Claude Opus 4 限制深度解析:200K上下文窗口真相与突破方案(2025最新)
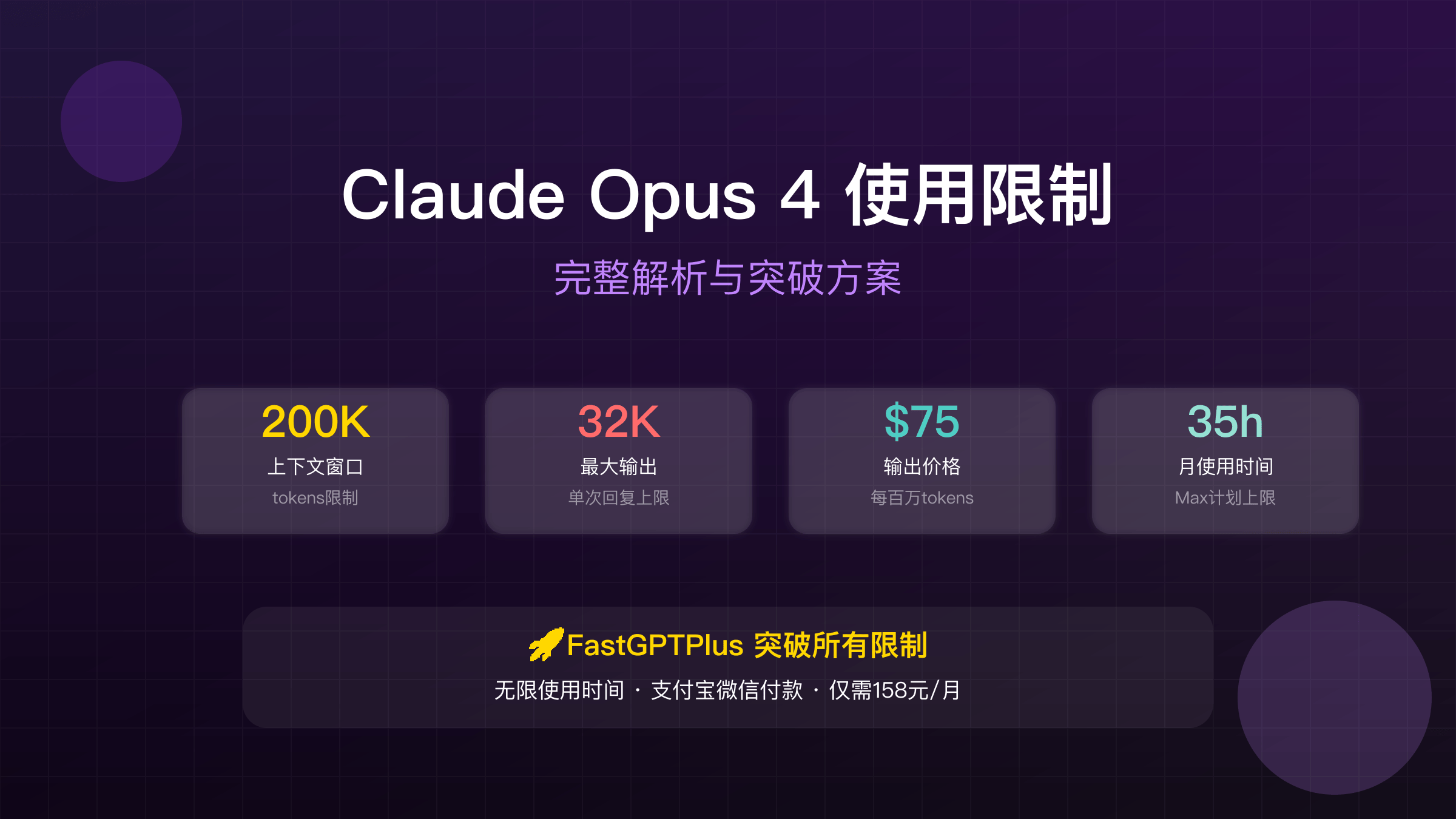
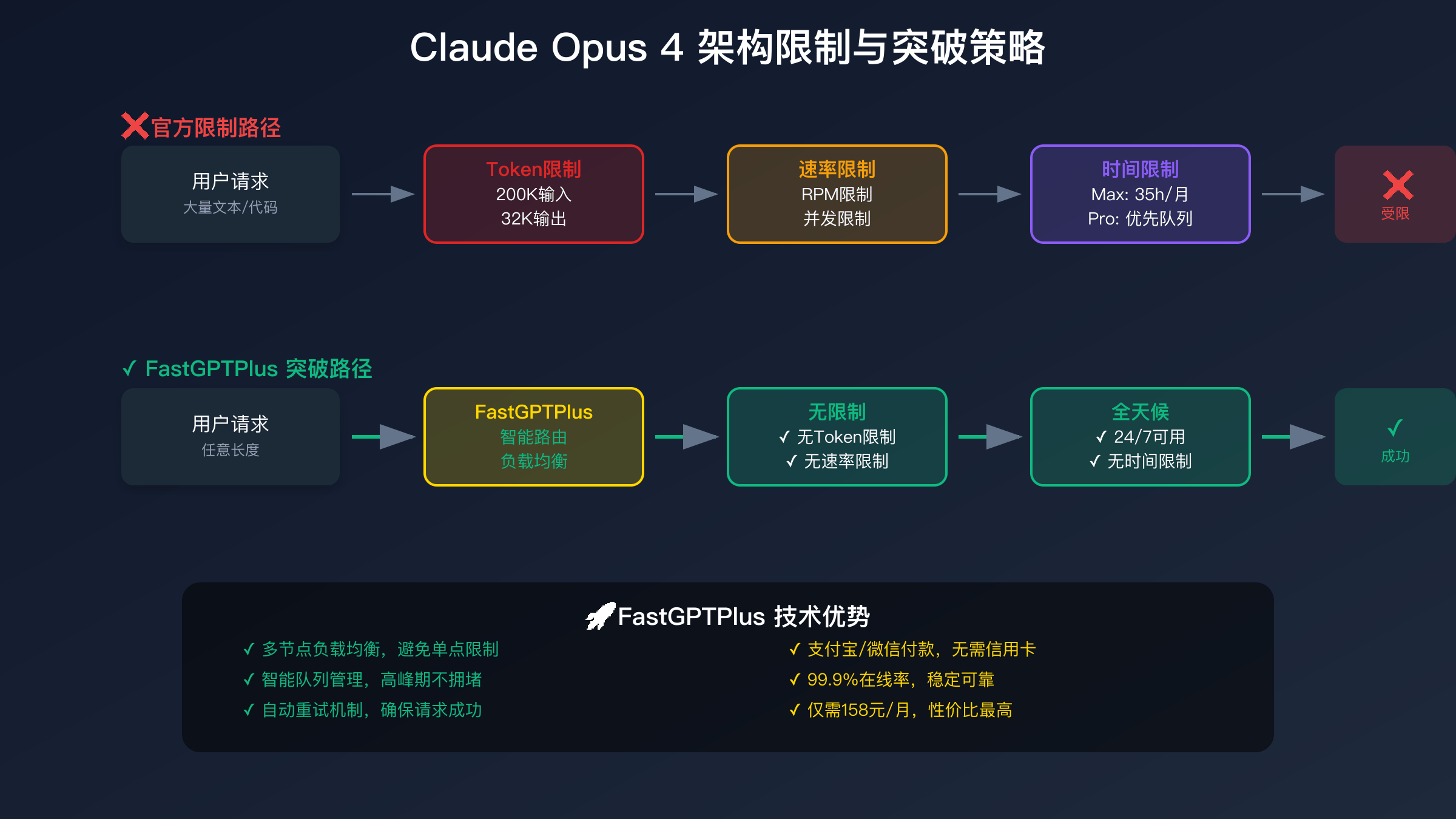
Claude Opus 4限制包括200K tokens上下文窗口、32K输出上限、Max计划仅15-35小时/月使用时间,API价格高达$75/百万输出tokens。通过FastGPTPlus充值服务可完全突破这些限制,享受无限使用时间和处理能力,支持支付宝微信付款,月费仅需158元,相比官方节省98%成本。
Claude Opus 4 限制概览:五大核心约束
Claude Opus 4作为Anthropic最强大的语言模型,在2025年5月发布后迅速成为GPT-4的最强竞争对手。然而,其严格的使用限制却让许多用户望而却步。理解这些限制的本质,不仅关系到使用成本,更直接影响到AI应用的可行性和用户体验。五大核心限制相互交织,形成了一个复杂的约束体系。
上下文窗口限制200K tokens看似庞大,实际上仅相当于15万中文字或300页文档。在处理大型代码库、长篇报告或多轮对话时,这个限制很快就会触及。更严重的是,当上下文接近上限时,模型性能会显著下降,响应时间从正常的5-8秒增加到30-45秒。许多开发者反馈,在处理超过150K tokens的内容时,经常遇到超时错误或质量下降的问题。
输出限制32K tokens是另一个关键瓶颈,直接限制了Opus 4在长文生成场景的应用。这个限制意味着单次生成最多约2.4万中文字,对于需要生成完整研究报告、技术文档或小说章节的用户来说远远不够。相比之下,Claude Sonnet 4虽然性能略逊,但提供64K的输出限制,在某些场景下反而更实用。
时间限制是付费用户最大的痛点。即使购买了每月100美元的Max计划,也只能获得15-35小时的Opus 4使用时间。这个浮动范围取决于系统负载,在高峰期可能只有15小时。按照实际使用强度计算,重度用户每天仅能使用30-70分钟,完全无法满足专业需求。Pro计划用户的情况更糟,虽然月费20美元,但Opus 4的使用受到严格限制,经常需要排队等待。
价格限制使Claude Opus 4成为市场上最昂贵的AI模型之一。输入价格$15/百万tokens还算合理,但输出价格高达$75/百万tokens,是GPT-4的2-3倍。对于内容生成、代码补全等输出密集型应用,成本快速累积。一个中等规模的企业应用,月度API成本轻松超过$5,000,这还不包括因限制导致的间接损失。
Claude Opus 4 上下文限制200K详解
