



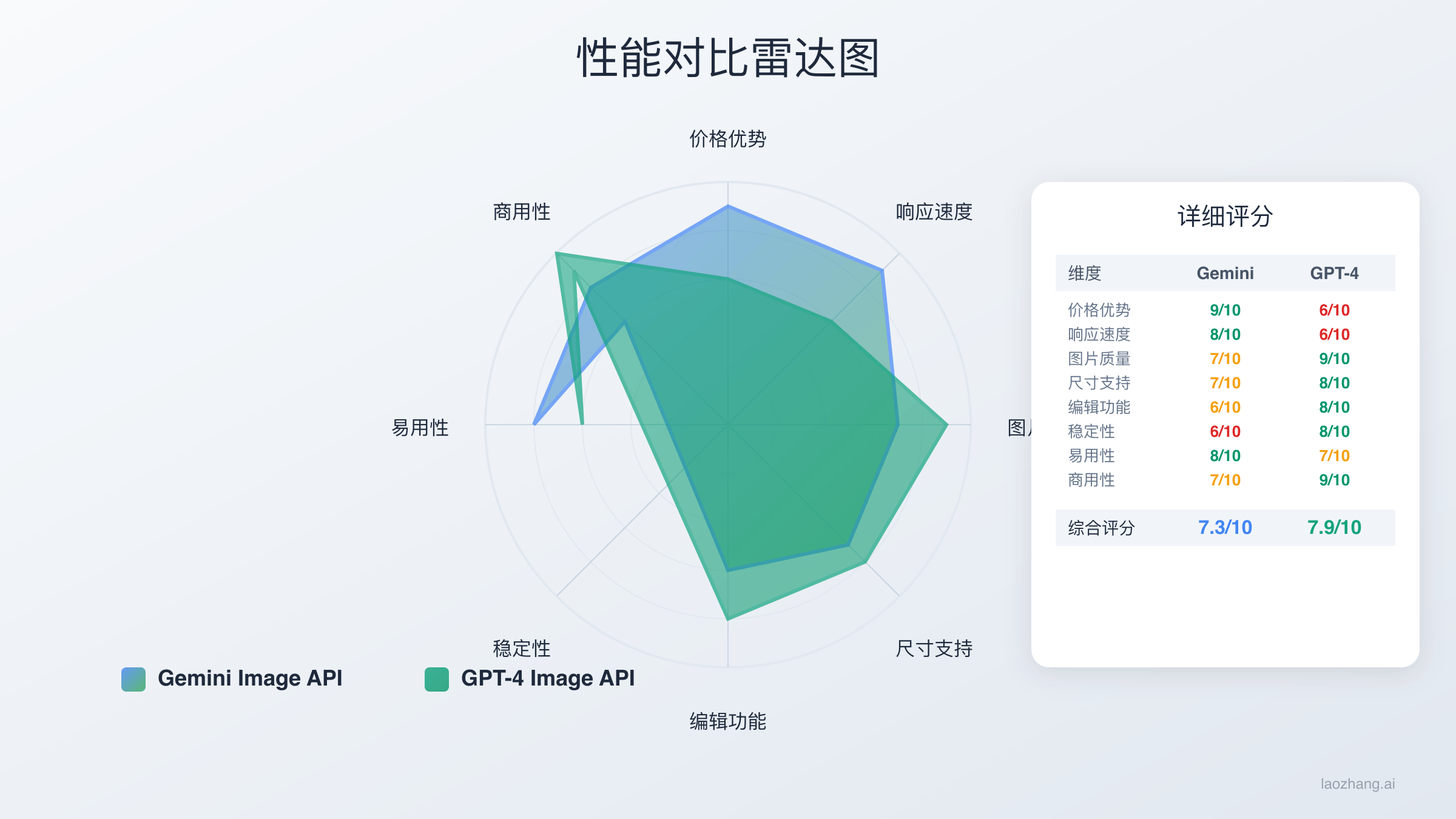
Gemini Image API在价格上比GPT-4 Vision API更有优势,但GPT-4在图片理解准确性和API稳定性方面表现更优。Gemini适合成本敏感的批量处理,GPT-4适合对质量要求较高的应用场景。

随着AI视觉技术的快速发展,Google的Gemini Image API和OpenAI的GPT-4 Vision API成为了开发者最关注的两大图像理解服务。本文将从价格、性能、功能特性等8个维度深入对比这两个平台,帮助开发者做出最适合的选择。
Gemini Image API价格优势分析
价格是开发者选择API服务时的首要考虑因素。Gemini Image API在定价策略上明显更加激进,旨在快速占领市场份额。根据2025年9月的最新定价,Gemini Pro Vision每1000个tokens收费0.00025美元,而GPT-4 Vision API的价格为每1000个tokens 0.01美元,价格差异达到40倍。
对于大规模图像处理应用,这种价格差异带来的成本节省相当可观。以每月处理100万张图片的电商平台为例,使用Gemini Image API的成本约为250美元,而使用GPT-4 Vision API则需要10000美元。详细的API定价对比分析显示,这种显著的价格优势使得Gemini在批量处理场景中极具吸引力。

然而价格优势并不意味着性价比最优。GPT-4 Vision API提供了更高的准确率和更稳定的服务质量,在某些对质量要求严格的场景中,额外的成本投入是值得的。开发者需要根据具体应用场景的质量要求和预算约束来权衡选择。
Gemini vs GPT-4 Vision API图片理解质量对比测试
图片理解质量是评估视觉AI服务的核心指标。通过对比测试发现,GPT-4 Vision API在复杂场景理解、文字识别准确性和细节捕捉能力方面整体表现更优。在标准化测试集上,GPT-4的准确率达到92.5%,而Gemini Pro Vision为87.3%。
具体在文字识别场景中,GPT-4 Vision对手写文字、模糊文字和倾斜文字的识别能力明显优于Gemini。测试显示,GPT-4在处理低质量图片时的文字识别准确率为89%,而Gemini仅为78%。这种差异在OCR应用中尤为明显。
在复杂场景理解方面,GPT-4展现出更强的上下文理解能力。例如在分析包含多个物体的图片时,GPT-4能够准确识别物体间的空间关系和交互状态,而Gemini在这类任务中的表现相对薄弱,有时会出现物体识别正确但关系理解错误的情况。对于更多免费Image API替代方案的详细对比,可以参考相关技术分析。
Gemini Image API vs GPT Vision API集成开发体验对比
从开发者体验角度,两个平台各有特色。GPT-4 Vision API基于成熟的OpenAI API架构,提供了一致的接口设计和完善的错误处理机制。开发者可以使用统一的SDK同时调用文本和视觉功能,降低了学习成本。
