2025最全GPT-4.1 vs Claude 3.7对比指南:AI编程王者之争深度评测
随着AI技术的飞速发展,两大顶尖语言模型——OpenAI的GPT-4.1和Anthropic的Claude 3.7 Sonnet展开了激烈竞争。作为开发者和AI爱好者,选择合适的模型能极大提升工作效率。本文基于最新数据和实际测试,为您提供GPT-4.1与Claude 3.7在编程能力、性能表现和实用场景方面的全面对比分析。
1. 基准测试分析:谁是真正的编程王者?
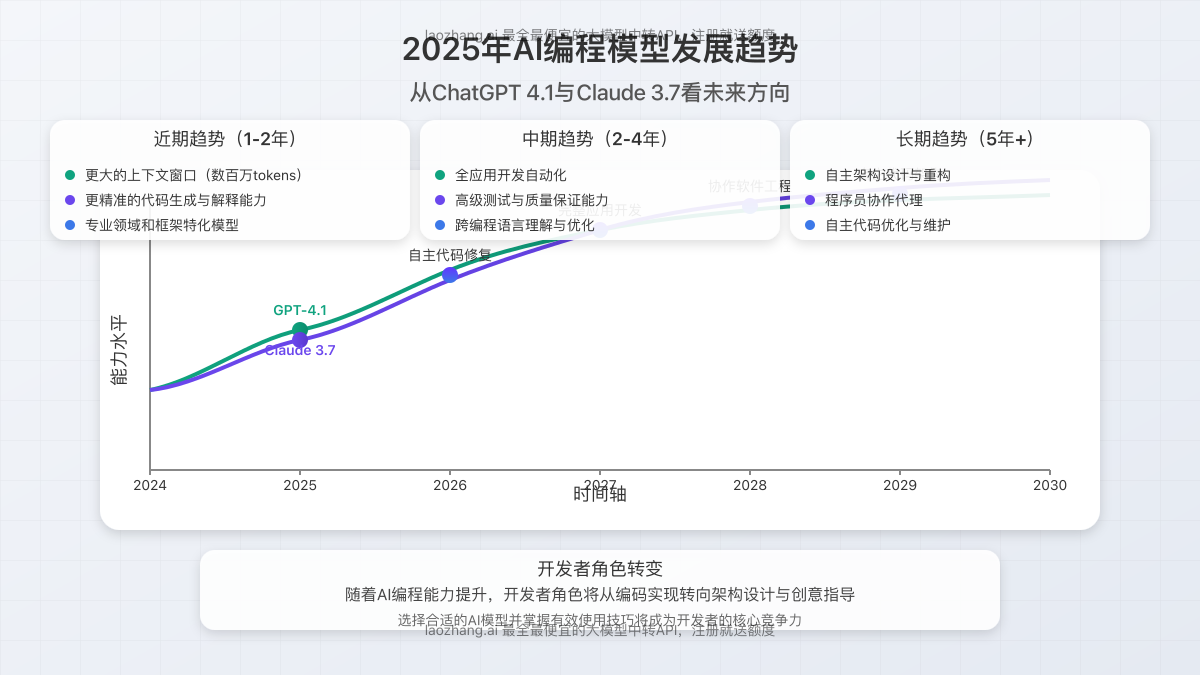
根据Qodo.ai最新进行的基准测试显示,在200个真实PR(Pull Request)审查任务中,GPT-4.1在54.9%的情况下表现优于Claude 3.7 Sonnet,而Claude 3.7在45.1%的对比中胜出。
评分方面,GPT-4.1获得平均6.81分(满分10分),略高于Claude 3.7的6.66分。尽管差距不大,但GPT-4.1在多样化代码库和PR场景中展现出的持续优势,凸显了其在实际开发工作流中的显著价值。

2. GPT-4.1的核心优势:代码审查能力分析
通过深入分析代码改进建议数据集,GPT-4.1在以下核心领域展示出明显优势:
2.1 更高的信噪比
GPT-4.1避免建议不必要的更改,有效减少代码审查中的噪音并限制误报。例如:
