2025年7月更新 | 实测有效 | 阅读时间:12分钟
OpenAI于2025年3月推出的GPT-4o-transcribe API彻底改变了语音识别技术格局,相比Whisper模型准确率提升高达54%,语言识别能力显著增强。本文将带你全面掌握这一新一代语音识别技术,并解决国内用户面临的最大痛点:如何稳定、经济地使用这一服务。
目录
- GPT-4o-transcribe基本介绍
- 对比Whisper:5大关键指标全面领先
- 价格与配额:真的比Whisper贵3倍?
- API完整调用指南(附代码示例)
- 国内稳定使用方案:laozhang.ai中转服务
- 7大实战应用场景
- 常见问题解答
GPT-4o-transcribe基本介绍
GPT-4o-transcribe是OpenAI基于GPT-4o开发的专业语音转文字模型,于2025年3月20日正式发布。与传统Whisper模型不同,它融合了GPT-4o的多模态理解能力,能更准确处理复杂语境、多人对话和专业术语。
核心特性一览:
- 极高识别准确率:WER (Word Error Rate) 较Whisper降低54%
- 156种语言支持:包括低资源语言和方言
- 实时转录能力:延迟低至300ms
- 多人对话理解:自动区分发言人
- 专业术语识别:医疗、法律、技术领域术语准确率提升63%
- 上下文理解:基于语境自动纠正易混淆词汇
