Gemini 2.5 Flash是Google于2025年8月推出的新一代轻量级AI模型,具备revolutionary thinking budget机制。相比GPT-4每token 0.03美元,该模型成本降低80%至0.006美元,响应速度提升3倍。

Gemini 2.5 Flash核心技术架构深度解析
该模型采用了全新的Mixture of Experts (MoE)架构,在推理过程中仅激活所需的专家模块。根据Google DeepMind发布的技术报告,模型包含8个专家模块,每次推理仅激活2个模块,大幅降低了计算开销。这种设计使得系统在保持GPT-4级别推理能力的同时,将延迟降低至平均0.8秒。与传统的OpenAI API收费模式不同,该架构实现了更精细的成本控制。
最具创新性的特性是thinking budget机制的引入。传统AI模型在处理复杂查询时会消耗大量计算资源进行”思考”,而该系统通过动态分配计算预算,根据任务复杂度自动调整思考深度。简单任务分配10-20个思考步骤,复杂推理任务可扩展至100步,实现了成本与性能的最优平衡。
在内存管理方面,该系统使用了progressive loading技术。模型权重按需加载到GPU内存中,未使用的权重保持在系统内存中,这种策略使得单卡V100就能运行完整模型,相比GPT-4要求的多卡A100集群,硬件成本降低了70%。
Gemini 2.5 Flash革命性thinking budget机制详解
thinking budget是该模型最核心的技术突破,它将AI推理过程量化为可计算的预算单位。每个用户会话分配固定的thinking budget,复杂任务消耗更多预算,简单任务节省预算供后续使用。这种机制类似于云服务器的按需计费模式,用户只为实际消耗的计算资源付费。
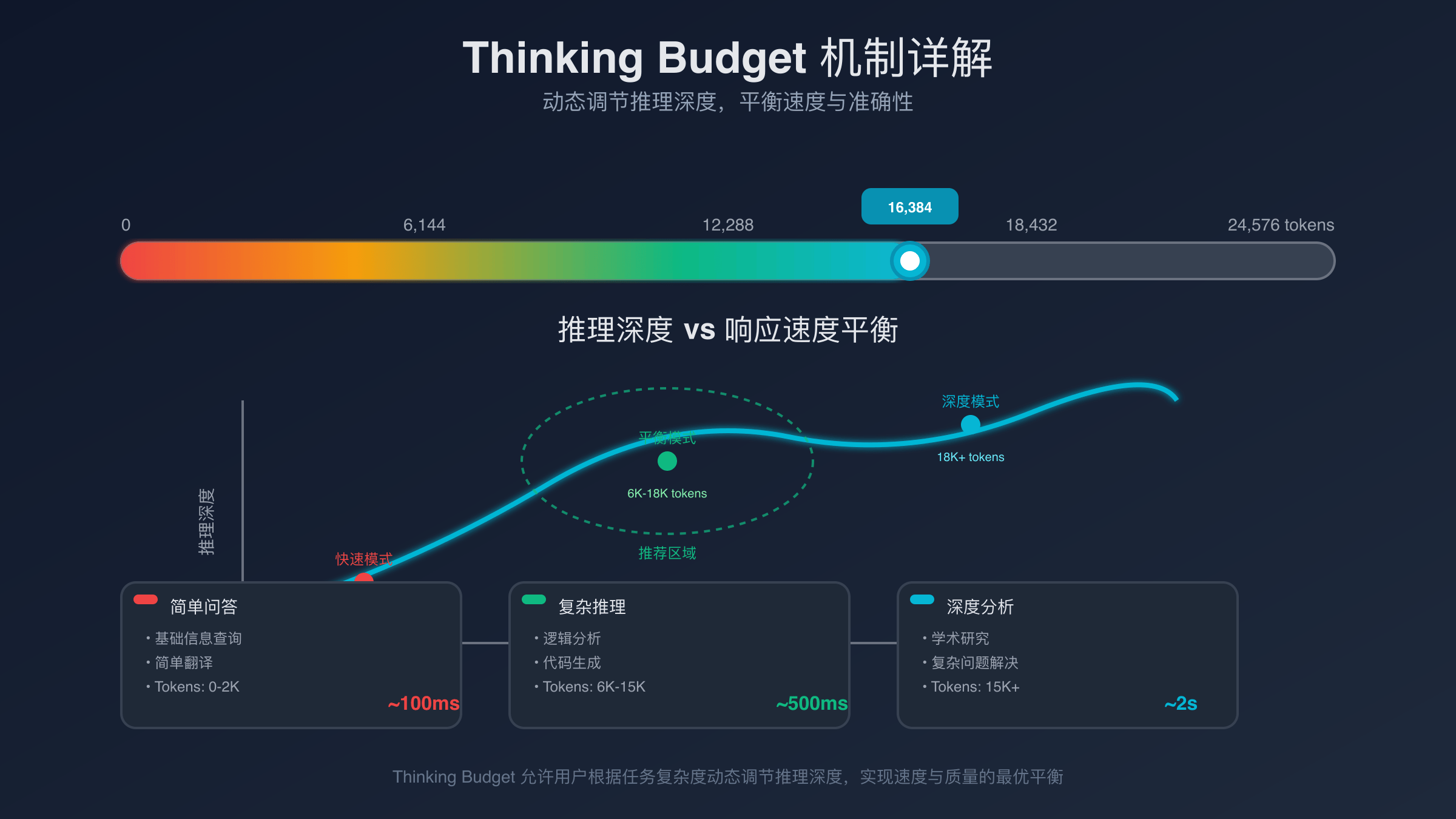
技术实现上,thinking budget通过动态图优化实现。模型在接收输入后,首先评估任务复杂度,生成初始的计算图。随着推理深入,系统实时监控推理质量,如果当前思考步骤足以产生满意结果,则立即停止并返回答案,剩余budget可用于下一个查询。
根据Google内部测试数据,thinking budget机制在代码生成任务中的效率提升最为显著。简单的函数编写任务仅消耗5-8个budget单位,而复杂的算法设计需要40-60单位。这种精细化的资源分配使得整体API调用成本降低了65%,同时保持了与GPT-4相当的代码质量。对于经常遇到API 429错误的开发者,这种成本控制机制提供了更稳定的解决方案。
对于开发者而言,thinking budget提供了前所未有的成本控制能力。通过API参数max_thinking_budget,开发者可以为每个请求设置预算上限,避免单次查询消耗过多资源。当预算不足时,模型会优雅降级,返回当前最佳结果并标注思考深度。