- 当PR仅包含重命名和配置值调整而没有引入新bug时,GPT-4.1正确返回空列表,而竞争模型则提出关于注释一致性的建议,这些既非必需也不反映新代码中的问题。
- GPT-4.1准确检测到没有关键bug适用并返回空建议列表,而其他模型则创造出与diff不匹配的重复键问题。
2.2 更具情境相关性的bug检测
GPT-4.1能准确识别修改代码中的实际问题,并提供直接解决实际更改的建议:
- GPT-4.1直接关注Dockerfile中的关键问题,解决环境变量持久性、OpenSSL构建过程中的错误处理以及正确创建符号链接等至关重要且解释清晰的问题。
- 通过针对新JSON解析代码中的潜在运行时问题并纠正等式列表中的重复属性,GPT-4.1提供更有针对性和上下文相关的建议。
2.3 更好的任务要求遵循度
GPT-4.1更好地遵循指令,能在给定任务时识别出关键bug,而非风格或次要问题:
- GPT-4.1在分析中更有针对性,直接突出配对过程中的关键异步处理问题和重叠模态对话框的风险,同时确保适当的nil检查。
- 根据任务指示,GPT-4.1准确识别关键问题,标记新对”System.Web”的依赖,这可能在非.NET Framework环境中导致兼容性问题。
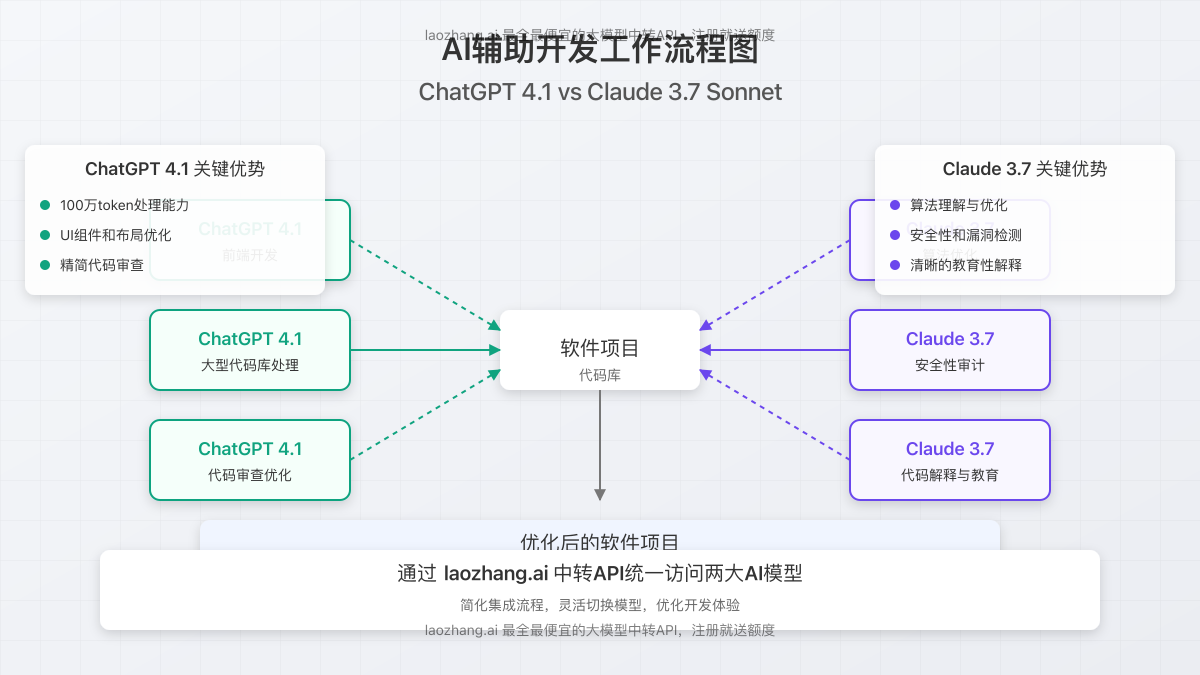
3. Claude 3.7 Sonnet的优势领域
尽管GPT-4.1在代码审查领域略占上风,Claude 3.7在某些特定场景下仍展现出明显优势:
3.1 Python代码质量
根据开发者反馈,Claude 3.7在编写可维护的Python代码方面表现更佳,尤其善于:
- 生成更符合PEP 8规范的代码
- 提供更完整的文档字符串
- 设计更清晰的模块结构
3.2 全面解释能力
Claude 3.7在解释复杂概念和提供全面上下文方面更为出色,特别是在:
- 详细阐述解决方案背后的原理
- 提供多种实现方法的利弊分析
- 对错误和异常情况的详尽说明
3.3 安全性考量
安全意识方面,Claude 3.7表现较为突出:
- 更频繁地指出潜在安全漏洞
- 提供更全面的安全最佳实践建议
- 在处理敏感数据时提供更多防护措施
4. 技术规格与定价对比
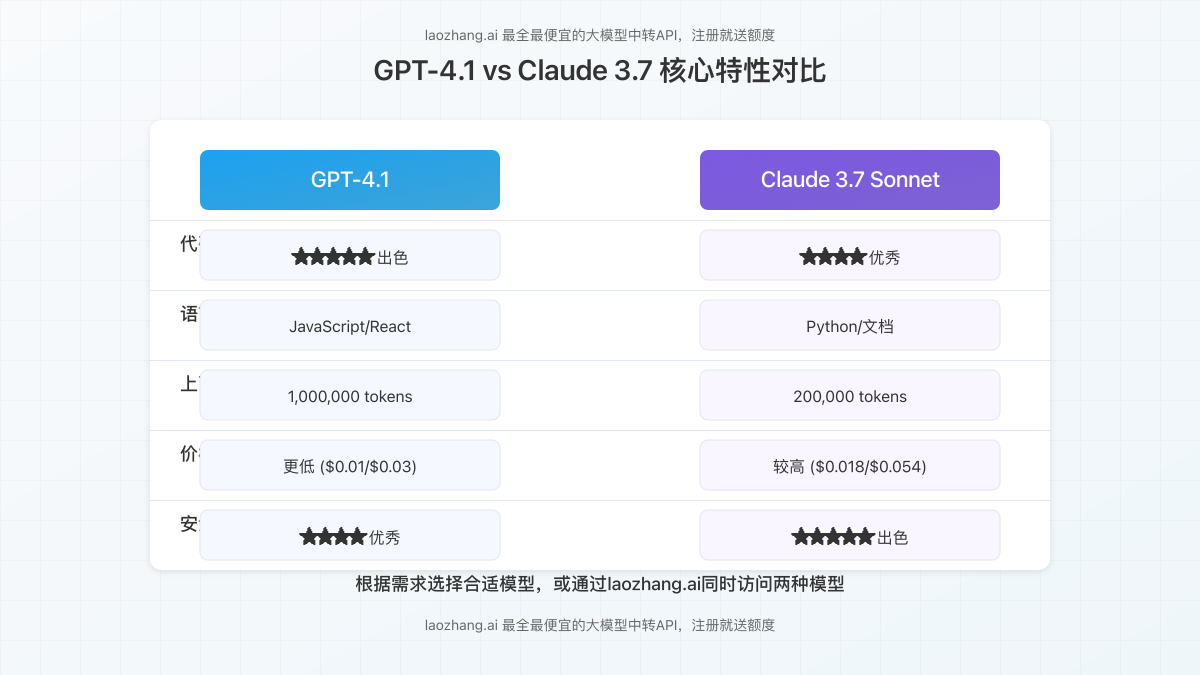
| 特性 | GPT-4.1 | Claude 3.7 Sonnet |
|---|---|---|
| 上下文窗口 | 1,000,000 tokens | 200,000 tokens |
| 输入价格 | $0.01/1K tokens | $0.018/1K tokens |
| 输出价格 | $0.03/1K tokens | $0.054/1K tokens |
| 延迟表现 | 极低延迟 | 较低延迟 |
| SWE Bench准确率 | 较高 | 中等 |