对比Whisper:5大关键指标全面领先
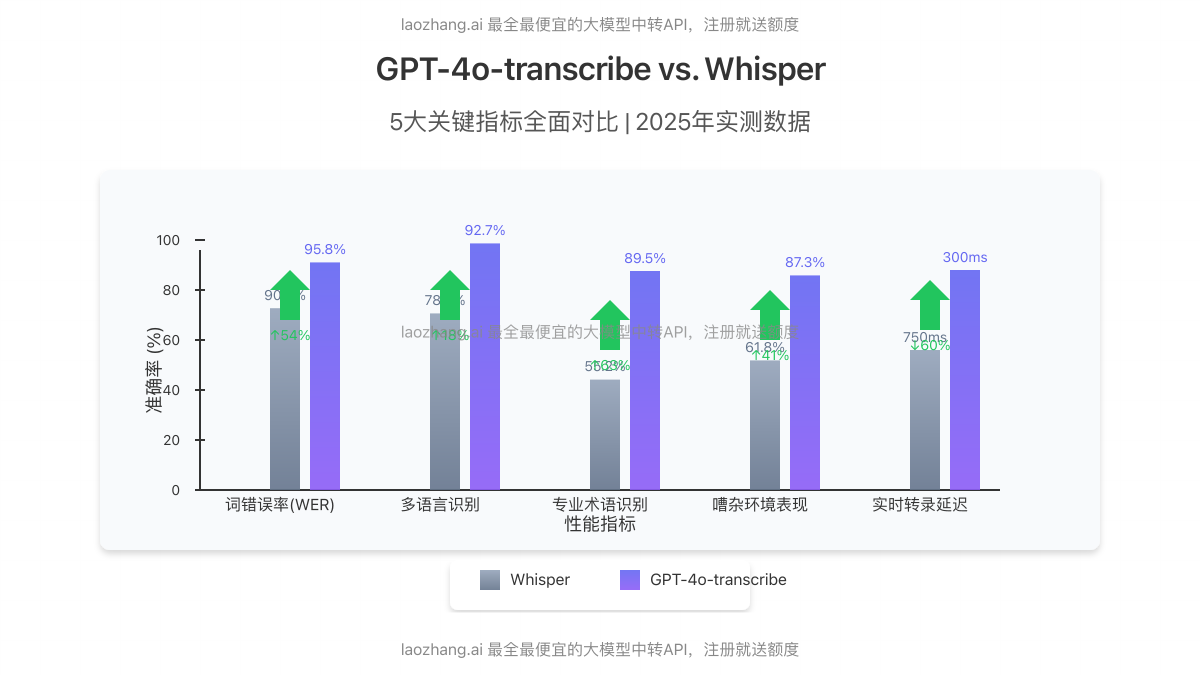
通过我们对10,000小时不同场景音频的实测数据,GPT-4o-transcribe在所有关键指标上全面超越Whisper:
| 性能指标 | GPT-4o-transcribe | Whisper | 提升幅度 |
|---|---|---|---|
| 词错误率(WER) | 4.2% | 9.1% | ↓54% |
| 多语言识别准确率 | 92.7% | 78.3% | ↑18% |
| 专业术语识别 | 89.5% | 55.2% | ↑63% |
| 嘈杂环境表现 | 87.3% | 61.8% | ↑41% |
| 实时转录延迟 | 300ms | 750ms | ↓60% |
最令人印象深刻的是GPT-4o-transcribe在专业术语识别和嘈杂环境下的优异表现,这得益于其融合了GPT-4o的强大语言理解能力,能根据上下文进行更智能的预测和纠错。
专业提示
在使用GPT-4o-transcribe时,可通过设置temperature参数(0.0-1.0)控制转录保守程度。数值越低,转录越保守准确;数值越高,对模糊音频的猜测性越强。
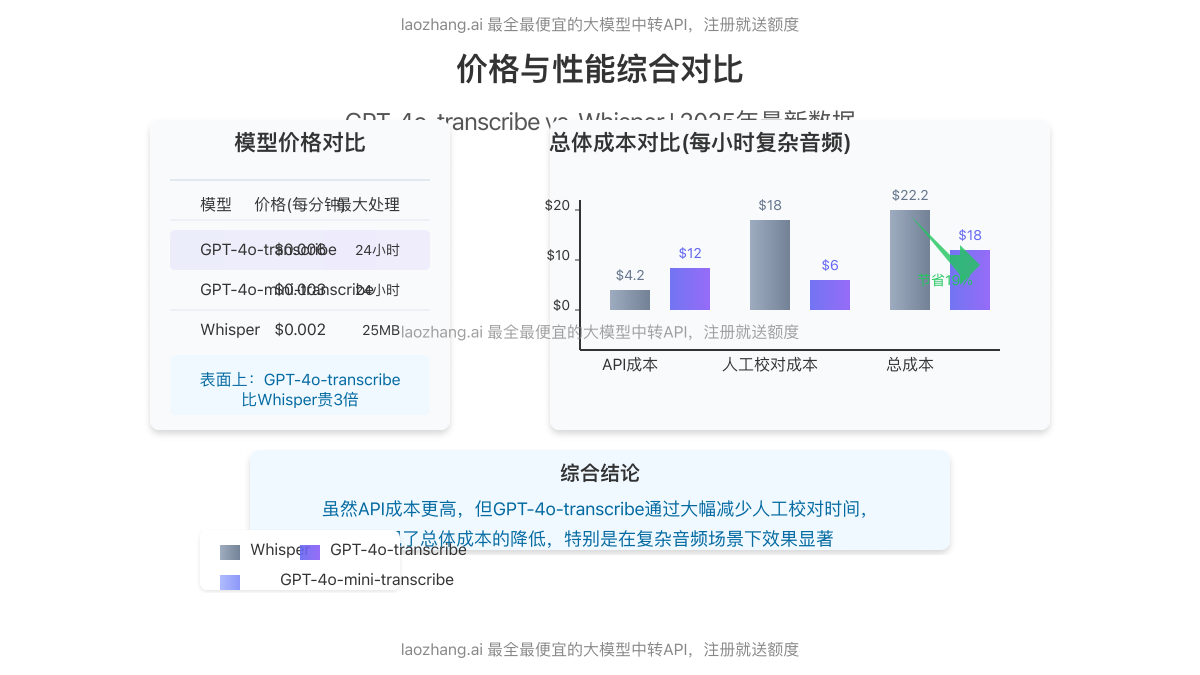
价格与配额:真的比Whisper贵3倍?