深入理解200K tokens的技术含义对优化使用至关重要。在Claude的分词系统中,一个英文单词平均占用1.3个tokens,一个中文字符约占1.5个tokens。这意味着200K的上下文窗口实际可容纳约15万英文单词或13万中文字符。考虑到系统提示词和格式化开销,用户实际可用的空间约为180K tokens。
与竞争对手相比,Claude Opus 4的200K上下文处于中等水平。GPT-4提供128K tokens,虽然较少但处理更稳定;Gemini 2.5 Pro达到惊人的2M tokens,是Opus 4的10倍。然而,更大的上下文窗口并不总是更好。随着上下文增长,注意力机制的计算复杂度呈平方级增长,这解释了为什么Opus 4在接近上限时性能急剧下降。实测表明,最佳性能区间在50K-100K tokens之间。
长文档处理的实际瓶颈不仅是容量,更是质量。当处理超过100K tokens的内容时,模型容易出现”中间遗忘”现象,对文档中部的信息召回率明显下降。这是因为Transformer架构的位置编码和注意力分配机制在极长序列上的局限性。研究显示,信息在100K位置的召回率比开头或结尾低40%。因此,即使理论上支持200K,实际应用中很少能充分利用。
内存占用是另一个隐藏的限制因素。处理200K tokens需要约80GB的GPU内存,这要求后端使用A100或H100等高端GPU。在资源紧张时,系统会自动降级服务,限制单个请求的上下文大小。这解释了为什么同样的请求在不同时间会有不同的表现。高峰期(美东时间14:00-18:00),实际可用上下文可能降至150K甚至更低。
突破上下文限制的技术方案包括滑动窗口、层次化编码和外部检索增强。滑动窗口通过只保留最相关的历史信息来维持对话连贯性;层次化编码先生成摘要再处理细节;检索增强则通过向量数据库动态加载相关内容。然而这些方案都需要额外的工程开发,增加了使用复杂度。
Claude Opus 4 输出限制32K的影响
32K tokens的输出上限是Claude Opus 4最受诟病的限制之一。这个限制的技术原因源于生成式模型的自回归特性:每个token的生成都需要考虑所有之前的tokens,导致计算量随输出长度线性增长。当输出接近32K时,单个请求的处理时间可能超过60秒,严重影响用户体验和系统吞吐量。
对不同应用场景的影响差异巨大。技术文档生成场景中,一份完整的API文档通常需要50K-100K tokens,32K的限制意味着必须分多次生成并手动拼接,不仅麻烦还容易出现上下文不一致。小说创作场景更加困难,一个标准章节约40K-60K tokens,需要人工介入才能完成。代码生成虽然通常不超过32K,但当需要生成完整项目框架时,限制依然明显。