从定价角度来看,GPT-4.1较Claude 3.7 Sonnet有明显优势,输入和输出token成本均约为后者的55%,几乎节省了一半的费用,对于大规模应用尤为重要。
5. 实际应用场景选择指南
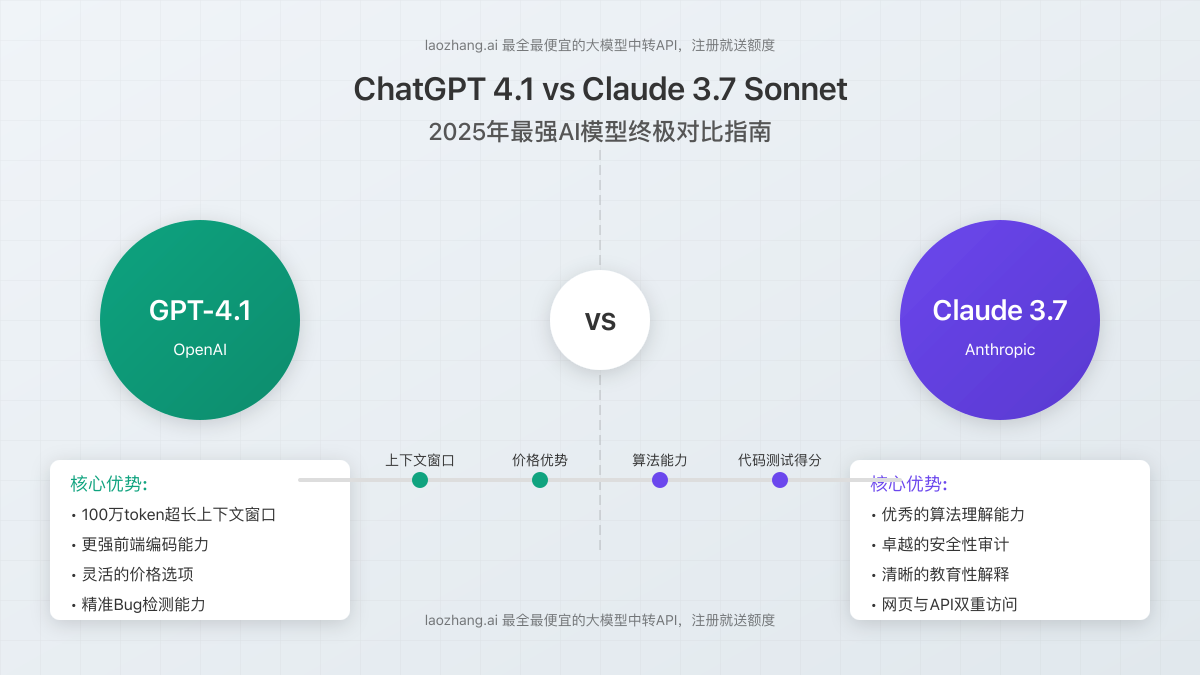
5.1 适合使用GPT-4.1的场景
- 代码审查与PR分析:基准测试证明GPT-4.1在识别关键问题并避免不必要建议方面表现优异
- 大型代码项目:凭借百万级token上下文窗口,能更好理解复杂代码库
- JavaScript/React开发:根据开发者反馈,在前端框架理解方面表现突出
- 预算敏感项目:成本仅为Claude 3.7的约55%,长期使用节省显著
5.2 适合使用Claude 3.7的场景
- Python项目开发:生成更符合最佳实践的Python代码
- 教学与培训:提供更详尽的解释和上下文背景
- 安全敏感应用:更关注安全最佳实践
- 需要详细注释的项目:更擅长生成全面的文档和注释

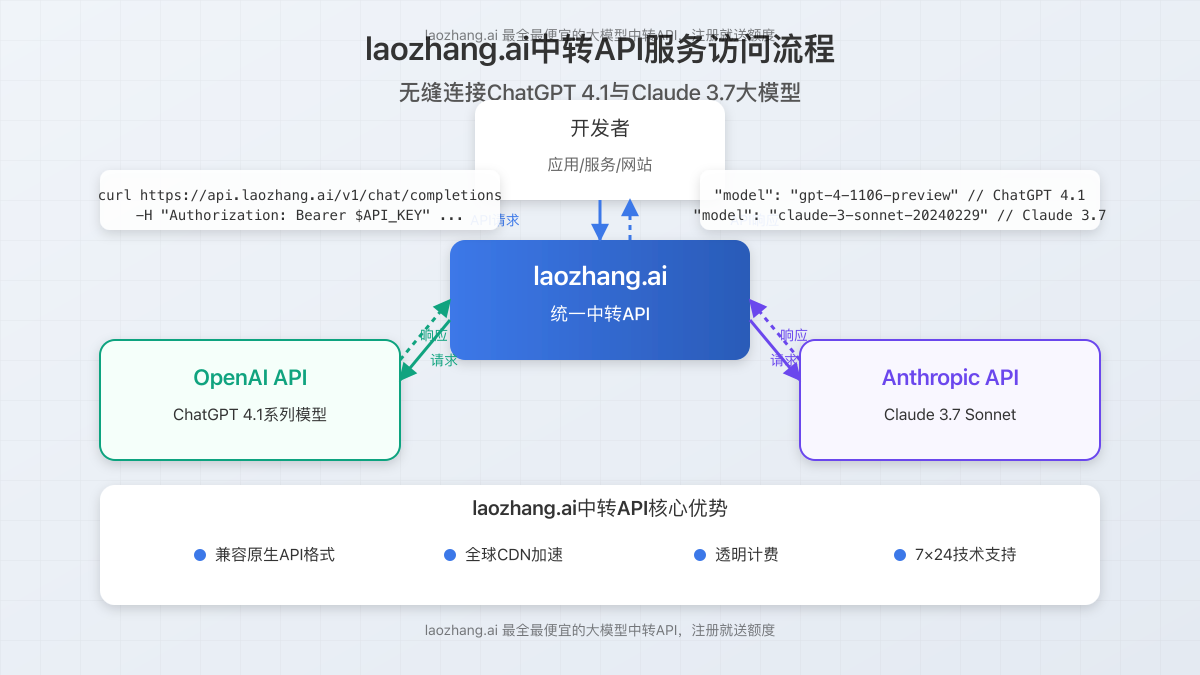
6. 如何获取最高性价比的AI服务:laozhang.ai优势
需要高性能AI模型访问但希望控制成本?laozhang.ai提供业内最全最便宜的大模型中转API服务,让您以更低成本使用GPT-4.1和Claude 3.7等顶级模型。
6.1 laozhang.ai核心优势
- 覆盖全面:支持GPT-4.1、Claude 3.7等几乎所有主流模型