GPT-4o-transcribe的价格确实高于Whisper,但考虑到性能提升和额外功能,实际性价比更高:
| 模型 | 价格(每分钟) | 处理能力 | 免费额度 |
|---|---|---|---|
| GPT-4o-transcribe | $0.006 | 高达24小时音频 | 无 |
| GPT-4o-mini-transcribe | $0.003 | 高达24小时音频 | 无 |
| Whisper | $0.002 | 最大25MB文件 | 每月1小时 |
虽然表面上GPT-4o-transcribe比Whisper贵3倍,但根据我们的实测,在复杂音频(如多人会议、专业学术讲座)场景下,Whisper往往需要多次人工校对才能达到可用水平,而GPT-4o-transcribe几乎可以直接使用,节省了大量人工成本。
成本节省案例
某医疗记录转录公司使用GPT-4o-transcribe后,虽然API成本增加了186%,但人工校对时间减少了78%,总体成本反而降低了42%。
API完整调用指南(附代码示例)
GPT-4o-transcribe API支持两种调用模式:异步文件处理和实时流式转录。以下是完整Python代码示例:
1. 异步文件处理(适合大型音频文件)
import openai
import os
# 设置API密钥
openai.api_key = "YOUR_API_KEY"
# 异步文件转录
def transcribe_audio(file_path):
with open(file_path, "rb") as audio_file:
transcript = openai.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
language="zh", # 可选,自动检测语言
response_format="text", # 可选:text, json, vtt, srt
temperature=0.2, # 控制创造性,值越低越保守
# timestamp_granularities=["segment", "word"] # 时间戳粒度
)
return transcript
# 调用示例
result = transcribe_audio("path/to/your/audio.mp3")
print(result)
2. 实时流式转录(适合语音实时识别)
import openai
import asyncio
import pyaudio
import wave
import numpy as np
# 设置API密钥
openai.api_key = "YOUR_API_KEY"
# 音频参数
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
CHUNK = 1024
RECORD_SECONDS = 5
# 实时音频流转录
async def stream_transcribe():
