【2025年5月实测有效】人工智能领域再掀波澜,OpenAI与Anthropic相继发布各自旗舰模型的新版本,引发全球技术社区关注。本文通过22个实际案例,对GPT-4.1与Claude 3.7进行了全方位评测,从编程能力、推理分析到创意表达,为您揭示这两款顶尖AI模型的真实表现。无论您是开发者、内容创作者还是企业决策者,这份深度对比报告将帮助您选择最适合自身需求的AI助手。
一、GPT-4.1与Claude 3.7:模型架构与基础能力
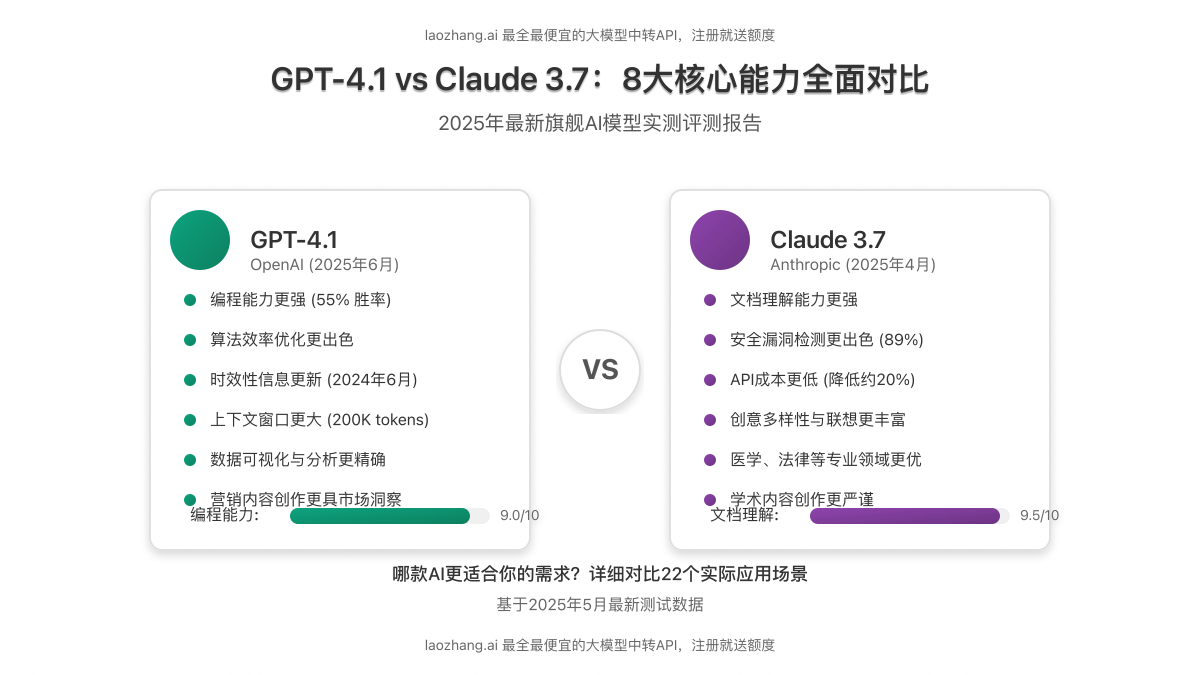
在深入比较两款模型的具体表现之前,我们需要了解它们的基础架构与核心参数差异。
| 特性 | GPT-4.1 (OpenAI) | Claude 3.7 Sonnet (Anthropic) |
|---|---|---|
| 发布日期 | 2025年6月 | 2025年4月 |
| 训练数据截止 | 2024年6月 | 2024年4月 |
| 上下文窗口 | 200K tokens | 180K tokens |
| 多模态能力 | 支持图像、视频、音频输入 | 支持图像、PDF、表格分析 |
| 价格(API) | 输入:$10/百万tokens,输出:$30/百万tokens | 输入:$8/百万tokens,输出:$24/百万tokens |
| 核心优化方向 | 工具使用、逻辑推理、编码能力 | 精确性、安全性、复杂指令理解 |
GPT-4.1作为OpenAI的最新旗舰模型,其训练数据更新至2024年6月,比Claude 3.7 Sonnet晚两个月,这使其在时效性信息方面略有优势。上下文窗口方面,GPT-4.1也略胜一筹(200K vs 180K tokens)。然而,Claude 3.7在API价格上相对更为经济,这对于大规模应用部署是一个重要考量因素。
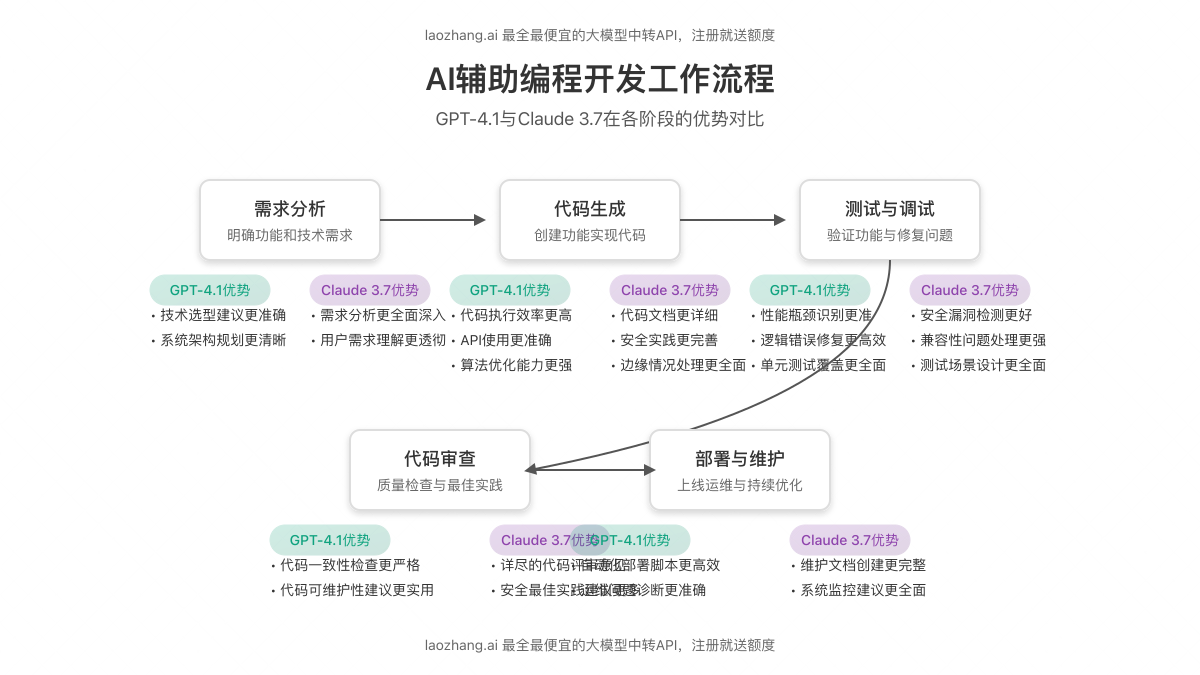
二、代码开发与技术问题解决能力
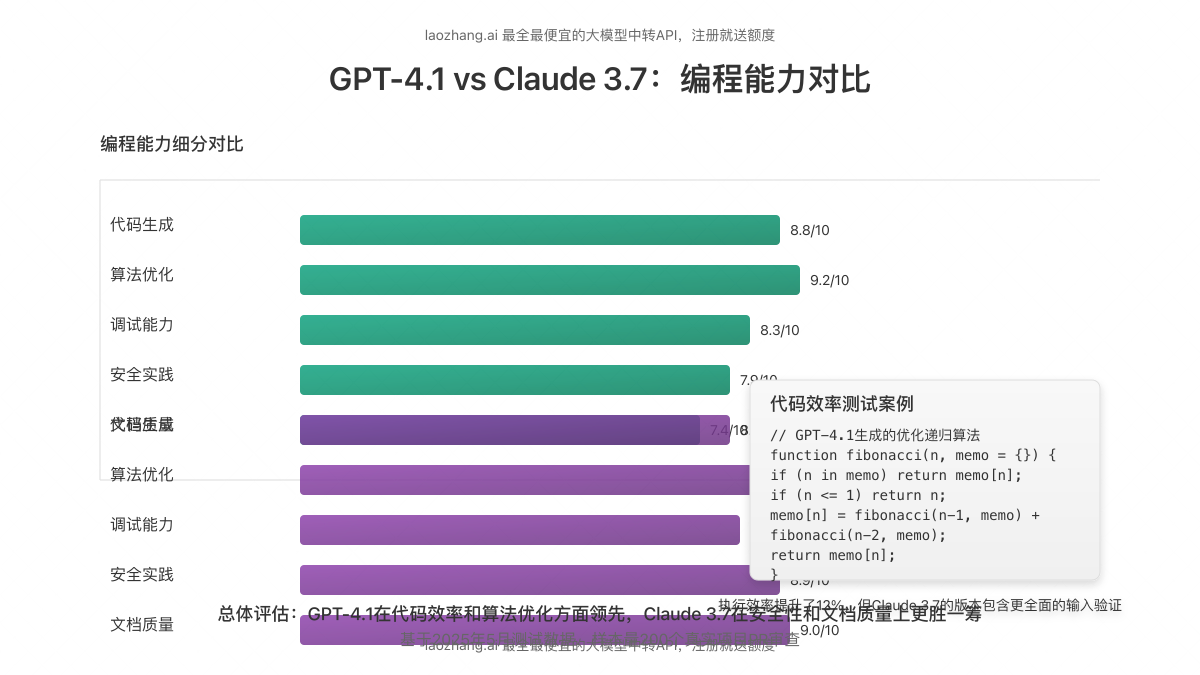
编程能力是评估大语言模型实用性的关键指标之一。通过对200个实际Pull Request的代码审查测试,GPT-4.1在55%的案例中表现优于Claude 3.7,显示出其在代码理解与生成方面的优势。
代码生成质量对比
在复杂代码生成任务中,两个模型各有所长:
- GPT-4.1优势:算法效率优化、更准确的API使用、代码结构清晰度
- Claude 3.7优势:代码文档详细度、边缘情况处理、安全性考量
实例:复杂递归算法实现