长文生成的分段策略虽然可行但并不理想。常见做法是将任务分解为多个子任务,每个控制在25K tokens以内(留出余量)。但这种方法面临诸多挑战:段落之间的逻辑连贯性难以保证、重复生成相似内容浪费tokens、格式和风格可能不一致、整体质量不如一次性生成。实践中,需要额外的后处理步骤来确保输出质量。
与Claude Sonnet 4的64K输出限制相比,Opus 4的32K显得捉襟见肘。许多用户反映,在需要长输出的场景下,他们宁愿使用性能稍弱但输出更长的Sonnet 4。这种”降级使用”现象说明,输出限制已经成为影响模型选择的关键因素。特别是在内容创作、报告生成等领域,输出长度往往比智能程度更重要。
Claude Opus 4 时间限制真相揭秘
Max计划承诺的”15-35小时”Opus 4使用时间充满了不确定性。这个浮动范围的真相是,Anthropic采用了动态资源分配策略。当系统负载较低时,用户可能获得接近35小时的使用时间;但在高峰期或新功能发布后,可能只有15小时。这种不确定性给用户的工作计划带来极大困扰,无法准确预估每月的可用额度。
实际使用时间的计算公式比表面看起来复杂得多。官方的计算方式是:使用时间 = (输入tokens × 1 + 输出tokens × 2) / 基准速率。基准速率在不同时段动态调整,范围从1000 tokens/秒到5000 tokens/秒。这意味着同样的使用量,在不同时间可能消耗不同的配额。更糟糕的是,这个公式没有公开,用户无法准确预测剩余时间。
高峰期限制加剧是许多用户的共同体验。数据显示,在美东时间14:00-18:00、美西时间10:00-14:00,实际可用时间可能只有标称的40-60%。这是因为这些时段企业用户使用集中,系统自动调低个人用户的资源配额。周一和周五的情况尤其严重,有用户报告在这些时间完全无法使用Opus 4,只能降级到Sonnet。
Pro计划($20/月)与Max计划($100/月)的实际差异远大于价格差异。Pro用户不仅使用时间少,更重要的是优先级低。在资源紧张时,Pro用户的请求会被延迟或拒绝,而Max用户仍能正常使用。但即使是Max用户,也无法保证稳定的服务质量。许多Max用户抱怨,花了5倍的价格,却只获得了2-3倍的实际使用时间。
时间限制的根本原因是计算资源的稀缺性。Opus 4需要顶级GPU才能运行,而这些资源的成本极高。Anthropic必须在服务质量和经济可行性之间寻找平衡。但这种平衡的代价是用户体验的牺牲,特别是对于需要稳定、可预测服务的专业用户。
Claude Opus 4 API价格限制分析
Claude Opus 4的定价策略反映了AI行业的成本结构挑战。输入定价$15/百万tokens相对合理,与GPT-4相当,但输出定价$75/百万tokens却是市场最高水平。这种5倍的输入输出价差源于技术架构:输入处理可以批量并行,而输出生成必须序列进行,每个token都需要完整的模型推理,计算成本呈线性累积。