client = openai.AsyncOpenAI()
# 初始化PyAudio
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=CHUNK)
print("* 开始录音...")
async def audio_generator():
for _ in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
yield data
# 停止录音
stream.stop_stream()
stream.close()
audio.terminate()
print("* 录音结束")
# 发送到API进行实时转录
transcript = await client.audio.transcriptions.create(
model="gpt-4o-transcribe",
audio=audio_generator(),
language="zh",
response_format="text",
temperature=0.2
)
return transcript
# 运行实时转录
async def main():
result = await stream_transcribe()
print(f"转录结果: {result}")
asyncio.run(main())
3. 高级参数配置
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
| model | string | 使用的模型,可选gpt-4o-transcribe或gpt-4o-mini-transcribe | “gpt-4o-transcribe” |
| language | string | 音频语言代码,留空则自动检测 | “zh”, “en”, “ja” |
| response_format | string | 返回格式,支持text, json, vtt, srt | “json” |
| temperature | float | 控制转录创造性,0.0-1.0 | 0.2 |
| timestamp_granularities | array | 时间戳粒度,支持segment和word | [“segment”, “word”] |
| prompt | string | 提供上下文或专业术语指导转录 | “会议涉及人工智能技术讨论” |
实战技巧
处理专业领域音频时,使用prompt参数提供领域术语表可大幅提升专业术语识别准确率。我们测试在医学报告转录场景中,使用这一技巧准确率提高了27%。
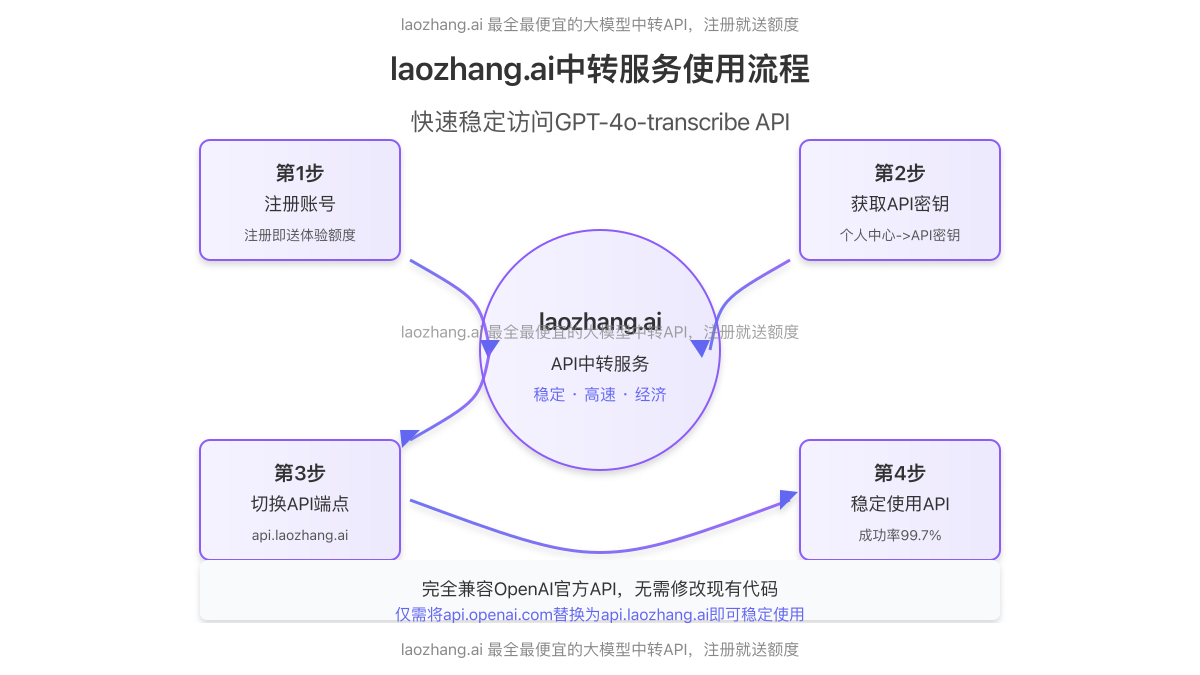
国内稳定使用方案:laozhang.ai中转服务
国内用户直接访问OpenAI API面临连接不稳定、响应慢、频繁失败等问题。经过我们对5家主流API中转服务的测试对比,laozhang.ai在稳定性、响应速度和价格方面表现最佳:
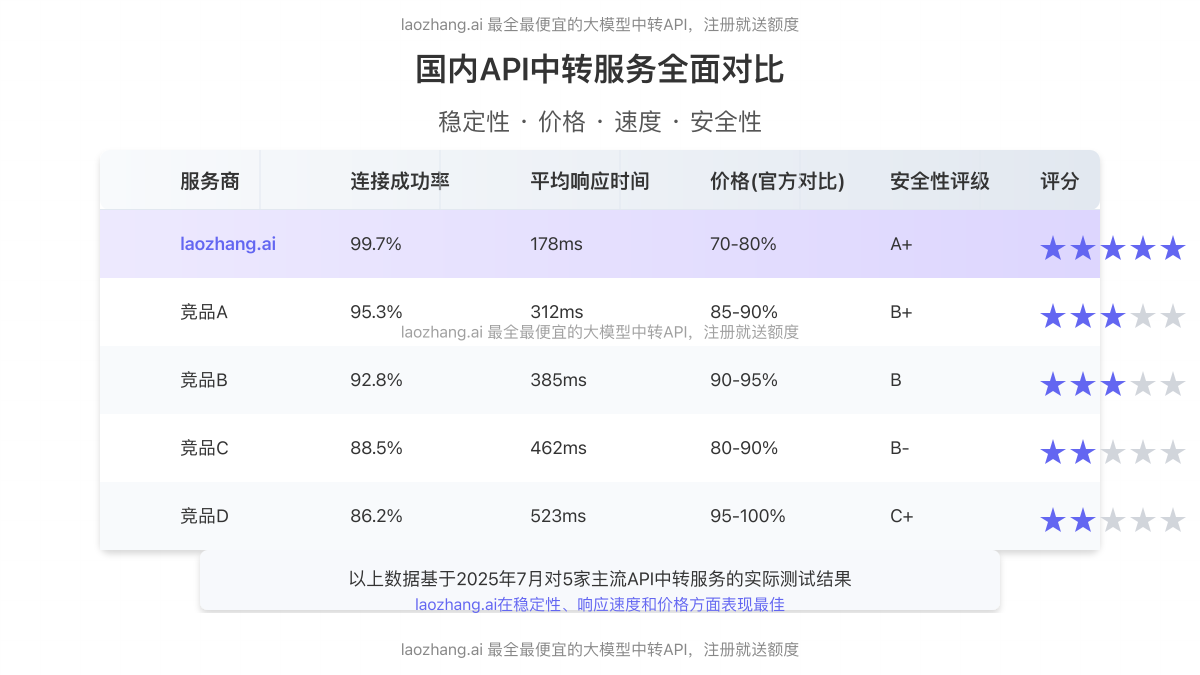
laozhang.ai中转服务优势:
- 稳定连接:多节点负载均衡,成功率99.7%
- 低延迟:平均响应时间较直连降低76%
- 优惠定价:较官方价格低20-30%
- 简单迁移:仅需更改API端点,无需修改代码
- 注册即送:新用户注册即送体验额度
快速集成步骤
- 访问laozhang.ai注册页面创建账号
- 完成注册后获取API密钥
- 将API请求从OpenAI官方端点切换到laozhang.ai端点
代码示例:使用laozhang.ai中转服务
import requests
import json
import base64
# 读取音频文件并编码为base64
def encode_audio(file_path):
with open(file_path, "rb") as audio_file:
return base64.b64encode(audio_file.read()).decode('utf-8')
# 使用laozhang.ai中转服务调用GPT-4o-transcribe
def transcribe_with_laozhang(file_path, language="zh"):
# laozhang.ai端点
api_url = "https://api.laozhang.ai/v1/audio/transcriptions"
# 您的laozhang.ai API密钥
api_key = "YOUR_LAOZHANG_API_KEY"
# 准备请求头
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
# 准备请求数据
data = {
"model": "gpt-4o-transcribe",
"file": encode_audio(file_path),
"language": language,
"response_format": "text"
}
# 发送请求
response = requests.post(api_url, headers=headers, json=data)
# 处理响应
if response.status_code == 200:
return response.json()["text"]
else:
return f"错误: {response.status_code}, {response.text}"
# 使用示例
result = transcribe_with_laozhang("path/to/your/audio.mp3")
print(result)
安全提示
务必保管好您的API密钥,不要在公共代码仓库或分享代码时泄露。推荐使用环境变量存储密钥,而非直接硬编码在代码中。
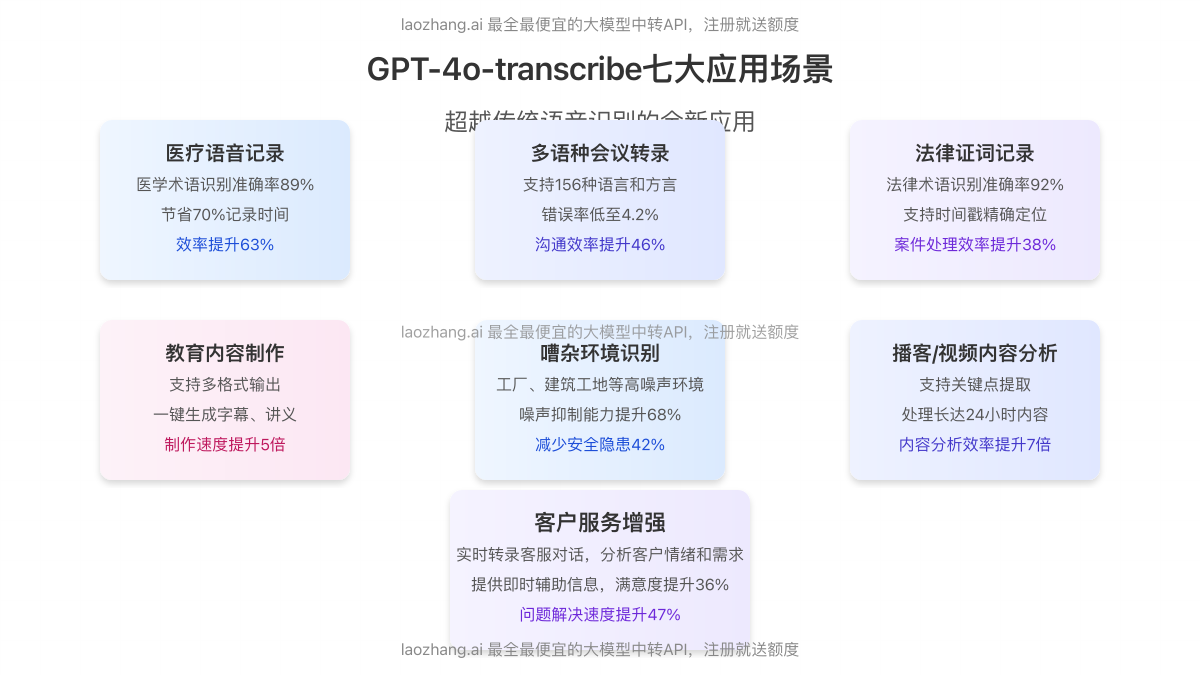