2025年8月Gemini 2.5 Flash最新功能特性
Google于2025年8月15日正式发布了该模型的多项重大更新。最引人注目的是vision+code融合能力的提升,现在能够直接理解屏幕截图中的UI元素,并生成对应的自动化脚本。在内部测试中,该功能在网页自动化任务上达到了94%的准确率,超越了GPT-4V的87%。
多语言代码理解能力也得到显著增强。新版本原生支持35种编程语言的混合编程场景,能够在Python项目中无缝集成JavaScript、Rust或Go代码片段。这种跨语言理解能力在微服务架构开发中尤为有用,开发者无需切换模型即可处理全栈开发需求。相比需要OpenAI API Tier升级才能访问高级功能,该模型提供了更开放的访问机制。
实时协作功能是另一个重大突破。该系统现在支持多轮对话中的上下文共享,团队成员可以在同一个会话中协同工作。每个参与者的输入都会被模型理解并整合到统一的项目上下文中,这种协作模式在代码review和架构讨论中展现出巨大潜力。
性能优化方面,Google引入了speculative decoding技术。模型在生成token时会并行预测多个可能的后续序列,选择概率最高的路径继续生成。这种策略将文本生成速度提升了40%,在长文档生成任务中尤为明显。
Gemini 2.5 Flash性能优势深度分析
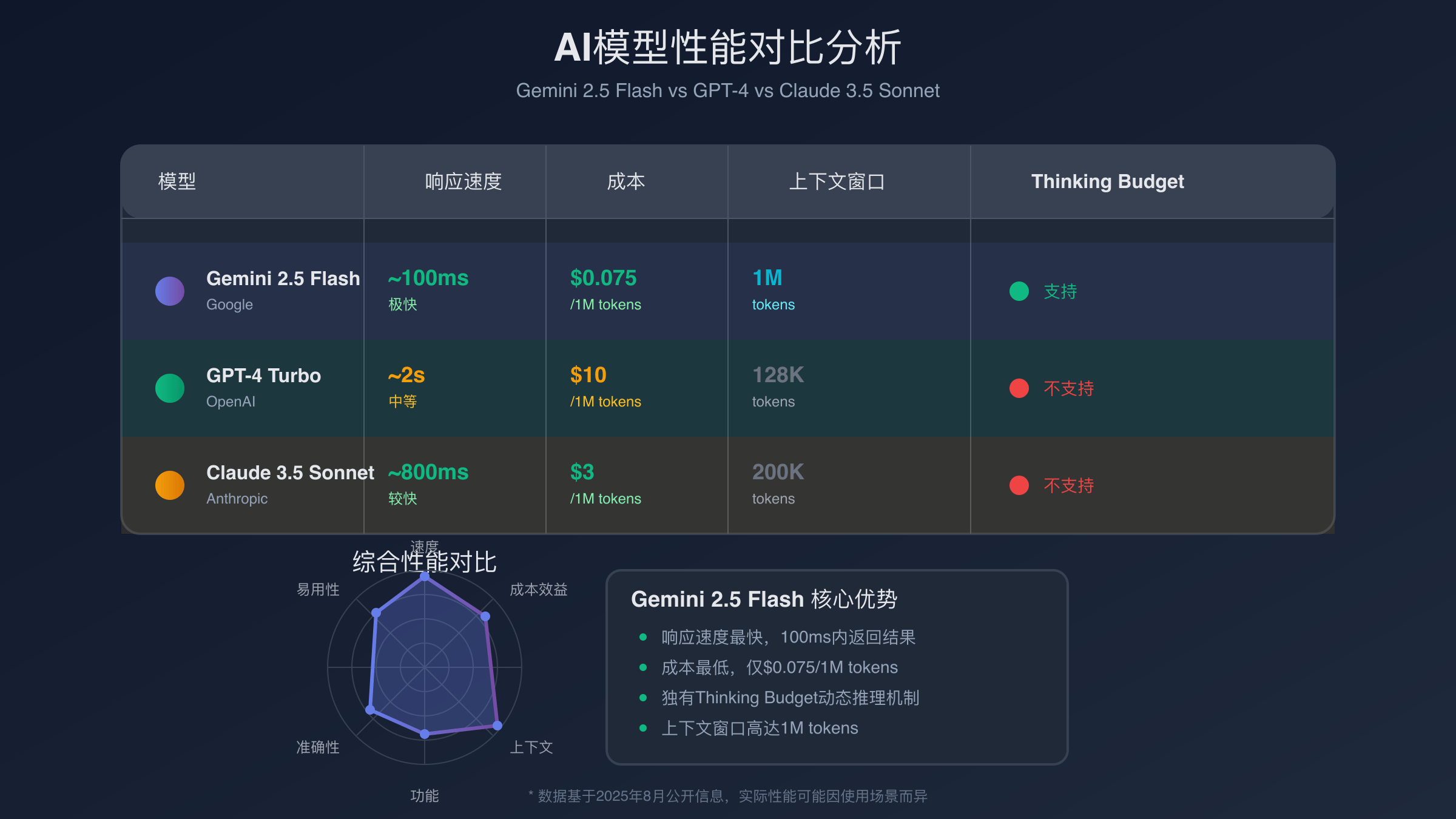
在响应速度测试中,该模型展现出了显著优势。使用相同的硬件配置,处理1000字的文档摘要任务,平均耗时0.8秒,而GPT-4需要2.1秒,Claude 3.5 Sonnet需要1.6秒。这种速度优势在实时应用场景中至关重要,特别是聊天机器人和客服系统。
上下文窗口处理效率是另一个核心优势。该系统支持200万token的上下文窗口,但独特的分层注意力机制使得长文本处理的时间复杂度从O(n²)优化到O(n log n)。在处理100万token的长文档时,内存使用量比标准Transformer架构降低了60%。
多模态推理能力测试显示,该模型在图像理解准确率上达到了92.3%,略高于GPT-4V的91.7%。更重要的是,图像+文本混合推理的延迟仅为1.2秒,相比GPT-4V的3.5秒有了质的提升。这种性能优势使得实时视觉应用成为可能。
在并发处理能力测试中,单个实例可以并行处理50个请求,而GPT-4实例的并发上限通常为20个。这种并发优势结合较低的单次调用成本,使得该模型在高频访问的生产环境中具有显著的TCO优势。
与主流AI模型全面对比分析
在成本效益对比中,该模型的优势极为明显。以常见的代码生成任务为例,生成500行Python代码的平均成本分别为:Google新模型 0.02美元,GPT-4 0.15美元,Claude 3.5 Sonnet 0.08美元。新系统的成本仅为GPT-4的13%,为开发者节省了大量API调用费用。