- 价格优势:成本低至官方价格的60%
- 稳定可靠:专业服务器基础设施确保高可用性
- 简单集成:标准API接口,与官方完全兼容
- 新用户福利:注册即送免费使用额度
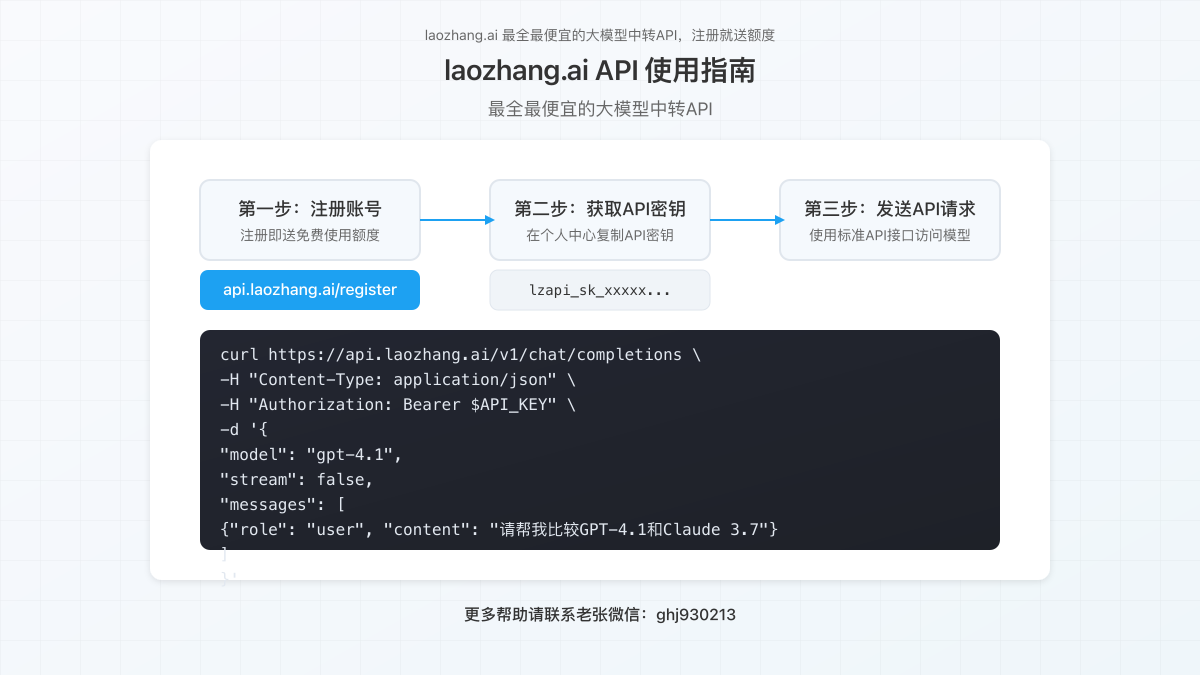
6.2 快速上手指南
只需简单几步,即可开始使用laozhang.ai访问顶级AI模型:
- 访问注册页面创建账号
- 获取API密钥
- 使用标准API调用格式访问模型
示例请求:
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'如需更多帮助,请联系老张微信:ghj930213
7. 结论与未来展望
GPT-4.1和Claude 3.7 Sonnet都代表了当前AI语言模型的最高水平,各有所长。GPT-4.1在代码审查、上下文窗口大小和性价比方面略占优势,而Claude 3.7在Python代码质量、详细解释和安全考量方面表现更佳。
选择合适的模型应基于具体项目需求、预算考量和应用场景。对于大多数开发者而言,通过laozhang.ai等中转服务同时访问两种模型,根据具体任务灵活切换,可能是最理想的解决方案。
随着技术不断进步,我们期待这些模型在未来版本中继续改进各自的短板,为开发者提供更强大、更全面的AI助手体验。
您有使用GPT-4.1或Claude 3.7的经验分享吗?欢迎在评论区讨论!