2025年3月31日实测有效 – OpenAI推出的GPT-4o模型拥有前所未有的多模态能力,集成了文本、图像、音频处理于一体。本文全面解析GPT-4o API的各项功能、接入方法、参数优化及实战应用,帮助开发者充分发挥这一强大模型的潜力。
一、GPT-4o模型概述与优势
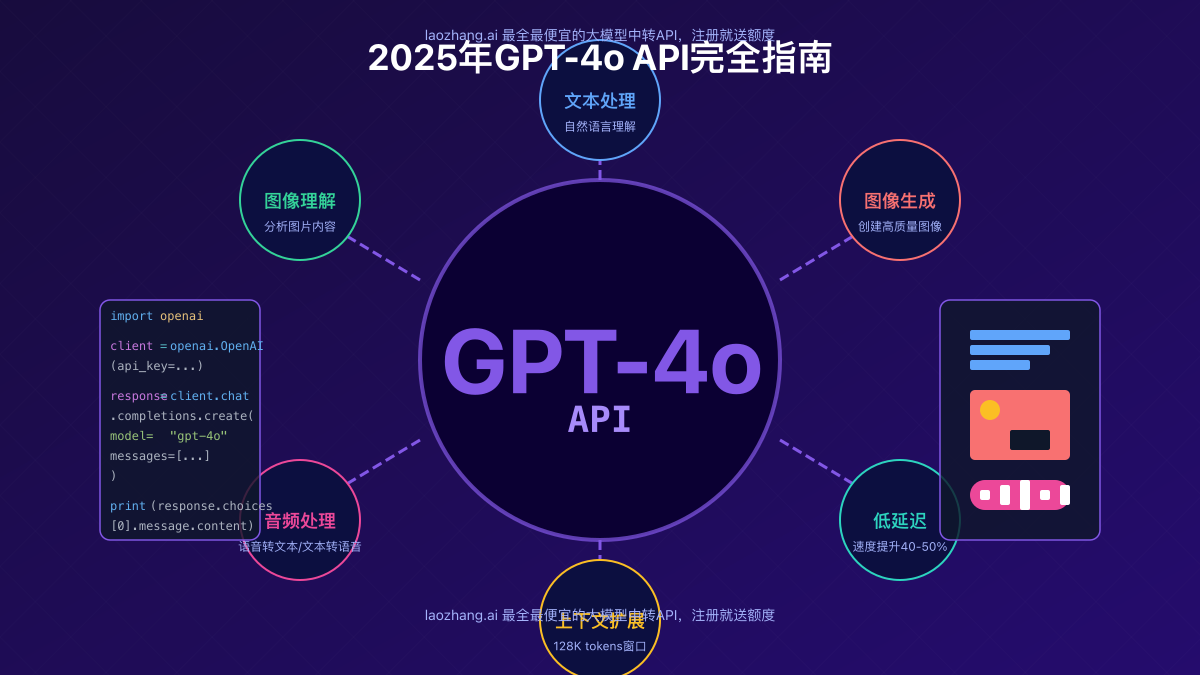
GPT-4o(“o”代表”omni”全能)是OpenAI推出的最新一代多模态大型语言模型,相比前代产品有显著优势:
1. 全面的多模态能力
- 文本处理:更流畅自然的对话与创作能力
- 图像理解:可分析图片内容、识别文字、解读图表与界面
- 图像生成:内置生图能力,无需调用单独的DALL-E API
- 音频处理:文字转语音与语音转文字能力(API预览版已发布)
2. 性能与架构优势
- 响应速度提升40-50%,大幅降低延迟
- 上下文窗口支持128K tokens,可处理更长对话与文档
- 推理成本降低,API调用价格相比GPT-4降低约30-50%
- 更强的跨语言能力与指令理解能力

3. API定价与模型系列
GPT-4o系列目前包含两个主要模型版本:
- GPT-4o:完整版,支持全部多模态能力
- 输入:$5.00/百万tokens
- 输出:$15.00/百万tokens
- GPT-4o-mini:轻量版,保留核心能力但精简参数
- 输入:$0.15/百万tokens
- 输出:$0.60/百万tokens
推荐:通过laozhang.ai中转API服务,可以获得更低成本的GPT-4o API调用。注册链接,新用户注册即送免费额度。
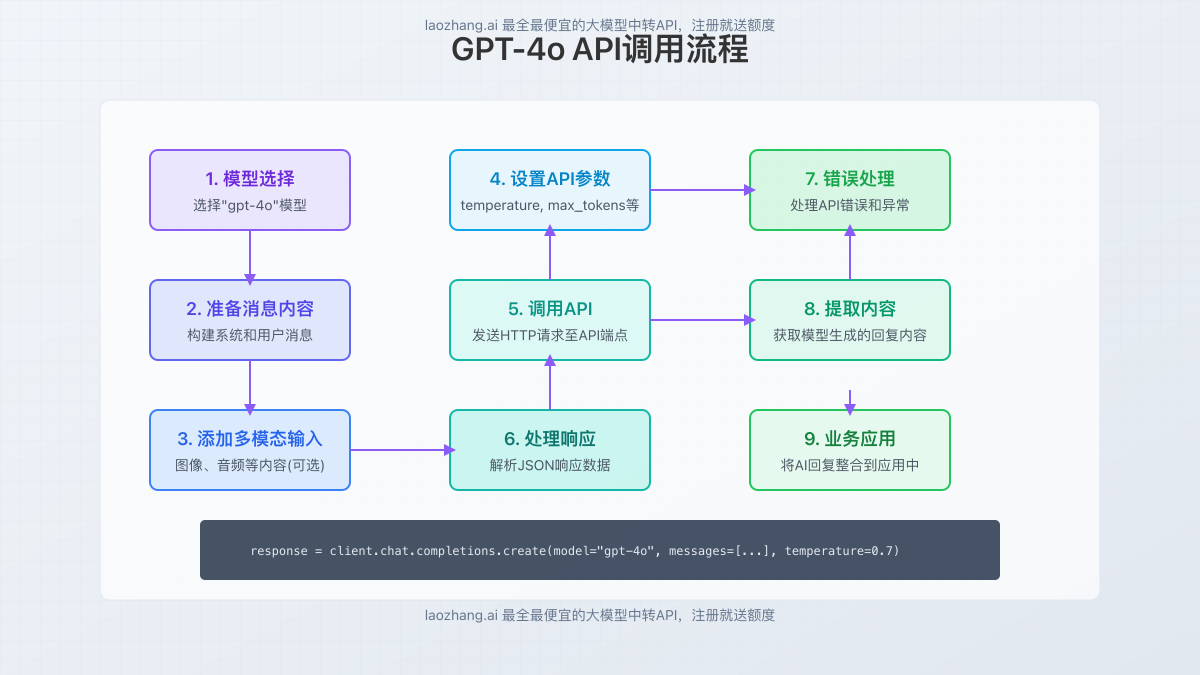
二、GPT-4o API基础调用指南
1. 准备工作与环境设置
在开始使用GPT-4o API前,您需要:
- 注册OpenAI开发者账号或laozhang.ai账号
- 获取API密钥(API Key)
- 安装所需的开发库(如Python中的openai包或requests库)
# Python环境安装openai库
pip install openai
# 或者使用requests库也可以进行API调用
pip install requests
2. 基础文本调用示例
以下是使用Python调用GPT-4o进行基础文本聊天的示例:
# 使用官方OpenAI库调用
import openai
# 设置API密钥和基础URL
client = openai.OpenAI(
api_key="sk-xxx", # 替换为您的API密钥
# 使用官方API时,不需要设置base_url
# 使用laozhang.ai中转API时,设置为:
# base_url="https://api.laozhang.ai/v1"
)
# 调用GPT-4o模型
response = client.chat.completions.create(
model="gpt-4o", # 指定使用GPT-4o模型
messages=[
{"role": "system", "content": "你是一个专业的AI助手,擅长解答技术问题。"},
{"role": "user", "content": "请解释什么是多模态AI模型以及其主要应用场景。"}
],
temperature=0.7, # 控制创造性,0-1之间,越高创造性越强
max_tokens=1000 # 限制回复长度
)
# 输出模型回复
print(response.choices[0].message.content)
3. 使用laozhang.ai中转API
通过laozhang.ai中转API可以更便捷地调用GPT-4o,尤其适合中国大陆地区用户:
# 使用requests库调用laozhang.ai中转API
import requests
import json
# API配置
api_key = "lz_xxx" # 替换为您的laozhang.ai API密钥
api_url = "https://api.laozhang.ai/v1/chat/completions"
# 请求头部
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
# 请求数据
data = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一个专业的AI助手,擅长解答技术问题。"},
{"role": "user", "content": "请解释什么是多模态AI模型以及其主要应用场景。"}
],
"temperature": 0.7,
"max_tokens": 1000
}
# 发送请求
response = requests.post(api_url, headers=headers, json=data)
result = response.json()
# 获取模型回复
if "choices" in result and len(result["choices"]) > 0:
print(result["choices"][0]["message"]["content"])
else:
print(f"请求失败: {result}")
三、GPT-4o多模态功能详解
1. 图像理解能力
GPT-4o可以分析图像并理解图像内容,以下是调用示例:
# 图像理解示例 - 官方SDK
import openai
import base64
# 读取并编码图像
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 获取base64编码的图像
base64_image = encode_image("your_image.jpg")
# 初始化OpenAI客户端
client = openai.OpenAI(api_key="sk-xxx") # 替换为您的API密钥
# 创建带图像的请求
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张图片里有什么内容?详细描述一下。"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}
]
}
],
max_tokens=1000
)
print(response.choices[0].message.content)
2. 图像生成功能
GPT-4o API整合了图像生成功能,不再需要单独调用DALL-E API:
# 图像生成示例 - laozhang.ai API
import requests
import json
api_key = "lz_xxx" # 替换为您的API密钥
api_url = "https://api.laozhang.ai/v1/images/generations"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "gpt-4o", # 使用GPT-4o模型生成图像
"prompt": "一只戴着太阳镜的猫咪,在海滩上冲浪,逼真风格,4K高清",
"n": 1,
"size": "1024x1024",
"quality": "standard",
"style": "vivid" # 可选natural或vivid
}
response = requests.post(api_url, headers=headers, json=data)