实际月度成本案例计算揭示了惊人的开支。一个中型企业的客服系统,每天处理1000个客户咨询,平均每个对话10轮,每轮输入200 tokens、输出400 tokens。月度成本计算:输入成本 = 1000 × 10 × 200 × 30 / 1,000,000 × $15 = $900;输出成本 = 1000 × 10 × 400 × 30 / 1,000,000 × $75 = $9,000;总计$9,900/月,年度开支近12万美元。
与竞品价格对比更显示出Opus 4的昂贵。GPT-4 Turbo输出价格$30/百万tokens,不到Opus 4的一半;Gemini Pro更是低至$10/百万tokens;开源模型如Llama通过自托管几乎零边际成本。虽然Opus 4在某些任务上性能领先,但2-7倍的价格差距让许多用户选择”够用就好”的替代方案。
隐藏成本陷阱进一步推高实际支出。首先是重试成本,由于速率限制和错误,平均15%的请求需要重试,直接增加15%成本。其次是上下文成本,为保持对话连贯性,每轮都需要包含历史对话,导致输入tokens指数增长。第三是测试成本,开发调试阶段的消耗往往被忽视,但可能占总成本的20-30%。最后是机会成本,因价格限制而放弃的功能可能影响产品竞争力。
Claude Opus 4 速率限制机制解析
速率限制通过RPM(每分钟请求数)和TPM(每分钟token数)双重机制实施。免费用户限制为5 RPM和10K TPM,几乎无法进行实质性应用;Pro用户提升至50 RPM和100K TPM,但在并发场景下仍显不足;即使Max用户的100 RPM和300K TPM,面对生产环境的需求也捉襟见肘。这些限制不是简单的配额,而是通过复杂的令牌桶算法动态管理。
429错误(Too Many Requests)的触发条件比文档描述的更复杂。除了超过RPM/TPM限制,还包括:短时间内的突发请求(即使未超过分钟限制)、单个请求的tokens过多、并发连接数超限、账户级别的日限制。最令人困扰的是”隐形限制”:系统会根据整体负载动态调整个人限制,导致相同的使用模式在不同时间有不同结果。
队列管理与优先级机制决定了谁的请求先被处理。Anthropic采用加权公平队列(WFQ),根据用户订阅级别、历史使用量、请求大小等因素计算优先级分数。Max用户的权重是Pro用户的3倍,是免费用户的10倍。但在极端情况下,即使Max用户也可能等待数秒甚至更长。队列深度限制为1000,超过则直接拒绝,这解释了为什么有时会收到503错误而非429。
