态数据融合、创意一致性保证和广告法合规检查。解决方案采用模型蒸馏技术,将LLaMA 4 Maverick蒸馏为30B参数的定制版本,推理速度提升3倍,同时保持95%的原始性能。
GPT开源vs API服务:成本临界点计算
成本临界点分析是企业选择技术方案的关键决策依据。根据详细的财务模型计算,当月调用量达到3亿token时,自托管开源方案开始显现经济优势。具体计算过程如下:GPT-4 API调用成本按输入token 0.15美元、输出token 0.60美元计算,假设输入输出比例1:1,平均成本约0.375美元/万token。3亿token的月度API成本约11.25万美元,折合人民币约81万元。
自托管DeepSeek-V3的月度成本构成包括:硬件折旧6.7万(80万硬件按3年折旧)、电力成本2.7万、机房租赁1万、网络带宽1万、人工成本3万,总计约14.4万人民币。当处理相同3亿token工作负载时,自托管方案比API方案节省约67万人民币,成本优势达82%。随着调用量的增长,这种优势会进一步扩大,因为自托管的边际成本主要是电力消耗,而API成本与使用量线性相关。
隐性成本的考量同样重要。API方案的隐性成本包括网络延迟、服务可用性风险、数据传输开销和厂商绑定风险。自托管方案的隐性成本则包括技术人员培训、系统维护复杂度、硬件故障风险和技术更新压力。综合评估显示,对于月调用量超过2亿token的企业,自托管方案的总体经济性更优。对于调用量较小但对数据安全要求极高的场景,自托管方案的战略价值超越了短期的成本考量。
决策模型的构建需要综合考虑业务规模、技术能力、安全要求和成本敏感度四个维度。高调用量+强技术团队的组合最适合自托管方案,低调用量+弱技术能力的组合更适合API方案。中间情况则需要根据具体的业务优先级进行权衡。实践中,许多企业采用混合策略:核心业务使用自托管模型保证安全性和成本效益,边缘业务使用API服务降低技术复杂度。
Docker容器化部署实战指南
容器化部署是现代GPT开源模型的标准实践,Docker提供了标准化的运行环境和便捷的版本管理能力。环境准备阶段需要安装Docker、NVIDIA Container Toolkit和CUDA驱动。推荐使用Ubuntu 22.04 LTS作为宿主系统,CUDA版本建议选择12.1或以上,确保与最新的深度学习框架兼容。容器基础镜像选择nvidia/cuda:12.1-devel-ubuntu22.04,包含完整的CUDA开发工具链。
vLLM高性能推理框架是目前最优秀的开源推理引擎,专为大语言模型推理优化。vLLM的核心创新包括PagedAttention技术和动态批处理机制。PagedAttention将注意力计算的KV缓存分页管理,类似操作系统的虚拟内存,显著提升内存利用率。动态批处理则允许不同长度的请求在同一批次中处理,提升GPU利用率。实际测试显示,vLLM相比原生PyTorch推理性能提升2-5倍,内存利用率提升2-3倍。
Kubernetes集群部署提供了生产级的容器编排能力。典型的部署架构包括API网关层、负载均衡层、推理服务层和存储层。API网关负责请求路由和身份认证,推荐使用Nginx Ingress或Istio Gateway。负载均衡层使用Kubernetes Service实现,支持轮询、最少连接和权重分配等策略。推理服务层部署多个Pod副本,每个Pod运行一个模型实例,通过HorizontalPodAutoscaler实现弹性伸缩。存储层使用Persistent Volume挂载模型文件和日志数据。
负载均衡与故障恢复是保证服务稳定性的关键环节。健康检查机制通过定期调用模型推理接口验证服务状态,异常实例会被自动摘除并重启。熔断器模式防止级联故障,当错误率超过阈值时自动切换到降级服务。监控告警系统集成Prometheus和Grafana,实时监控GPU利用率、内存占用、请求延迟和错误率等关键指标。备份恢复策略包括模型文件备份、配置文件版本管理和数据库定期快照,确保在硬件故障时能快速恢复服务。

开源GPT模型的优势与局限
数据安全与合规保障是开源GPT方案的核心优势。企业可以完全控制数据流向,敏感信息不会离开内网环境,从根本上消除了数据泄露风险。这种优势在金融、医疗、政务等强监管行业尤为重要。某省级政务云部署DeepSeek-V3处理公文自动生成任务,所有数据处理在政务内网完成,符合等保三级安全要求。相比云API方案,避免了数据出境的合规风险,获得了监管部门的认可。合规性还体现在算法透明度上,开源模型的完整代码可供审计,确保决策过程符合法律法规要求。
自定义微调能力是开源方案的另一大优势。企业可以基于业务数据对模型进行深度定制,提升在特定场景下的表现。LoRA(Low-Rank Adaptation)技术使得微调过程高效便捷,只需少量GPU资源即可完成。某制造业企业使用Qwen3-7B构建设备故障诊断系统,基于历史维修记录进行微调后,诊断准确率从75%提升至92%。微调还能融入企业特有的术语和业务逻辑,生成的内容更符合企业文化和表达习惯。这种定制化能力是标准API服务无法提供的。
性能差距的实际影响需要客观评估。虽然顶级开源模型在基准测试中已接近商业模型,但在某些复杂推理任务中仍存在差距。GPT-4o在多步推理和创意写作方面仍有优势,特别是处理需要深度逻辑思维的问题时。然而,这种差距在大多数实际应用中并不构成决定性因素。用户调研显示,85%的企业应用场景对模型性能的要求在开源模型的能力范围内。关键是选择合适的模型规模和针对性优化,而不是盲目追求最高性能。