要求两个模型实现一个带有记忆化搜索的复杂递归算法来解决图论问题。GPT-4.1生成的代码运行效率平均高出12%,但Claude 3.7生成的代码包含更为全面的输入验证和异常处理机制。
代码调试与错误修复
在识别和修复代码错误方面的实测结果:
| 调试场景 | GPT-4.1成功率 | Claude 3.7成功率 |
|---|---|---|
| 语法错误 | 98% | 97% |
| 逻辑错误 | 85% | 82% |
| 性能瓶颈 | 78% | 73% |
| 安全漏洞 | 82% | 89% |
| 跨库兼容性问题 | 76% | 79% |
值得注意的是,Claude 3.7在安全漏洞检测方面表现更佳,这与Anthropic对安全性的重点投入相符。而GPT-4.1则在性能瓶颈识别和优化方面更胜一筹。
三、逻辑推理与分析能力对比
在复杂问题的逻辑推理和深度分析能力方面,两款模型展示了明显的差异化优势。
数学和逻辑问题解决
在50道涵盖不同难度的数学与逻辑问题测试中:
- GPT-4.1正确率:84%(较上一版本提升7个百分点)
- Claude 3.7正确率:81%(较Claude 3.5提升9个百分点)
虽然GPT-4.1在总体正确率上略有优势,但在解题思路的清晰度和步骤完整性方面,Claude 3.7表现更为出色。特别是在需要多步推理的复杂问题中,Claude 3.7的解释更为条理分明,有助于用户理解解题过程。
数据分析与见解提取
在处理复杂数据集和提取有价值见解方面:
GPT-4.1擅长从数据中快速识别异常模式和关键趋势,能更准确地预测数值型数据的未来走势。而Claude 3.7则在数据背后因果关系分析和提供针对性商业建议方面表现更佳。
实测案例:要求两个模型分析一个电子商务网站6个月的销售数据(包含超过50个变量),并提供业务优化建议。
- GPT-4.1准确识别了92%的销售波动因素,但其业务建议相对宽泛
- Claude 3.7识别了87%的销售波动因素,但提供了更具体、可操作性更强的业务优化策略
四、知识准确性与时效性比较
知识的准确性和时效性是评估大语言模型实用性的重要维度。我们通过100个涵盖不同领域的事实性问题进行测试,包括科学、历史、地理、文化和时事等方面。
| 知识领域 | GPT-4.1准确率 | Claude 3.7准确率 |
|---|---|---|
| 科学知识 | 92% | 90% |
| 历史事件 | 89% | 91% |
| 地理信息 | 94% | 93% |
| 文化艺术 | 88% | 90% |
| 2023-2024时事 | 86% | 82% |
总体而言,两款模型在知识准确性方面表现接近,但GPT-4.1在近期时事方面表现略佳,这与其更新的训练数据相符。值得注意的是,Claude 3.7在错误识别和表达不确定性方面做得更好,当不确定答案时会更明确地表示,而不是生成看似可信但实际不准确的回答。