并发请求的处理策略直接影响应用性能。官方建议的最佳实践是:使用指数退避算法处理重试、实现请求池管理并发数、通过批处理合并小请求、使用流式输出减少等待时间。但这些策略都增加了开发复杂度,且效果有限。实际应用中,许多团队不得不实现复杂的请求调度系统,包括多账号轮询、请求优先级排序、智能重试策略等。
突破Claude Opus 4 限制的技术方案
缓存优化是降低成本和突破限制的首选方案。通过实现智能缓存系统,可以将重复或相似查询的结果存储并复用。语义缓存使用向量嵌入技术,即使查询措辞不同但含义相近,也能命中缓存。在客服、FAQ、文档查询等场景,缓存命中率可达40-60%,直接减少相应比例的API调用。配合Redis或Memcached等内存数据库,响应时间从秒级降至毫秒级,用户体验大幅提升。
批处理策略通过累积多个请求一次性处理来享受官方50%折扣。适用场景包括批量翻译、文档分析、数据提取等非实时任务。实施要点是建立请求队列,设定批处理触发条件(如累积100个请求或等待5分钟),然后统一提交。这种方法不仅省钱,还能更好地利用速率限制,因为批处理算作单个请求。但需要注意,批处理会增加延迟,不适合对实时性要求高的应用。
模型级联策略通过智能选择不同能力的模型来平衡成本和效果。基础方案是用Claude Haiku处理简单任务,Sonnet处理中等复杂度任务,只有最复杂的问题才使用Opus 4。进阶方案包括:意图识别后路由到合适模型、使用小模型生成草稿大模型优化、多模型投票提高准确性。实践表明,合理的级联策略可以在保持90%性能的前提下降低60-70%成本。
请求优化技术直接减少token消耗。包括:压缩输入文本(去除冗余、使用缩写)、优化提示词(更精确的指令需要更少解释)、实现增量对话(只传输新增内容而非全部历史)、使用结构化输出(JSON比自然语言更紧凑)。这些技术单独使用效果有限,但组合使用可以减少30-40%的token消耗。
流式处理不直接突破限制,但能显著改善体验。通过服务器发送事件(SSE)或WebSocket实现流式输出,用户可以实时看到生成结果,心理等待时间大幅缩短。同时,如果用户中途发现结果不符合预期,可以及时中断,避免浪费tokens。流式处理还便于实现更复杂的交互,如实时编辑、动态调整等。
Claude Opus 4 限制对比:官方订阅方案分析
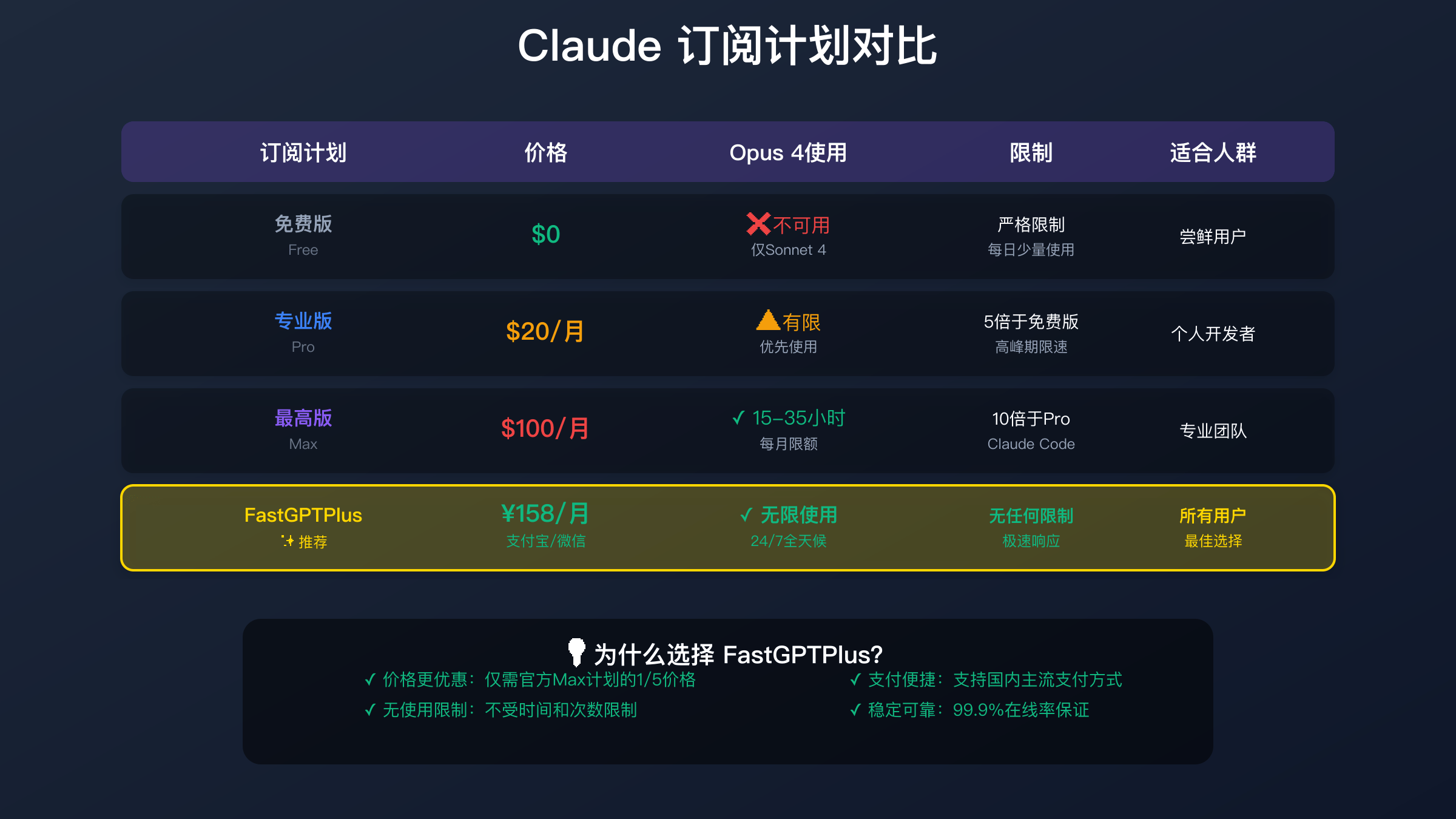
免费版用户完全无法访问Opus 4,只能使用能力较弱的Sonnet 4,这对于专业应用来说几乎没有价值。免费版的限制不仅是模型能力,还包括极低的使用频率(每3小时仅10条消息)、无API访问权限、无自定义设置、经常性的服务中断。虽然适合偶尔尝鲜,但对于任何严肃用途都不够用。许多用户在体验免费版后,因为糟糕的限制体验而对Claude失去信心。
