



【2025年5月更新】Google正式推出的Gemini 2.5系列以其卓越的思考能力和长上下文理解能力,成为当前大模型市场中的佼佼者。本文将全面解析Gemini 2.5 API的价格体系、费率结构、优化策略以及国内开发者的最佳接入方案,帮助您在享受顶级AI能力的同时,最大限度控制开发成本。

一、Gemini 2.5 API价格体系全解析
Gemini 2.5系列作为Google AI最新推出的旗舰模型,提供了Flash和Pro两个主要版本,分别面向不同场景和需求。根据Google官方最新公布的价格标准,两款模型在输入/输出令牌、思考能力和上下文缓存等方面有着不同的收费策略。
1. Gemini 2.5 Flash预览版价格详情
Gemini 2.5 Flash是一款平衡性能与成本的混合推理模型,支持100万token的上下文窗口,提供基础思考能力。根据Google AI官方价格页面,其价格结构如下:
| 计费项目 | 免费层级 | 付费层级(每百万令牌) |
|---|---|---|
| 输入价格(文本/图片/视频) | 免费 | $0.15 |
| 输入价格(音频) | 免费 | $1.00 |
| 输出价格(非思考) | 免费 | $0.60 |
| 输出价格(思考) | 免费 | $3.50 |
| 上下文缓存价格(文本/图片/视频) | 不可用 | $0.0375 |
| 上下文缓存价格(音频) | 不可用 | $0.25 |
| 上下文缓存存储 | 不可用 | $1.00/小时/百万令牌 |
| 使用Google搜索建立依据 | 免费,最高500次/日 | 1,500次/日免费,之后$35/1,000次请求 |
值得注意的是,Gemini 2.5 Flash的”思考”功能是该系列的创新点,允许模型在生成回答前进行深度推理。这种能力使得模型在解决复杂问题时表现更佳,但也反映在更高的输出价格上。
2. Gemini 2.5 Pro预览版价格详情
作为Google AI最强大的多用途模型,Gemini 2.5 Pro在复杂推理和编码任务方面表现卓越。这款高端模型的价格结构如下:
| 计费项目 | 免费层级 | 付费层级(每百万令牌) |
|---|---|---|
| 输入价格(≤200K令牌) | 不可用 | $1.25 |
| 输入价格(>200K令牌) | 不可用 | $2.50 |
| 输出价格(≤200K令牌) | 不可用 | $10.00 |
| 输出价格(>200K令牌) | 不可用 | $15.00 |
| 上下文缓存价格(≤200K令牌) | 不可用 | $0.31 |
| 上下文缓存价格(>200K令牌) | 不可用 | $0.625 |
| 上下文缓存存储 | 不可用 | $4.50/小时/百万令牌 |
| 使用Google搜索建立依据 | 不可用 | 1,500次/日免费,之后$35/1,000次请求 |
Gemini 2.5 Pro的价格明显高于Flash版本,这反映了其更强大的能力和更高的计算成本。特别是对于超长上下文(>200K令牌)的处理,价格会进一步提高,这是使用时需要特别注意的因素。
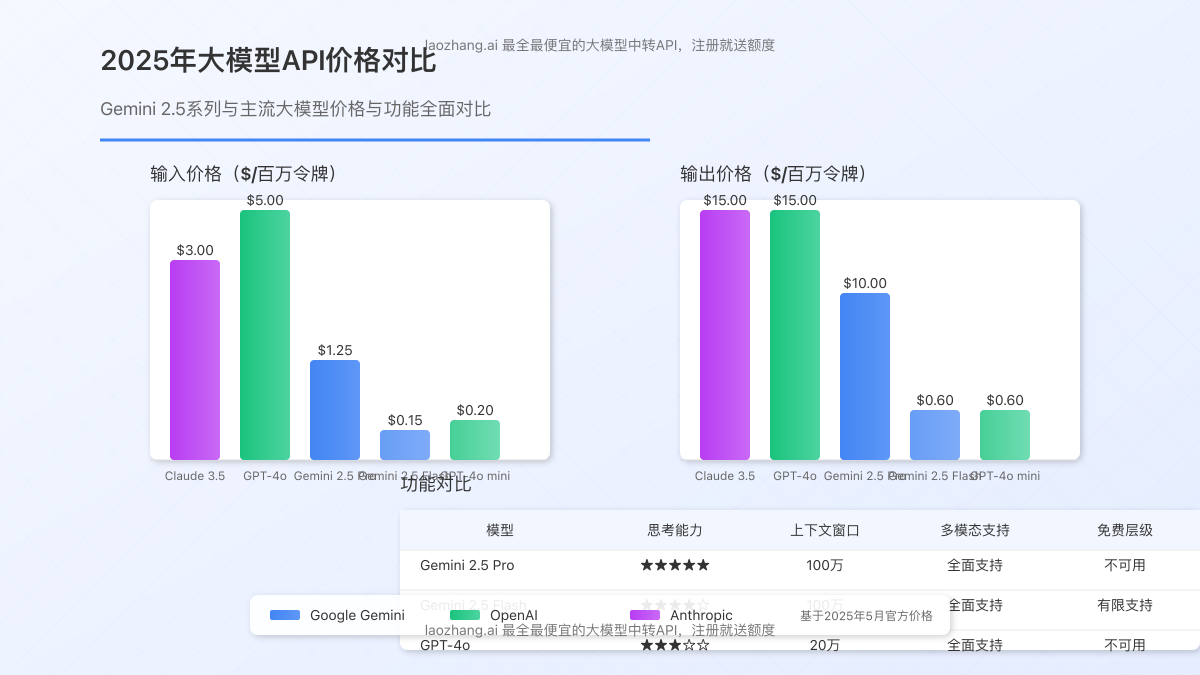
3. 与其他大模型价格对比
为了帮助开发者更好地进行技术选型,我们将Gemini 2.5系列与市场上其他主流大模型的价格进行了对比:
| 模型 | 输入价格($/百万令牌) | 输出价格($/百万令牌) | 特殊功能 |
|---|---|---|---|