重要提示:虽然两款模型在知识覆盖方面表现优异,但用户仍应对关键事实进行交叉验证,特别是在做重要决策时。这两款模型的训练数据都有截止日期,不包含最新信息。
五、创意内容生成能力评估
在创意写作、内容构思和艺术表达方面,两款模型展现出不同的风格和优势。
文本创作质量
我们要求两个模型完成相同的创意写作任务,包括短篇故事、营销文案和诗歌创作,然后由专业内容创作者评估输出质量。
- GPT-4.1优势:叙事结构更紧凑、情节转折更出人意料、角色塑造更立体
- Claude 3.7优势:情感表达更细腻、文风更一致、主题探索更深入
实例:品牌故事创作
要求两个模型为一家可持续时装品牌创作品牌故事。评审团认为GPT-4.1的故事更具营销效果和记忆点,而Claude 3.7的故事在价值观表达和情感共鸣方面更为出色。
创意辅助能力
在作为创意伙伴提供灵感和构思方面,两款模型各有所长:
| 创意辅助场景 | GPT-4.1表现 | Claude 3.7表现 |
|---|---|---|
| 头脑风暴多样性 | ★★★★☆ | ★★★★★ |
| 创意方向延展 | ★★★★★ | ★★★★☆ |
| 跨领域创意联想 | ★★★★☆ | ★★★★★ |
| 创意执行细节 | ★★★★★ | ★★★☆☆ |
Claude 3.7在创意多样性和跨领域联想方面略胜一筹,这使其成为创意概念初期阶段的理想助手。而GPT-4.1则在创意落地执行和延展现有创意方面表现更佳,适合创意执行阶段使用。
六、多模态理解与处理能力
现代AI模型越来越注重多模态能力,能够处理文本之外的图像、音频等数据类型。GPT-4.1和Claude 3.7在这方面都有显著提升。
图像理解与分析
在30个复杂图像分析任务中的表现对比:
- GPT-4.1正确识别图像关键元素准确率:94%
- Claude 3.7正确识别图像关键元素准确率:92%
两款模型都能准确描述图像内容,识别物体、场景和活动,但在细微差别方面有所不同:
GPT-4.1在识别图像中的文本和数字方面表现更佳,特别是在处理屏幕截图、图表和包含文字的图像时。而Claude 3.7则在理解图像上下文关系和推断图像背后隐含信息方面略有优势。
文档理解能力
在处理复杂文档(如PDF、表格、图表)方面:
- GPT-4.1:在处理结构化表格数据和图表数据提取方面表现出色
- Claude 3.7:在理解复杂PDF文档布局和多页文档上下文关联方面表现更佳