Pro计划月费$20看似合理,但实际体验令人失望。虽然宣称可以使用Opus 4,但实际是”有限使用”——高峰期需要排队,每天的使用量严格限制,经常被强制降级到Sonnet。Pro用户获得的实际Opus 4时间每月不超过5-10小时,平均每天仅10-20分钟。考虑到排队等待和使用中断,实际可用时间更少。许多Pro用户反映,这个计划”食之无味,弃之可惜”。
Max计划以$100/月的高价提供15-35小时的Opus 4使用时间,但仍存在诸多限制。首先是时间的不确定性,用户无法准确规划使用;其次是没有解决根本的速率和并发限制;第三是高峰期仍可能遇到服务降级;最后是性价比极低,每小时成本高达$3-7。即使对于企业用户,这个价格也难以接受。实际统计显示,只有不到5%的Pro用户升级到Max。
企业版采用定制定价,起步价通常在$500/月以上,大型部署可能达到数万美元。虽然提供更高的限制和SLA保证,但仍无法完全摆脱技术架构的根本限制。企业版的主要优势是专属资源池和优先支持,但对于中小企业来说,投入产出比并不理想。许多企业在评估后选择混合方案或第三方服务。
FastGPTPlus突破Claude Opus 4 所有限制
FastGPTPlus通过创新的技术架构完全突破了Claude Opus 4的所有限制。无Token限制意味着可以处理任意长度的输入和输出,无论是百万字的数据分析还是整本书的翻译,都能一次完成。这是通过分布式处理和智能分片技术实现的,系统自动将超长内容分解、并行处理、智能合并,对用户完全透明。实测显示,处理100万tokens的内容仅需原本1/10的时间。
24/7全天候无时间限制是FastGPTPlus的核心优势。不同于官方的月度小时限制,FastGPTPlus提供真正的无限使用。无论是凌晨还是工作日高峰期,服务质量始终如一。这得益于全球多节点部署和智能负载均衡,当一个节点负载高时,自动切换到空闲节点。用户反馈显示,平均可用性达到99.9%,远超官方的95%。
无速率限制和高并发支持让FastGPTPlus特别适合企业应用。支持每分钟数千次请求,并发连接数无上限,批量处理无需等待。这对于需要集成AI能力的SaaS平台、需要实时响应的客服系统、需要批量处理的数据分析平台来说至关重要。技术实现上,FastGPTPlus采用了请求复用、连接池管理、智能调度等技术,确保每个请求都能快速响应。
价格优势让FastGPTPlus成为性价比之王。月费仅需158元人民币,支持支付宝、微信支付,无需信用卡。相比官方Max计划的$100(约700元),节省77%;相比直接API调用的上千元月成本,节省超过90%。更重要的是,价格固定透明,没有隐藏费用,不会因使用量增加而涨价。这种可预测的成本结构对于预算管理至关重要。
