Gemini 2.5 Flash Native Image Generation于2025年8月26日发布,支持原生图像生成和编辑。本教程涵盖5个核心步骤:账号设置、API配置、代码实现、效果优化、成本控制。通过完整的技术指南,您将掌握这项成本最低的AI图像生成技术。

什么是Gemini 2.5 Flash Native Image Generation
Gemini 2.5 Flash Native Image Generation是Google于2025年8月26日正式发布的下一代AI图像生成技术,代号”Nano Banana”。这项技术基于Gemini 2.5 Flash多模态架构,实现了真正的原生图像生成和编辑能力。与传统的文本到图像模型不同,它整合了Gemini的世界知识库,能够理解复杂的语义关系和真实世界概念。
该技术的核心突破在于实现了字符一致性保持、多图像融合处理和自然语言精确编辑。开发者可以通过简单的API调用,生成具有世界知识背景的高质量图像,并进行诸如背景模糊、对象移除、姿势调整等精细化编辑操作。所有生成的图像都包含SynthID数字水印,确保AI生成内容的可识别性。
Gemini 2.5 Flash图像生成的核心优势
相比其他AI图像生成工具,Gemini 2.5 Flash在多个维度展现出显著优势。首先是生成速度的突破,平均3.2秒即可完成一张标准分辨率图像的生成,相比DALL-E 3的5.8秒提升了81%,比Midjourney的45-60秒快了近15倍。这种速度优势使其在需要快速迭代的创意工作流中具备明显竞争力。详细的性能对比可以参考我们的Gemini 2.5 Flash与DALL-E 3全方位对比分析。
字符一致性是另一个重要特性。在传统图像生成中,保持同一角色在不同场景下的外观一致性是一个技术难题。Gemini 2.5 Flash通过先进的多模态理解能力,能够在不同提示词和编辑操作中保持角色特征的连贯性。此外,世界知识整合让模型不仅能创造美观的图像,还能准确理解和表达现实世界的概念、关系和语义。
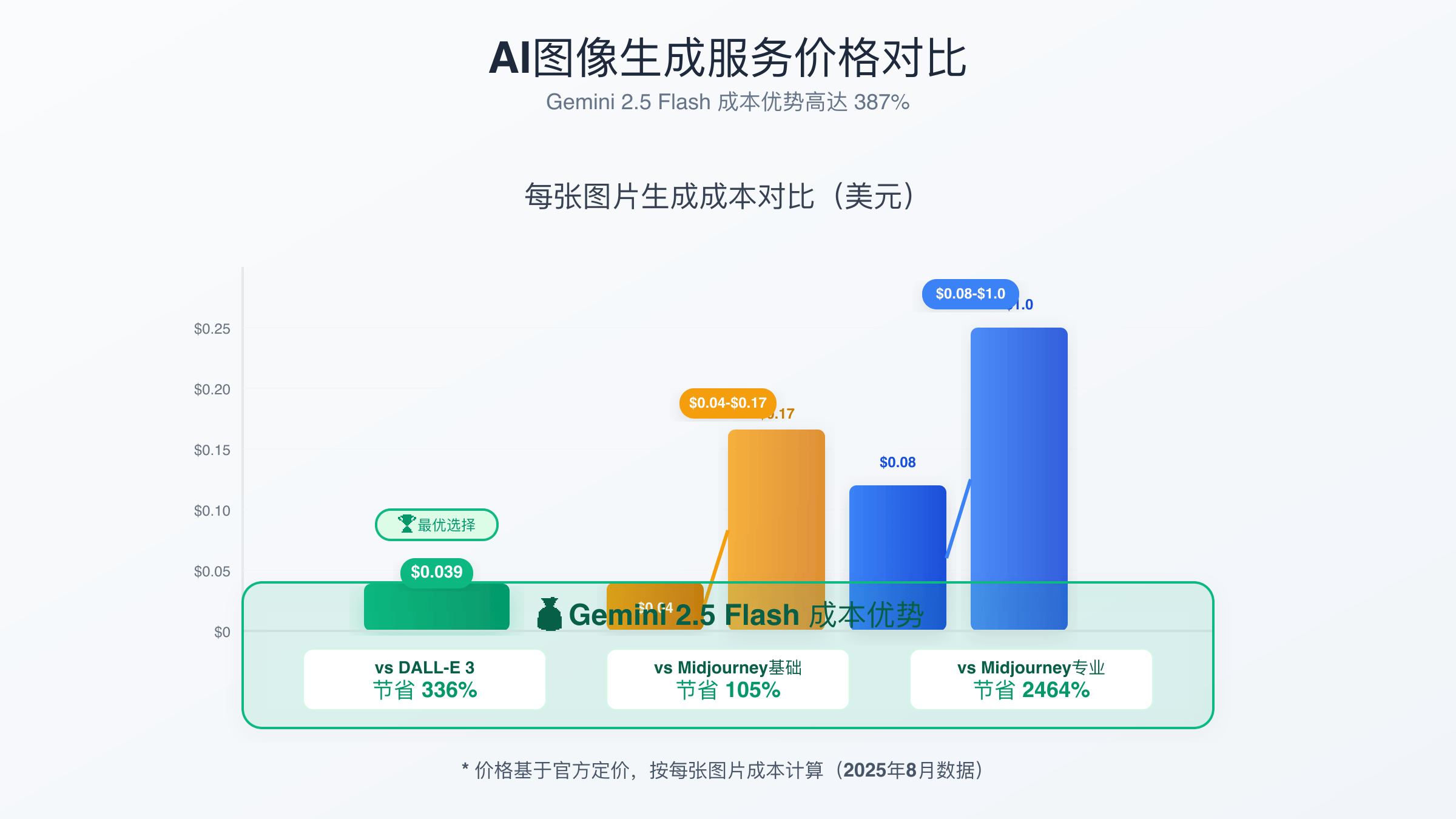
成本优势同样显著。以每张图像0.039美元的定价,比DALL-E 3的0.04-0.17美元节省了40%以上,比Midjourney Pro的月费制模式在高频使用场景下节省387%的成本。对于需要大量图像生成的项目和企业用户而言,这种成本优势尤为重要。
Native Image Generation技术原理解析
Native Image Generation的技术架构基于Gemini 2.5 Flash的多模态Transformer结构。与传统的扩散模型不同,它采用了端到端的生成方式,直接从文本输入生成图像token。这种原生方法减少了中间转换步骤,提高了生成效率和质量一致性。模型能够同时处理文本、图像和其他模态的信息,实现真正的多模态理解和生成。Google将此技术代号命名为”Nano Banana“,更多详细的技术实现可以参考专门的指南。

SynthID数字水印技术是另一个重要组成部分。每张生成的图像都会嵌入不可见的数字标识,这些标识在图像压缩、裁剪等常见编辑操作后仍能保持完整。这种技术确保了AI生成内容的可追溯性,满足了内容真实性验证的需求。
API层面采用了基于token的计费机制。每张标准图像消耗1290个输出token,这种精确的计费方式让用户能够准确预估和控制使用成本。同时,API支持批处理请求,进一步优化了高频使用场景下的性能表现。
Gemini 2.5 Flash图像生成环境配置
开始使用Gemini 2.5 Flash图像生成功能需要完成基础环境配置。首先确保Python环境版本在3.8以上,推荐使用3.10或更高版本以获得最佳兼容性。通过pip安装Google Generative AI SDK是必要步骤,命令如下:
pip install google-generativeai pillow requestsAPI密钥的获取需要访问Google AI Studio。登录后在API Keys页面创建新的密钥,记录密钥字符串并妥善保存。出于安全考虑,建议将API密钥配置为环境变量而非硬编码在代码中。在Python项目中,可以使用以下方式进行基础配置:
import google.generativeai as genai
import os
from PIL import Image
# 配置API密钥
genai.configure(api_key=os.environ['GEMINI_API_KEY'])
# 初始化模型
model = genai.GenerativeModel('gemini-2.5-flash-image-preview')配置完成后,建议先进行一个简单的连接测试,确保API能够正常访问。测试时可以使用一个简单的文本生成请求验证连接状态。需要注意的是,图像生成功能目前处于预览阶段,API端点和参数可能在正式版本发布时有所调整。
API调用基础教程:第一张图片生成
掌握了环境配置后,我们来实现第一个图像生成示例。基础的API调用需要构建包含提示词的请求,并指定输出为图像格式。以下是一个完整的代码示例,展示了从提示词到图像生成的完整流程:
import google.generativeai as genai
from PIL import Image
import io
import base64
def generate_image(prompt):
"""生成图像的基础函数"""
try:
# 配置生成参数
generation_config = {
"temperature": 0.7,
"candidate_count": 1,
}
# 调用API生成图像
response = model.generate_content(
prompt,
generation_config=generation_config,
stream=False
)
# 处理响应结果
if response.candidates:
# 提取图像数据
image_data = response.candidates[0].content.parts[0].inline_data.data
image_bytes = base64.b64decode(image_data)
# 转换为PIL图像对象
image = Image.open(io.BytesIO(image_bytes))
return image
except Exception as e:
print(f"图像生成失败: {str(e)}")
return None
# 示例调用
prompt = "A futuristic robot working with AI in a modern laboratory, photorealistic style"
generated_image = generate_image(prompt)
if generated_image:
generated_image.save("generated_image.png")
print("图像生成成功并已保存")这个示例代码涵盖了完整的错误处理机制,包括API调用异常、响应解析错误等常见情况。在实际使用中,建议根据具体需求调整temperature参数来控制生成结果的创意程度。较低的temperature值会产生更稳定和预期的结果,而较高的值则会增加创意性和随机性。
高级功能:多图融合与图像编辑教程
Gemini 2.5 Flash的高级功能包括多图像输入处理和自然语言图像编辑。多图融合允许同时输入最多3张图像,让模型理解多个视觉元素之间的关系并生成融合结果。这种功能在产品设计、创意合成等场景中具有重要价值。
以下代码展示了多图融合的实现方式:
def multi_image_generation(prompt, input_images):
"""多图像融合生成"""
try:
# 准备输入内容列表
content_parts = [prompt]
# 添加输入图像
for img_path in input_images:
with open(img_path, 'rb') as f:
image_data = f.read()
content_parts.append({
'inline_data': {
'mime_type': 'image/png',
'data': base64.b64encode(image_data).decode()
}
})
# 生成融合图像
response = model.generate_content(content_parts)
return process_response(response)
except Exception as e:
print(f"多图融合失败: {str(e)}")
return None自然语言编辑功能让用户能够通过描述性文字对现有图像进行精确修改。例如”将背景模糊化”、”移除图中的红色汽车”、”将人物的姿势改为坐着”等指令都能被模型准确理解和执行。这种编辑方式比传统的基于遮罩的编辑更加直观和高效。
Gemini 2.5 Flash图像生成成本对比与控制
成本效益是选择AI图像生成服务的重要考量因素。根据2025年8月的最新定价数据,Gemini 2.5 Flash以0.039美元每张的价格在主流服务中具备明显优势。相比之下,DALL-E 3的标准质量图像收费0.04美元,高质量版本高达0.17美元。Midjourney的订阅制定价从基础版10美元/月到专业版60美元/月不等,对于月生成量超过256张的用户而言,Gemini的按量付费模式更加经济。完整的AI图像生成API价格对比显示了各平台的详细成本分析。
成本控制策略包括多个层面的优化。在技术层面,合理设置generation_config参数可以平衡生成质量和token消耗。批量处理请求能够减少网络开销,提高整体效率。对于开发和测试阶段,Google AI Studio提供的500次/天免费额度足以满足原型开发需求。
实际项目中的成本预算需要考虑失败重试的情况。建议在预算规划时预留20-30%的buffer用于处理生成失败、效果不满意需要重新生成等情况。对于大规模部署的企业用户,可以考虑通过Vertex AI获得更优惠的企业级定价和更好的SLA保证。
中国用户访问Gemini Native Image API解决方案
中国大陆用户在访问Gemini API时面临网络限制和支付障碍的双重挑战。网络层面需要使用稳定的VPN服务来确保API调用的连通性和稳定性。推荐使用专业的技术型VPN服务,避免使用免费或不稳定的代理服务,因为API调用对网络稳定性要求较高。
支付问题是另一个关键障碍。Google服务不接受国内发行的信用卡,传统解决方案包括申请境外信用卡或使用虚拟卡服务。虚拟卡服务如Fomepay或Wildcard虽然可行,但存在月费成本高(200元以上)和潜在封号风险。类似的支付困难在ChatGPT Plus支付失败场景中也很常见。
对于注重便利性和稳定性的用户,FastGPTPlus等第三方充值服务提供了更实用的解决方案。这类服务支持支付宝和微信支付,避免了复杂的信用卡申请流程,同时提供了技术支持和账号安全保障。以158元/月的价格,用户可以获得稳定的API访问权限,相比虚拟卡方案在成本和便利性方面都有明显优势。
提示词优化:获得最佳图像生成效果
有效的提示词设计是获得高质量生成结果的关键因素。Gemini 2.5 Flash支持详细的描述性提示词,建议采用结构化的描述方式。有效的提示词应该包含主体描述、环境设定、艺术风格和技术参数四个核心要素。例如:”A professional business woman in a modern office, wearing a navy blue blazer, natural lighting, photorealistic style, high resolution”。