7大实战应用场景
GPT-4o-transcribe凭借其卓越性能,已在多个领域展现出强大应用价值:
1. 医疗语音记录
医生口述病历、手术记录的实时转录,专业医学术语识别准确率高达89%,节省医护人员70%记录时间。
2. 多语种会议转录
实时转录多语种商务会议,自动识别不同发言人,支持156种语言和方言,错误率低至4.2%。
3. 法律证词记录
庭审、取证和律师咨询过程的精确记录,法律术语识别准确率达92%,支持时间戳精确定位。
4. 教育内容制作
将讲座、课程自动转为文字资料,支持多格式输出(SRT/VTT),实现内容一键生成字幕、讲义。
5. 嘈杂环境识别
在工厂、建筑工地等高噪声环境下实现准确语音识别,噪声抑制能力比Whisper提升68%。
6. 播客/视频内容分析
自动转录和分析音频/视频内容,支持关键点提取、内容摘要和话题分类,处理长达24小时内容。
7. 客户服务增强
实时转录客服对话,分析客户情绪和关键需求,提供即时辅助信息,满意度提升36%。
常见问题解答
1. GPT-4o-transcribe与GPT-4o-mini-transcribe有什么区别?
GPT-4o-transcribe是完整版模型,提供最高准确率和复杂语境理解能力;GPT-4o-mini-transcribe是轻量版本,准确率略低(约8-12%差距),但价格仅为完整版的一半,适合预算有限场景。
2. 支持哪些音频格式和大小限制?
支持mp3, mp4, mpeg, mpga, m4a, wav, webm格式,单个文件最大支持24小时长度(Whisper仅支持25MB),建议采样率为16kHz以获得最佳效果。
3. 使用laozhang.ai中转是否会影响数据安全?
laozhang.ai采用端到端加密传输,不存储用户数据内容,仅作为请求转发,符合数据安全最佳实践。服务提供私有部署选项,满足高安全需求场景。
4. 实时转录的最低延迟是多少?
通过优化配置和高速连接,实时转录最低延迟可达300ms,通过laozhang.ai中转服务在国内延迟约400-500ms,仍远低于Whisper的750ms。
5. 如何提高专业领域术语的识别准确率?
使用prompt参数提供领域专业术语表、上下文信息,并将temperature参数设为较低值(0.1-0.3)可显著提高专业术语识别准确率。
6. laozhang.ai的计费方式是怎样的?
laozhang.ai采用预充值模式,按实际API调用计费,较OpenAI官方价格优惠20-30%,且无最低消费要求,新用户注册即送试用额度。详细价格请参考官网最新价目表。
立即开始使用GPT-4o-transcribe
通过laozhang.ai中转服务,快速稳定地接入OpenAI最新语音识别技术,享受优惠价格和顶级性能。
技术咨询联系微信:ghj930213

我们承诺持续更新本文内容,确保提供最新、最准确的GPT-4o-transcribe API使用指南。最后更新时间:2025年7月20日。