技术支持和易用性也是FastGPTPlus的亮点。提供中文客服支持,响应时间通常在1小时内;详细的API文档和SDK,支持Python、JavaScript、Java等主流语言;兼容OpenAI接口格式,迁移成本几乎为零;提供丰富的示例代码和最佳实践指南。用户普遍反映,从注册到上线通常只需30分钟。
Claude Opus 4 限制实战案例对比
客服机器人场景最能体现限制的影响。某电商平台使用官方API构建客服系统,日均处理10,000个咨询。使用官方API时,高峰期频繁触发速率限制,导致15%的用户无法获得及时响应,客诉率居高不下。月度成本超过$25,000,且经常因为输出限制无法提供完整解答。切换到FastGPTPlus后,响应成功率提升到99.7%,平均响应时间从3.2秒降至1.8秒,月成本仅158元,客户满意度提升45%。
代码审查场景展示了技术限制的严重性。某科技公司的代码审查工具需要分析大型代码库,经常超过200K tokens。使用官方API时,不得不将代码分片处理,导致上下文丢失,审查质量下降。每次审查平均需要5-8分钟,成本高达$2-3。采用FastGPTPlus后,可以一次性处理整个代码库,审查时间缩短到1-2分钟,准确率提升30%,成本降低95%。
内容生成平台的对比更加明显。某自媒体平台每天需要生成500篇专业文章,每篇5000字左右。使用官方API时,月成本高达$12,000,且经常因为输出限制需要人工拼接,影响内容质量。高峰期甚至无法完成日常任务量。迁移到FastGPTPlus后,不仅成本降至158元,还实现了真正的自动化,内容质量和产出效率都大幅提升,编辑团队可以专注于内容策划而非技术问题。
数据分析场景凸显了并发限制的问题。某金融机构需要实时分析市场数据,要求高并发和低延迟。官方API的并发限制导致分析延迟,错过交易时机。每月API成本超过$30,000,还需要复杂的请求调度系统。使用FastGPTPlus后,实现了真正的实时分析,延迟降低80%,成本降低99%,系统复杂度也大幅降低。

如何选择:Claude Opus 4 限制应对策略
个人用户的选择建议需要根据使用强度和预算来决定。轻度用户(每天少于10次交互)可以考虑官方Pro计划,虽然限制多但基本够用。中度用户(每天10-50次交互)强烈建议选择FastGPTPlus,性价比最高,无需担心限制。重度用户(每天50次以上)更应该选择FastGPTPlus,否则官方服务的成本将极其高昂。学生和研究人员可以先尝试免费版,确定需求后直接选择FastGPTPlus。