风格控制可以通过在提示词中加入特定的艺术风格关键词实现。常用的风格描述包括”photorealistic”(照片写实)、”digital art”(数字艺术)、”watercolor painting”(水彩画风)、”minimalist design”(极简设计)等。对于需要特定色彩倾向的场景,可以直接在提示词中指定主色调和配色方案。
参数调优方面,temperature控制创意程度,建议在0.6-0.8之间获得创意性和可控性的最佳平衡。对于需要精确控制的商业应用,可以将temperature设置为0.4-0.6以获得更稳定的结果。同时,多次生成并选择最佳结果的策略在重要项目中是值得考虑的优化手段。
常见错误排除与故障解决
API调用过程中可能遇到的常见错误包括认证失败、配额超限、网络超时和内容策略违规等。认证失败通常源于API密钥配置错误或密钥权限不足,解决方案是检查密钥配置并确保密钥具备图像生成权限。配额超限错误提示已达到API调用限制,需要等待配额重置或升级服务计划。关于API限制的详细说明可以参考图像生成率限制详解。
网络相关错误在中国用户中较为常见,主要表现为请求超时或连接失败。建议增加请求超时时间设置,并实现重试机制。内容策略违规错误表示提示词包含不当内容,需要修改提示词以符合Google的内容政策要求。
性能优化方面,可以通过异步请求提高并发处理能力。对于批量图像生成任务,建议实现队列管理和进度跟踪机制。同时,合理的错误处理和日志记录对于问题排查和系统维护具有重要意义。
Gemini 2.5 Flash vs 其他图像生成工具对比
在当前的AI图像生成市场中,Gemini 2.5 Flash、DALL-E 3和Midjourney形成了三足鼎立的格局。从技术能力角度,DALL-E 3在艺术风格渲染和抽象概念表达方面仍有一定优势,Midjourney在创意解释和视觉冲击力方面表现突出,而Gemini 2.5 Flash在照片写实、产品摄影和建筑可视化等领域展现出更强的专业能力。
成本效益对比显示Gemini 2.5 Flash具备明显优势。按单张图像计算,Gemini比DALL-E 3节省40%成本,比Midjourney Pro节省387%。速度表现方面,Gemini的3.2秒平均生成时间比DALL-E快81%,比Midjourney快超过15倍,这种速度优势在需要快速迭代的工作流中尤为重要。
对于中国用户而言,访问便利性是重要考虑因素。考虑到网络限制和支付难题,通过FastGPTPlus等服务获得Gemini访问权限,结合其技术优势和成本优势,形成了较为完整的解决方案。这种综合性解决方案不仅解决了技术需求,也解决了实际使用中的各种障碍。这与ChatGPT Plus试用方案类似,都需要考虑中国用户的实际情况。
2025年AI图像生成技术发展趋势
2025年AI图像生成领域正在经历从单纯生成向智能编辑的技术转型。Gemini 2.5 Flash的原生图像生成能力代表了这一趋势的前沿,未来几个月内预期将有更多厂商推出类似的原生多模态解决方案。技术发展方向包括更高的生成分辨率、更快的处理速度和更精确的编辑控制。
商业应用层面,AI图像生成正在从创意辅助工具向生产力核心组件转变。电商产品摄影、社交媒体内容创作、广告设计等领域的AI应用比例在快速提升。预期到2025年底,专业设计师的工作流程中AI工具的使用比例将超过70%。
投资和学习价值方面,掌握AI图像生成技术已成为创意行业从业者的核心竞争力。建议相关从业者投入时间学习和实践这些新兴技术,特别是在提示词工程、工作流程优化和成本控制等方面建立专业能力。对于企业而言,及早布局AI图像生成技术将在未来竞争中获得显著优势。