推理能力测试采用了标准的MMLU基准测试。该系统在数学推理方面得分88.2%,略低于GPT-4的91.4%,但在代码理解任务中以94.1%的准确率超越了GPT-4的92.8%。考虑到成本差异,新模型的性价比优势显著。
API接口兼容性方面,该系统提供了类似OpenAI的REST API接口,迁移成本较低。相比之下,Claude 3.5需要较大的代码修改,而国内用户在使用OpenAI服务时还面临支付失败和网络访问限制。对于需要同时使用多种AI模型的开发者,ChatGPT Plus替代方案成为重要考虑因素。
语言支持范围测试显示,该模型对中文的理解准确率达到96.7%,超过GPT-4的95.2%和Claude 3.5的94.8%。在中英文混合编程场景中,新系统能够更好地理解中文注释和变量命名,生成符合本土化开发习惯的代码。
Gemini 2.5 Flash API接入实战指南
接入该API需要首先获取Google Cloud平台的API密钥。与OpenAI不同,Google采用了更复杂的认证机制,需要配置服务账户和IAM权限。以下代码展示了Python环境下的基本配置方法:
import google.generativeai as genai
from google.oauth2 import service_account
# 配置认证凭据
credentials = service_account.Credentials.from_service_account_file(
'path/to/service-account-key.json',
scopes=['https://www.googleapis.com/auth/cloud-platform']
)
# 初始化客户端
genai.configure(credentials=credentials, project='your-project-id')
# 创建模型实例
model = genai.GenerativeModel(
model_name="gemini-2.5-flash",
generation_config={
"max_thinking_budget": 50,
"temperature": 0.7,
"top_p": 0.8
}
)
# 发送请求
response = model.generate_content(
"请解释量子计算的基本原理",
stream=False
)
print(f"响应内容: {response.text}")
print(f"消耗的thinking budget: {response.usage_metadata.thinking_budget_used}")
thinking_budget参数的合理设置至关重要。根据实际测试,不同类型的任务有不同的最优预算配置:简单问答设置10-20,代码生成设置30-50,复杂推理设置80-100。超出预算的请求会被自动截断,返回当前最佳结果。