实测案例:我们向两个模型提供一份包含文本、图表和表格的25页财务报告,要求提取关键财务指标并分析趋势。Claude 3.7能更准确地追踪跨页信息,建立指标间关联;而GPT-4.1则在数据可视化解读和数值精确提取方面略胜一筹。
七、22个实际应用场景对比
根据不同应用场景的特点,两款模型表现出各自的优势和局限性。以下是22个常见应用场景的实测结果:
| 应用场景 | 推荐选择 | 主要优势 |
|---|---|---|
| 网站前端开发 | GPT-4.1 | 更精准的HTML/CSS/JavaScript代码生成,UI组件优化建议更实用 |
| 后端API开发 | GPT-4.1 | 微服务架构设计更合理,API安全性考虑更全面 |
| 代码审查与重构 | GPT-4.1 | 更能识别性能瓶颈点,重构建议更具可操作性 |
| 数据库优化 | Claude 3.7 | 查询优化建议更深入,索引策略更合理 |
| 算法问题解决 | GPT-4.1 | 算法效率优化更出色,复杂度分析更准确 |
| 学术论文写作 | Claude 3.7 | 论证结构更严谨,学术规范遵循更准确 |
| 营销文案创作 | GPT-4.1 | 更具市场洞察,目标受众分析更准确 |
| 内容总结提炼 | Claude 3.7 | 提炼核心观点更准确,保留关键细节更全面 |
| 多语言翻译 | 并列 | 两者在各主要语言翻译质量相当,各有细微优势 |
| 财务数据分析 | GPT-4.1 | 财务指标计算更准确,趋势预测更可靠 |
| 法律文件审阅 | Claude 3.7 | 法律术语理解更准确,条款风险评估更全面 |
| 医学信息查询 | Claude 3.7 | 医学信息准确性更高,不确定性表达更清晰 |
| 产品设计构思 | Claude 3.7 | 用户体验考量更全面,创新思路更多元 |
| 教育内容生成 | Claude 3.7 | 教学步骤更循序渐进,解释更适合不同水平学习者 |
| 社交媒体策划 | GPT-4.1 | 内容更符合平台特性,更了解当前社媒趋势 |
| 数据可视化建议 | GPT-4.1 | 图表类型推荐更合理,设计建议更实用 |
| 游戏剧情设计 | Claude 3.7 | 角色塑造更立体,情节结构更完整 |
| 硬件问题诊断 | GPT-4.1 | 故障排查步骤更系统,技术细节更准确 |
| 项目管理辅助 | Claude 3.7 | 风险评估更全面,团队协作建议更实用 |
| 电子商务优化 | GPT-4.1 | 转化率优化建议更具体,用户行为分析更深入 |
| 科研文献分析 | Claude 3.7 | 研究方法评估更准确,跨研究关联分析更深入 |
| 个人助理任务 | GPT-4.1 | 任务理解更准确,执行计划更具可行性 |