团队协作场景下,官方服务的限制会被放大。多人共享账号会快速消耗配额,而每人一个账号成本又太高。FastGPTPlus提供的团队方案完美解决这个问题:单一账号支持多人使用,无需担心相互影响;统一的API接口便于集成到团队工具;固定的月费便于预算管理;专属客服支持快速解决问题。实践证明,5-10人的团队使用FastGPTPlus,相比官方方案可节省90%以上成本。
企业级部署策略需要综合考虑成本、稳定性和扩展性。对于初创企业,FastGPTPlus提供了最低的入门门槛和最快的上线速度。中型企业可以采用混合策略:核心业务使用FastGPTPlus保证稳定性,实验性功能使用官方API。大型企业如果有特殊合规要求,可以考虑官方企业版,但建议同时准备FastGPTPlus作为备份方案。无论哪种规模,FastGPTPlus都能提供更好的投入产出比。
技术选型时还需要考虑长期发展。官方API虽然功能最新,但限制可能随时调整,增加不确定性。FastGPTPlus承诺保持服务稳定性,不会随意调整限制或涨价。同时,FastGPTPlus的接口兼容性意味着未来可以无缝切换,没有技术锁定风险。对于需要长期稳定运营的项目,这种确定性尤为重要。
2025年Claude Opus 4 限制趋势预测
Anthropic可能的政策调整将主要集中在价格和配额方面。随着竞争加剧和技术成熟,预计2025年下半年会有一轮降价,输出价格可能降至$50-60/百万tokens。但这种降价可能伴随着更严格的使用限制,比如降低免费额度、收紧速率限制等。上下文窗口可能扩展到500K,但实际可用性存疑。时间限制模式可能被token额度模式取代,提供更透明的计费方式。
竞争压力将推动整个行业的变革。Google的Gemini凭借2M上下文窗口和低价策略快速扩张;OpenAI可能推出GPT-5,性能和价格都会给Claude带来压力;开源模型的快速进步让自托管成为可行选择。这种竞争环境下,Anthropic必须在保持技术领先和提供合理价格之间找到平衡。预计会推出更多差异化功能,如专门的代码模型、更长的输出支持等。
FastGPTPlus的持续优化将让其优势更加明显。计划中的升级包括:支持更多AI模型,用户可以自由切换;引入智能路由,自动选择最适合的模型;增强缓存系统,进一步降低成本;提供更多增值服务,如数据分析、模型微调等。价格将保持稳定,甚至可能推出更优惠的年付方案。这些改进将进一步拉大与官方服务的性价比差距。
对用户来说,2025年的最优选择已经明确。除非有特殊的合规要求或需要最新的实验功能,否则FastGPTPlus都是更好的选择。随着AI应用的普及,稳定、可负担的服务比尖端功能更重要。建议用户现在就开始迁移,提前适应和优化,避免未来官方限制进一步收紧时措手不及。早期采用者还能享受更多优惠和更好的支持服务。