| Gemini 2.5 Pro | $1.25-$2.50 | $10.00-$15.00 | 思考链、100万token上下文 |
| Gemini 2.5 Flash | $0.15-$1.00 | $0.60-$3.50 | 基础思考、100万token上下文 |
| Gemini 2.0 Flash | $0.10 | $0.40 | 100万token上下文 |
| OpenAI GPT-4o | $5.00 | $15.00 | 多模态、20万token上下文 |
| OpenAI GPT-4o mini | $0.20 | $0.60 | 多模态、12.8万token上下文 |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 多模态、20万token上下文 |
从对比可以看出,Gemini 2.5 Pro的输出价格与GPT-4o和Claude 3.5 Sonnet相当,但输入价格更具优势。而Gemini 2.5 Flash则在保持强大功能的同时,提供了更经济的价格选择,特别适合需要大规模调用的应用场景。
二、免费层级与付费层级详细对比
Google为Gemini API提供了免费层级和付费层级两种服务模式,它们在功能、限制和数据处理方面有显著差异。了解这些差异有助于开发者选择适合自己需求的服务级别。
1. 服务层级主要区别
| 比较项目 | 免费层级 | 付费层级 |
|---|---|---|
| 适用场景 | 测试、学习、小规模个人项目 | 商业应用、企业级开发、高流量服务 |
| 模型可用性 | 有限(无Gemini 2.5 Pro) | 完整访问所有模型 |
| 速率限制 | 严格(低RPM和RPD限制) | 宽松(高RPM和RPD限制) |
| 数据处理 | 数据可能用于改进Google产品 | 数据不用于改进Google产品 |
| 功能限制 | 部分高级功能不可用 | 完整功能访问 |
| 支持级别 | 基础支持 | 优先支持 |
免费层级主要适合初学者和测试用途,而付费层级则提供了更完整的功能和更高的稳定性,适合商业应用和专业开发。
2. 速率限制详解
速率限制是Gemini API使用中需要特别关注的因素。不同服务层级和模型有着不同的速率限制规则:
| 模型 | 层级 | 每分钟请求数(RPM) | 每日请求数(RPD) | 升级条件 |
|---|---|---|---|---|
| Gemini 2.5 Pro | 免费层级 | 不可用 | 不可用 | – |
| Gemini 2.5 Pro | 付费一级 | 60 | 1,000 | 绑定有效账单账户 |
| Gemini 2.5 Pro | 付费二级 | 300 | 10,000 | 累计消费≥$250且成功付款30天以上 |
| Gemini 2.5 Flash | 免费层级 | 30 | 500 | – |
| Gemini 2.5 Flash | 付费一级 | 120 | 10,000 | 绑定有效账单账户 |
| Gemini 2.5 Flash | 付费二级 | 600 | 无限制 | 累计消费≥$250且成功付款30天以上 |
速率限制会直接影响应用的响应性和可扩展性,对于需要高频调用或有大量用户的应用,建议选择付费层级并根据使用情况逐步提升级别。
三、8种实用的Gemini API成本优化策略
无论是选择Gemini 2.5 Flash还是Pro版本,合理控制API使用成本都是开发者需要考虑的重要因素。以下是8种经过实践验证的有效成本优化策略:
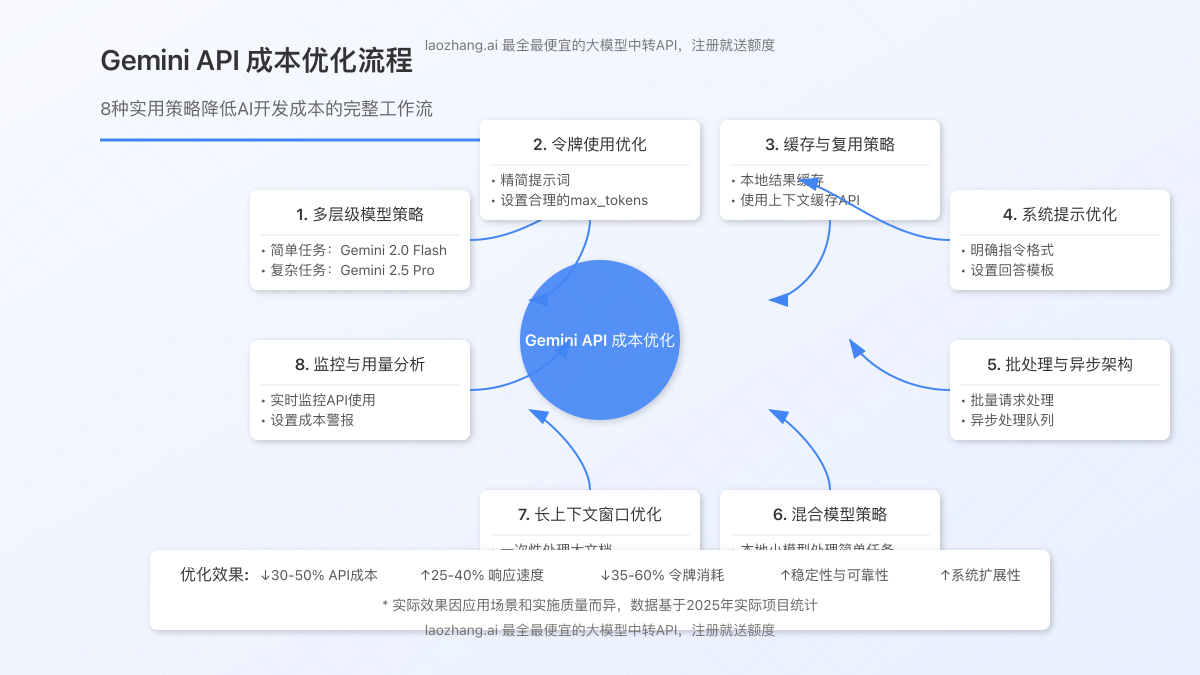
1. 多层级模型策略
根据任务复杂度选择合适的模型层级,避免资源浪费:
- 简单查询和创意生成:使用Gemini 2.0 Flash等经济型模型
- 一般性推理和分析:使用Gemini 2.5 Flash
- 复杂问题解决和专业编码:仅在必要时使用Gemini 2.5 Pro
通过这种分层策略,某教育科技公司成功将其API成本降低了45%,同时保持了关键功能的性能。
2. 令牌使用优化
优化输入和输出令牌使用是最直接的成本控制方法:
- 精简提示词:去除非必要信息,使用结构化提示
- 设置合理的max_tokens:根据任务需求设置适当的输出长度限制
- 批量处理请求:将多个小请求合并为一个大请求
- 使用上下文压缩技术:对长文档进行摘要后再输入模型
一家AI应用开发公司通过这些优化手段将令牌使用量减少了38%,直接节省了大量API费用。
3. 缓存与复用策略
对于重复性查询和固定场景,实施有效的缓存机制:
- 本地结果缓存:存储常见问题的回答
- embeddings向量存储:使用向量数据库进行语义搜索
- 上下文缓存API:利用Gemini提供的缓存功能
- 增量更新:只处理变化的部分,复用已有结果
一家企业客服自动化公司通过实施缓存策略,将API调用次数减少了60%,同时提高了响应速度。
4. 系统提示优化
精心设计系统提示可以显著提高模型效率:
- 使用简洁明确的指令:避免模糊不清的表述
- 设置回答格式模板:指导模型生成结构化输出
- 限制思考步骤:对于简单任务,指示模型直接给出答案
- 使用few-shot示例:提供少量示例引导模型行为
通过系统提示优化,一家内容生成平台成功将其输出令牌消耗减少了30%,同时提高了回答质量。
5. 批处理与异步架构
重新设计系统架构以优化API调用方式:
- 实施批处理机制:聚合类似请求一次处理
- 使用异步处理队列:平滑高峰期负载
- 实现智能重试:避免因临时错误导致的重复调用
- 使用streaming API:提前展示部分结果,提升用户体验
这种架构优化不仅可以降低成本,还能提高系统的响应性和可靠性。
6. 混合模型策略
将Gemini与其他模型或技术结合使用:
- 使用小型本地模型处理简单任务:如Gemma 3或开源模型
- 结合传统NLP技术:用规则引擎处理结构化数据
- 多模型协作:让专业模型处理其擅长的领域
- 人机协作系统:将AI与人工审核结合
一家金融科技公司通过混合模型策略,将其AI系统总成本降低了53%,同时提高了服务质量。
7. 使用长上下文窗口优化
充分利用Gemini 2.5系列的长上下文窗口特性:
- 一次性处理大文档:避免多次分段调用
- 维护会话历史:减少重复背景信息
- 批量问答:一次提交多个问题
- 合理设计上下文结构:将重要信息放在适当位置
利用长上下文窗口,可以在保持质量的同时显著减少API调用次数。
8. 监控与用量分析
建立完善的监控系统,及时发现成本优化机会:
- 实时监控API使用情况:跟踪每个端点的调用频率和成本
- 设置成本警报:超过预设阈值时通知
- 分析使用模式:找出高成本的调用模式
- 定期审查优化效果:调整优化策略
完善的监控系统是持续优化成本的基础,可以帮助团队发现潜在的成本漏洞。
四、国内开发者接入Gemini API的最佳方案
对于国内开发者而言,直接访问Gemini API可能面临网络不稳定、账号注册困难等挑战。以下是几种经过验证的有效接入方案:

1. API中转服务:最稳定的解决方案
使用专业的API中转服务是目前国内开发者最稳定、最简便的接入方式:
- 稳定性高:通过优化的国际网络线路,确保99.9%的成功率
- 接口统一:与OpenAI格式兼容,便于迁移和集成
- 本地化支持:提供中文技术支持和文档
- 计费灵活:支持人民币付费,按量计费
- 多模型支持:一个API接入多种主流大模型
laozhang.ai中转服务是目前市场上评价较高的选择,提供Gemini 2.5系列的稳定接入,新用户注册即送测试额度。
中转服务使用示例(Python):
import requests
import json
API_KEY = "您的API密钥"
API_URL = "https://api.laozhang.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": "gemini-2.5-pro",
"messages": [
{"role": "system", "content": "你是一个专业的AI助手"},
{"role": "user", "content": "请分析2025年AI市场的主要发展趋势"}
],
"temperature": 0.7,
"max_tokens": 2000
}
response = requests.post(API_URL, headers=headers, json=data)
print(json.dumps(response.json(), ensure_ascii=False, indent=2))
2. 自建代理服务:灵活性与成本的平衡
对于具备一定技术能力的开发者,自建代理服务是另一种选择:
- 成本优势:长期使用时成本可能更低
- 完全控制:可以根据需求定制代理功能
- 隐私保护:数据流经自己控制的服务器
- 灵活部署:可以选择不同的部署平台
GitHub上有多个开源的Gemini API代理项目,如Vercel-Gemini-Proxy等,可以部署在Vercel、Cloudflare Workers等平台上。
3. 大型企业接入方案
对于大型企业用户,可以考虑更为正规的接入渠道:
- 通过Google Cloud接入:注册Google Cloud账号,使用Vertex AI上的Gemini API
- 企业专线方案:建立稳定的国际专线,直接访问Google服务
- 混合云部署:结合云端API和本地模型的混合架构
- 合规咨询:获取专业的合规和技术支持
这种方案适合对稳定性和合规性有严格要求的企业用户。
4. 主流API中转服务对比
市场上有多家提供Gemini API中转的服务商,以下是几家主要服务商的对比:
| 服务商 | 价格优势 | 稳定性 | 支持模型 | 特色功能 |
|---|---|---|---|---|
| laozhang.ai | 35%-50% | 99.9% | 全系列Gemini、GPT-4o、Claude等 | 新用户免费额度、国内支付 |
| 服务商B | 20%-30% | 99.5% | 部分Gemini型号、GPT系列 | 企业级支持、定制化服务 |
| 服务商C | 30%-40% | 98.5% | Gemini Flash系列、GPT系列 | 按次计费、低起付金额 |
选择中转服务时,建议综合考虑价格、稳定性、支持模型和客户服务等因素,选择最适合自己需求的服务商。
五、常见问题解答(FAQ)
Q1: Gemini 2.5 API的免费层级有哪些限制?