result = response.json()
if "data" in result and len(result["data"]) > 0:
image_url = result["data"][0]["url"]
print(f"生成的图像URL: {image_url}")
else:
print(f"生成失败: {result}")
3. 音频处理能力(预览版)
GPT-4o的实时API提供音频处理功能,目前处于预览版状态:
# 文本转语音示例 - 官方SDK
import openai
client = openai.OpenAI(api_key="sk-xxx") # 替换为您的API密钥
response = client.audio.speech.create(
model="gpt-4o", # 注意:实际使用时请确认最新支持的模型名称
voice="alloy", # 可选voice: alloy, echo, fable, onyx, nova, shimmer
input="你好,我是GPT-4o模型。我可以提供多模态智能助手服务,包括文本处理、图像分析和生成等功能。"
)
# 保存为音频文件
response.stream_to_file("output.mp3")
注意:音频功能的API调用方式可能随着正式版发布有所变化,请以OpenAI官方最新文档为准。
四、高级参数与优化技巧

1. 关键参数说明
了解并调整以下参数可以优化GPT-4o API的使用效果:
| 参数名 | 类型 | 说明 | 建议值 |
|---|---|---|---|
| temperature | float | 控制创造性,值越高结果越随机 | 0.2-0.4(事实任务),0.7-0.9(创意任务) |
| top_p | float | 控制词汇多样性,与temperature类似 | 0.9-1.0 |
| max_tokens | integer | 限制回复生成的最大token数 | 根据需求设置,一般1000-4000 |
| frequency_penalty | float | 减少重复短语,值越大越不易重复 | 0.0-0.8 |
| presence_penalty | float | 引入新话题可能性,值越大越容易引入新话题 | 0.0-1.0 |
| seed | integer | 随机种子,用于结果复现 | 任意整数,需要复现时保持一致 |
2. 提升响应速度的技巧
GPT-4o已经比前代模型更快,但您仍可通过以下方法进一步优化速度:
- 使用流式输出(streaming)获取实时反馈
- 减少不必要的上下文内容,仅保留关键信息
- 对于复杂任务,使用并行请求方式
- 针对特定任务微调提示词,减少歧义
# 流式输出示例 - 官方SDK
import openai
client = openai.OpenAI(api_key="sk-xxx") # 替换为您的API密钥
# 启用流式输出
stream = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个专业的AI助手。"},
{"role": "user", "content": "请写一篇关于人工智能发展历史的短文。"}
],
stream=True # 开启流式输出
)
# 逐步获取并输出内容
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
3. 处理长文本与大型上下文
充分利用GPT-4o的128K tokens上下文窗口:
- 分块处理大型文档,保持关键信息连贯
- 对于超长对话历史,使用摘要保留重要内容