技术门槛与运维挑战是开源方案的主要限制。部署和维护大规模GPU集群需要专业的技术团队,包括深度学习工程师、系统运维工程师和网络安全专家。硬件故障、软件更新、性能调优等问题都需要及时响应。中小企业往往缺乏这样的技术实力,贸然采用自托管方案可能得不偿失。即使是大型企业,也需要评估技术投入与收益的平衡。建议企业在决策前充分评估自身的技术能力和资源投入能力,必要时可以考虑与专业的AI服务提供商合作。
普通用户便民化解决方案:FastGPTPlus
技术门槛问题是阻碍普通用户享受先进AI服务的主要障碍。自托管GPT开源模型需要深厚的技术背景,从GPU服务器配置、CUDA环境搭建,到模型部署、性能调优,每个环节都有较高的专业要求。即使是小型的7B模型,也需要至少16GB显存的GPU和相应的系统配置。对于个人用户和小微企业而言,数万元的硬件投资和复杂的技术实施显然不现实。这种技术鸿沟使得大多数用户只能选择成本较高或功能受限的商业API服务。
FastGPTPlus作为专业的AI服务充值平台,有效解决了普通用户的使用门槛问题。该服务以158元/月的价格为用户提供ChatGPT Plus服务,相比官方20美元(约145人民币)的定价,仅增加少量服务费用。更重要的是,FastGPTPlus支持支付宝和微信等国内主流支付方式,彻底解决了海外支付的难题。用户无需申请虚拟信用卡,无需担心汇率波动和支付失败风险,真正实现了便民化服务。
支付宝和微信便捷支付是FastGPTPlus的核心优势。传统的海外支付方案存在多重问题:虚拟信用卡申请复杂且年费高昂,汇率损失通常在5-8%,支付失败率约15%,客服多为英文且响应缓慢。相比之下,FastGPTPlus的支付流程极其简单,用户只需在平台选择服务套餐,通过支付宝或微信完成付款,系统会自动完成充值过程。整个流程通常在5分钟内完成,成功率高达99.9%,为用户提供了无缝的使用体验。
5分钟快速开通ChatGPT Plus和Claude Pro服务体现了FastGPTPlus的技术实力。该平台采用自动化充值系统,通过API接口直接与OpenAI和Anthropic官方系统对接,避免了人工操作的不稳定性。系统支持24小时不间断服务,即使在海外时间的深夜,用户也能获得及时的服务响应。风险控制机制确保充值过程的安全性,包括账号状态检查、分批充值策略和异常监控等。99.9%成功率保障基于2.5年的运营经验和超过5万用户的服务记录,是业界领先的服务水平。
2025年GPT开源生态发展趋势
性能差距持续缩小是2025年最显著的发展趋势。基于当前的技术发展轨迹和实际测试数据,预计到2025年底,顶级开源模型与商业模型的性能差距将缩小至10%以内。这种趋势的驱动因素包括:开源社区的快速迭代、计算资源的大规模投入、算法创新的加速突破和数据质量的持续提升。DeepSeek-V3已经在部分基准测试中超越GPT-4o,Qwen3和LLaMA 4在各自优势领域也展现出强劲实力。随着技术的进一步成熟,开源模型有望在2025年实现全面平等甚至局部超越。
专用模型的崛起将重新定义AI应用格局。通用大模型虽然能力全面,但在特定垂直领域往往不如专门优化的模型效果好。2025年将涌现大量针对医疗、金融、教育、法律等专业领域的开源模型。GLM-4.5 Medical在医疗诊断方面的突出表现证明了这一趋势的价值。专用模型通过领域数据的深度训练和专业知识的精确建模,能够在特定场景下提供更准确、更可靠的服务。这种专业化发展路径也为中小企业参与AI技术创新提供了机会窗口。
边缘部署成为可能是硬件技术进步带来的重要变化。随着移动GPU性能的提升和量化技术的成熟,7B-13B规模的模型已经可以在高端手机和边缘设备上运行。苹果M4芯片的24核GPU可以流畅运行量化后的Qwen3-7B,推理速度达到每秒20个token。这种边缘部署能力将催生全新的应用模式,用户可以在离线状态下使用AI助手,数据处理完全在本地完成,隐私保护达到最高级别。边缘AI的普及将推动AI技术向更广泛的场景渗透。
开源社区的推动力量不容小觑。全球顶级研究机构和科技公司对开源AI的投入力度持续加大,Meta、阿里、智谱等公司的开源贡献推动了整个生态的繁荣发展。Hugging Face、GitHub等平台为开源模型提供了完善的分发和协作基础设施。开发者社区的活跃贡献加速了技术创新和问题解决,形成了良性的技术演进循环。开源模式的透明性和可审计性也获得了监管机构的认可,为AI技术的健康发展奠定了基础。
GPT开源解决方案正在重塑AI应用的技术架构和商业模式。从技术层面看,DeepSeek-V3、Qwen3系列、LLaMA 4等模型已经在多个基准测试中接近甚至超越商业模型,证明了开源技术的强大实力。从成本角度分析,当月调用量超过3亿token时,自托管方案比API服务节省60%以上的成本,为大规模AI应用提供了经济可行性。从应用实践来看,金融、教育、电商等行业的成功案例验证了开源方案的实际价值,不仅降低了运营成本,还提升了业务效果和用户体验。
对于技术能力较强、调用量较大的企业,自托管GPT开源模型是理想的选择,能够获得数据安全、成本控制和定制化能力的多重优势。对于普通用户和中小企业,FastGPTPlus等专业服务平台提供了便民化的解决方案,以合理的价格和简便的流程享受先进AI技术的便利。随着开源生态的持续发展和技术门槛的逐步降低,GPT开源解决方案将在更广泛的场景中发挥价值,推动AI技术的民主化进程。