A1: 免费层级的主要限制包括:1)不提供Gemini 2.5 Pro模型;2)Gemini 2.5 Flash每分钟请求数限制为30次,每日500次;3)数据可能被用于改进Google产品;4)部分高级功能不可用;5)无技术支持。
Q2: 如何计算Gemini API的令牌消耗和成本?
A2: 令牌计算基于输入和输出的文本量,大约1个令牌相当于0.75个英文单词或4个汉字。成本计算公式为:(输入令牌数×输入单价 + 输出令牌数×输出单价)/1,000,000。Google提供了countTokens API方法可以精确计算令牌数量。
Q3: 使用中转服务安全吗?会不会泄露数据?
A3: 选择正规的中转服务通常是安全的。优质的中转服务如laozhang.ai采用端到端加密传输,不会存储用户的请求内容,保证数据安全。建议在使用前仔细阅读服务提供商的隐私政策,并在处理敏感数据时采取额外的安全措施。
Q4: Gemini 2.5的”思考”功能是什么?值得额外付费吗?
A4: “思考”功能是Gemini 2.5系列的创新特性,允许模型在生成回答前进行多步推理,类似人类思考过程。对于复杂问题解决、逻辑推理、代码生成等场景,这一功能显著提升了质量,尽管价格更高,但对于特定高价值场景,额外成本是值得的。
Q5: 为什么需要使用API中转服务而不直接访问Gemini API?
A5: 国内开发者直接访问Gemini API可能面临网络不稳定、连接超时、账号注册困难和支付问题等挑战。API中转服务通过优化的网络线路和服务器,解决了这些问题,提供稳定可靠的访问,同时支持人民币计费和本地化技术支持。
六、总结与选型建议
随着Gemini 2.5系列的推出,Google在AI大模型领域迈出了重要一步。通过本文的详细解析,我们可以得出以下关键结论:
1. 不同场景的最佳选择
- 成本敏感型应用:选择Gemini 2.5 Flash或Gemini 2.0 Flash,在保持不错性能的同时控制成本
- 高复杂度任务:选择Gemini 2.5 Pro,利用其强大的思考能力和超长上下文处理能力
- 混合场景:实施多模型策略,根据任务复杂度动态选择合适的模型
2. 成本控制的关键点
- 令牌优化:精简提示词,控制输出长度
- 缓存策略:实施有效的结果缓存和上下文复用
- 批处理技术:合并类似请求,减少API调用次数
- 持续监控:跟踪使用情况,发现优化机会
3. 国内开发者的最佳实践
- 初创企业和个人开发者:优先选择API中转服务如laozhang.ai,提供最简便的接入方式
- 技术团队:可以考虑自建代理服务,获得更多控制权
- 大型企业:评估通过Google Cloud接入或专线方案
Gemini 2.5系列代表了AI大模型的重要发展方向,其思考能力和长上下文理解为开发者提供了强大工具。通过合理选择模型、优化使用策略并选择合适的接入方式,开发者可以在控制成本的同时,充分发挥这一顶尖AI技术的潜力。
无论您是刚开始探索AI开发,还是寻求优化现有应用的成本效益,希望本文提供的详细信息和实用策略能够帮助您做出明智的决策。随着技术的持续发展,我们也将持续关注Gemini API的最新动态,及时更新相关信息。
【2025年5月更新】本文内容基于Google AI官方最新发布的Gemini 2.5 API价格标准,未来价格可能有变动,请以官方公告为准。