- 利用嵌入(embeddings)检索相关知识,减少直接输入
五、GPT-4o API实战应用场景
1. 多模态内容创作平台
结合GPT-4o的文本生成和图像生成能力,可以构建全方位内容创作平台:
- 一键生成配图博客文章
- 根据简单描述创建完整产品介绍
- 自动为文档添加合适的插图
- 创建信息图表和数据可视化
2. 智能文档分析与处理
利用GPT-4o的图像理解能力处理各类文档:
- 识别并提取表格、图表中的数据
- 分析扫描PDF文档内容
- 识别手写笔记并转换为可编辑文本
- 自动分类和标记文档内容
# 文档分析示例
import openai
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 获取base64编码的文档图像
base64_document = encode_image("scanned_document.jpg")
client = openai.OpenAI(api_key="sk-xxx") # 替换为您的API密钥
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这份文档包含哪些关键信息?请提取其中的表格数据并整理成JSON格式。"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_document}"}}
]
}
],
max_tokens=1500
)
print(response.choices[0].message.content)
3. 跨平台智能助手
构建覆盖多种输入输出形式的全能助手:
- 能理解语音、文本、图像的综合指令
- 提供多语言实时翻译与转写
- 以语音、文本或图像形式回复查询
- 辅助视障人士理解视觉内容
六、常见问题与解决方案
问:GPT-4o API与普通的ChatGPT API有什么区别?
答:GPT-4o API是OpenAI最新的多模态API,相比普通ChatGPT API(基于GPT-3.5或GPT-4),主要区别包括:
- 支持图像输入和理解能力,可直接分析图片内容
- 集成了图像生成功能,类似DALL-E但更无缝
- 提供预览版音频功能
- 显著改进的响应速度和效率
- 更大的上下文窗口(128K tokens)
问:如何降低GPT-4o API的使用成本?
答:降低成本的有效方法包括:
- 对非复杂任务,考虑使用GPT-4o-mini,价格仅为完整版的约3%
- 通过laozhang.ai等中转API服务获取更优惠的价格
- 优化提示词,减少不必要的上下文和指令重复
- 使用模型缓存机制,对相似查询复用结果
- 对批量请求,使用异步处理减少API空闲等待
问:GPT-4o API的限制与注意事项有哪些?
答:使用GPT-4o API时,需要注意以下限制:
- 尽管上下文窗口大,但仍有128K tokens的硬性限制
- 图像处理能力强,但复杂图像的细节理解仍有一定局限
- API调用存在速率限制,需要合理设计应用架构
- 处理敏感信息时,注意隐私保护,不要上传包含个人敏感信息的图像或文字
- 对于高并发应用,需实现合理的错误处理和重试机制
七、总结与未来展望
GPT-4o API代表了AI接口技术的重大飞跃,将文本、图像和音频处理能力整合到单一强大的接口中。这为开发者创造了前所未有的可能性,使应用能够更自然地理解和生成多种形式的内容。
随着技术的不断进步,我们可以预期:
- 更深入的多模态整合,可能包括视频理解与生成
- 更精细的多语言与跨文化理解能力
- 更低的延迟和更高效的处理机制
- 专业领域的更深入优化,如医疗、法律、教育等
立即通过laozhang.ai开始体验GPT-4o API,获取更优惠的价格和更稳定的服务,开启您的多模态AI应用之旅。