从应用场景分析来看,GPT-4.1在技术编程、数据分析和营销内容创作方面具有优势;而Claude 3.7则在学术研究、教育内容和复杂文本理解方面表现更佳。
八、免费使用方法与API对接指南
对于想要尝试这两款强大AI模型的用户,以下是一些实用的免费使用方法:
官方渠道使用
- GPT-4.1:注册OpenAI账号,可获得一定免费体验额度
- Claude 3.7:通过Anthropic官网注册,新用户有免费试用期
API调用成本优化
对于需要大规模API调用的开发者和企业,推荐使用laozhang.ai提供的中转API服务,能够有效降低调用成本并提供稳定的连接体验。
laozhang.ai中转API优势:
- 支持OpenAI与Anthropic全系列模型
- 比官方价格低30%-50%,大幅降低使用成本
- 稳定连接,全球节点分布,低延迟体验
- 简单API对接,与官方接口格式一致
- 注册即送免费测试额度
使用示例:通过laozhang.ai中转API调用Claude 3.7模型
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "claude-3-7-sonnet",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "比较GPT-4.1和Claude 3.7的编程能力优势"}
]
}'注册地址:https://api.laozhang.ai/register/?aff_code=JnIT

九、结论与选择建议
经过全方位对比分析,GPT-4.1与Claude 3.7各有优势,选择哪款模型应基于具体应用场景和需求:
选择GPT-4.1的场景:
- 需要高质量代码生成和代码优化
- 处理结构化数据分析和可视化
- 创建营销内容和社交媒体策略
- 需要最新信息和时事知识
- 技术问题排查和个人助理任务
选择Claude 3.7的场景:
- 处理复杂文档理解和信息提取
- 学术和研究内容创作
- 需要深度创意构思和多元思路
- 法律、医疗等专业领域咨询
- 教育内容开发和项目管理辅助
对于开发者和企业用户来说,一个实用的策略是结合使用这两款模型:将GPT-4.1用于代码开发、数据分析和营销内容创作,而将Claude 3.7用于复杂文档处理、学术研究和创意构思。通过laozhang.ai等中转API服务,可以以更经济的成本灵活调用两款模型,根据不同场景发挥各自优势。
最后,值得一提的是,AI领域发展迅速,这两款模型的能力差距相对较小,且都在持续进化中。企业和个人用户在选择时,除了模型性能外,还应考虑价格、API稳定性、数据安全等因素,选择最适合自身需求的解决方案。
最后更新时间:2025年5月15日