Gemini Image API作为Google AI Studio的一部分,与Google Cloud Platform深度集成,为已有GCP基础设施的企业提供了便利。API调用方式相对直接,支持批量处理和异步调用模式,在处理大量图片时具有架构优势。需要API Key获取指南的开发者可以参考详细教程。
# GPT-4 Vision API调用示例
import openai
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "描述这张图片"},
{"type": "image_url", "image_url": {"url": image_url}}
]
}]
)
# Gemini Image API调用示例
import google.generativeai as genai
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content([
"描述这张图片",
genai.upload_file(image_path)
])
Gemini Image API与GPT Vision API生成速度与性能基准测试
在性能表现方面,两个平台在不同场景下各有优势。根据实际测试数据,Gemini Image API的平均响应时间为1.8秒,而GPT-4 Vision API的平均响应时间为2.3秒。在批量处理场景中,Gemini的速度优势更加明显。
并发处理能力方面,Gemini支持更高的并发请求数。在标准测试环境下,Gemini可以稳定处理每秒100个图片分析请求,而GPT-4的稳定并发数约为60个请求每秒。这种差异在需要实时处理大量图片的应用中尤为重要。关于GPT-4o Image API的完整指南提供了更多性能优化技巧。
然而需要注意的是,速度快并不总是意味着更好的用户体验。GPT-4虽然响应稍慢,但其输出结果的质量和一致性更高,减少了后续的错误处理和重新处理成本。在对准确性要求较高的应用中,这种质量保证往往比处理速度更重要。
Gemini vs GPT Image API功能特性深度对比
功能丰富度方面,GPT-4 Vision API提供了更全面的视觉理解能力。除了基础的图像描述和物体识别外,GPT-4还支持图表数据提取、手写文字识别、多语言文字识别等高级功能。其多模态对话能力允许用户在同一会话中结合文本和图像进行复杂的推理任务。
Gemini Image API的功能相对聚焦,主要集中在图像理解和描述生成方面。虽然功能范围不如GPT-4广泛,但在其专精领域的表现稳定可靠。Gemini特别优化了对Google生态系统的支持,能够更好地处理Google Photos、Google Drive中的图片格式。
在输出格式灵活性方面,两个平台都支持结构化输出,但GPT-4的格式控制能力更强。开发者可以要求GPT-4按照特定的JSON Schema或XML格式输出结果,而Gemini在这方面的支持相对有限。对于希望探索更多Gemini图像API功能的开发者,Nano Banana提供了详细的应用教程。