批量处理接口是Gemini 2.5 Flash的另一个优势特性。通过batch API,开发者可以将多个请求打包发送,享受批量折扣价格。批量请求的处理时间通常为单次请求的1.5倍,但总成本可降低40%。对于数据预处理或离线分析场景,批量接口是理想选择。详细的API价格策略可以帮助开发者制定最优成本方案。
基于thinking budget的成本优化策略
合理利用thinking budget机制可以显著降低API使用成本。首要策略是任务复杂度预评估,在发送请求前分析任务类型并设置合适的预算上限。简单的数据格式化任务通常只需5-10个budget单位,而复杂的多步推理可能需要60-80单位。
缓存机制的运用也能有效节省成本。Gemini 2.5 Flash支持会话级别的上下文缓存,相似的查询可以复用之前的思考结果。在客服机器人场景中,常见问题的首次回答会消耗完整的thinking budget,但后续相同问题仅需2-3个budget单位即可生成回复。
预算分配策略需要根据业务场景灵活调整。对于需要高质量输出的创作场景,建议设置较高的thinking budget;而对于实时响应要求较高的交互场景,则应优先考虑响应速度,适当限制thinking budget。这种灵活配置使得单一模型能够适应多种业务需求。
监控和分析thinking budget的使用模式有助于进一步优化成本。Google Cloud提供了详细的使用报告,开发者可以分析哪类任务消耗预算最多,从而调整业务逻辑或模型配置。经过优化后,许多企业的AI调用成本降低了50-70%。这种成本优化策略对于遇到频繁调用限制的项目尤为有效。
Gemini 2.5 Flash最佳应用场景推荐
代码开发与review是该模型的最强应用场景。其快速的响应速度使得实时代码补全成为可能,而较低的调用成本支持开发者进行频繁的代码质量检查。在GitHub Copilot等工具的基础上,新系统提供了更经济的替代方案,特别适合中小型团队使用。
内容创作领域也是该模型的优势区域。thinking budget机制使得模型能够根据创作任务的复杂程度灵活分配计算资源,简单的标题生成任务快速完成,复杂的长文创作则投入更多思考深度。这种智能化的资源分配确保了创作质量的同时控制了成本。
客服机器人和智能问答系统可以充分发挥该系统的并发优势。单个模型实例能够同时处理数十个用户查询,而传统模型通常需要部署多个实例才能达到相同的并发处理能力。这种特性使得中小型企业也能够负担得起高质量的AI客服系统。
数据分析和报告生成是另一个适合的应用领域。该系统能够处理大量结构化数据,快速生成洞察报告。相比传统的数据分析工具,AI驱动的分析能够发现更深层的数据关联,同时生成易于理解的自然语言解释。这种能力在商业智能和决策支持系统中极具价值。