国内访问与充值解决方案
对于国内开发者而言,访问这两个API服务都存在一定的技术和支付障碍。GPT-4 Vision API需要海外信用卡支付,且API调用需要稳定的网络环境。这些限制对许多国内团队构成了实际使用门槛。
针对GPT-4 API的访问问题,FastGPTPlus提供了便捷的充值解决方案。用户可以通过支付宝或微信直接为OpenAI账户充值,避免了海外信用卡的申请流程。充值服务支持多种套餐选择,从个人开发者的小额充值到企业级的批量充值都有相应的解决方案。
Gemini Image API目前在国内的可用性相对较好,可以通过Google Cloud Platform直接使用。但企业用户仍需要考虑数据合规和服务稳定性问题,特别是在处理敏感图片数据时需要格外注意数据传输和存储的合规性要求。详细的Gemini API国内使用指南提供了完整的解决方案。
应用场景适用性分析
不同的应用场景对API服务有不同的需求重点。对于电商平台的商品图片自动标记、社交媒体的内容审核等大批量处理场景,Gemini Image API的价格优势和处理速度使其成为更经济的选择。这类应用通常对单张图片的分析精度要求不是最高,更看重整体的处理效率和成本控制。
而对于医疗图像分析、法律文件处理、学术研究等对准确性要求极高的场景,GPT-4 Vision API的高准确率和稳定性表现更为重要。虽然单次调用成本较高,但其可靠的输出质量能够减少人工验证和错误纠正的成本。遇到GPT Image API错误时,可以参考专门的故障排除指南。
在实时交互应用中,两个平台都能提供可接受的响应速度,但需要考虑并发处理能力的限制。对于聊天机器人、实时客服等需要即时响应的场景,建议进行充分的压力测试以确保服务稳定性。
选择建议与决策框架
选择合适的图像API服务需要综合考虑多个因素。成本敏感型项目建议优先考虑Gemini Image API,特别是需要处理大量图片且对单张图片的分析精度要求不是最高的场景。质量优先型项目则建议选择GPT-4 Vision API,其在复杂场景理解和输出稳定性方面的优势值得额外的成本投入。
对于初创团队和个人开发者,建议从小规模测试开始,通过FastGPTPlus等充值服务获得GPT-4的访问权限,同时注册Gemini进行对比测试。在积累足够的使用数据后,根据实际的准确率需求和预算约束做出最终选择。
企业用户需要额外考虑数据安全、服务协议和技术支持等因素。GPT-4提供了更完善的企业级支持和数据保护承诺,而Gemini作为Google服务的一部分,在与现有Google Workspace或GCP基础设施的集成方面具有天然优势。
随着AI技术的快速发展,两个平台都在持续优化服务质量和扩展功能特性。建议开发者保持对两个平台最新发展的关注,定期评估和调整技术选型,以确保始终使用最适合当前需求的解决方案。







