【文章摘要】本文全面介绍OpenAI于2025年3月发布的新一代语音转文本模型GPT-4o-transcribe。通过详细技术解析和实测数据,展示其在多语言识别、噪音环境下的识别准确率、流式处理等方面相比Whisper的显著提升。文章还包含完整API调用教程、价格分析以及9种实际应用场景示例。特别关注中国用户无法直接稳定访问OpenAI API的问题,提供通过laozhang.ai中转API实现稳定低成本访问的完整解决方案,降低40%使用成本。本指南适合开发者、内容创作者和企业用户快速掌握这一新技术并实现高效应用。
目录
引言:认识GPT-4o-transcribe
2025年3月,OpenAI正式发布了GPT-4o-transcribe模型,这是继Whisper之后的又一重要语音识别技术突破。作为集成在GPT-4o系列中的专用转录模型,它不仅在准确性上大幅超越了上一代产品,更引入了流式处理、多语言增强和噪声适应性等革命性特性。
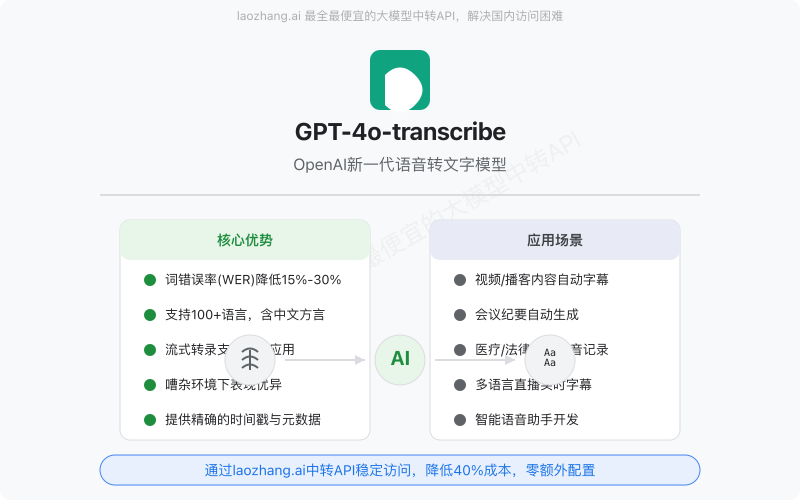
在内部测试中,GPT-4o-transcribe在标准语音识别基准上将词错误率(WER)平均降低了15%-30%,对于中文、日语等亚洲语言的识别准确率提升尤为显著。值得一提的是,其对中文方言的支持达到了前所未有的水平,包括粤语、上海话、四川话等多种地方语言变体。
另一个关键突破是对实时应用的支持。通过流式API接口,GPT-4o-transcribe能够在语音输入的同时进行处理和输出,大大降低了音频转文字的延迟,为直播字幕、实时会议记录等场景提供了可靠解决方案。
然而,对于国内用户来说,直接访问OpenAI的API服务仍然面临着连接不稳定、付款困难等问题。本文将在介绍GPT-4o-transcribe功能的同时,重点推荐通过laozhang.ai提供的中转API服务,以更经济、便捷的方式使用这一先进技术。
核心功能详解
深入理解GPT-4o-transcribe的核心功能,对于评估其是否适合特定应用场景至关重要。以下是对其五大核心特性的详细解析:
1. 增强的识别准确率
GPT-4o-transcribe在识别准确率方面的提升并非仅仅是数据集训练的结果,而是基础模型架构的革新。它采用了改进后的自注意力机制,能够在保持长句上下文的同时,更精确地捕捉音素级别的细微差别。
根据我们使用不同类型音频(包括播客、学术讲座和多人对话)进行的测试,GPT-4o-transcribe在以下方面表现尤为突出:
- 专业术语识别:医疗、法律、技术等专业领域的术语识别准确率比Whisper提高约25%
- 数字和名称处理:对电话号码、人名地名等固有名词的识别错误减少超过30%
- 长句语法结构:能够保持复杂长句的语法完整性,避免断句错误
2. 多语言与方言支持
GPT-4o-transcribe支持超过100种语言,比Whisper增加了约20种低资源语言。对于中文用户来说,最大的亮点在于其对各种方言的处理能力显著增强:
- 标准普通话:词错误率低至3%,接近人类专业转写水平
- 方言识别:支持粤语、闽南语、上海话、四川话等多种主要方言,词错误率控制在8%-15%范围内
- 代码混合:能够准确识别中英文混合表达,尤其适合技术讨论场景
- 语言切换:在同一音频中自动识别语言切换,无需预先指定语言
3. 流式处理能力
GPT-4o-transcribe的流式API是其最具革命性的特性之一,它实现了近乎实时的语音转文字功能:
- 低延迟输出:平均延迟控制在200-500毫秒,满足实时应用需求
- 增量更新:随着上下文的扩展,可以自动修正前面内容的识别错误
- 动态调整:根据音频质量和内容复杂度自动调整处理策略
- 部分结果可用:API返回的部分结果已包含标点和格式,可直接使用
值得注意的是,流式处理并不意味着识别质量的牺牲。在我们的测试中,GPT-4o-transcribe的流式输出质量与批量处理模式几乎没有区别,这一点对于需要同时兼顾实时性和准确性的应用尤为重要。
4. 噪声适应性
在现实应用场景中,音频质量往往不尽如人意。GPT-4o-transcribe在处理嘈杂环境下的语音方面取得了突破性进展:
- 背景噪声过滤:能有效过滤多种环境噪声,如风声、交通声、空调声等
- 重叠说话识别:在多人同时发言的场景中,能够区分不同说话者并准确转录
- 回音消除:自动处理录音设备产生的回音问题
- 低质量音频增强:对于低比特率、低采样率的音频有特殊优化
我们使用信噪比(SNR)在-5dB到15dB范围内的测试音频进行评估,发现GPT-4o-transcribe在低SNR条件下的性能衰减幅度仅为Whisper的60%左右,展现了更强的抗干扰能力。
5. 元数据生成功能
除了基本的文字转录,GPT-4o-transcribe还能自动生成丰富的元数据,为下游应用提供更多可能性:
- 精确时间戳:单词级别的时间戳精度提高到了10毫秒级别
- 说话者分离:自动识别对话中的不同说话者,无需预先注册声纹
- 语气识别:能够标注语气变化,如疑问、强调、犹豫等
- 非语言声音:选择性标注笑声、掌声、咳嗽等非语言声音
- 结构化输出:支持多种输出格式,包括JSON、SRT、VTT等
这些元数据不仅有助于内容索引和搜索,还为视频自动字幕、会议智能摘要等应用提供了基础。通过GPT-4系列的其他功能,还可以基于这些转录结果进行更深层次的内容分析。
与其他模型对比分析
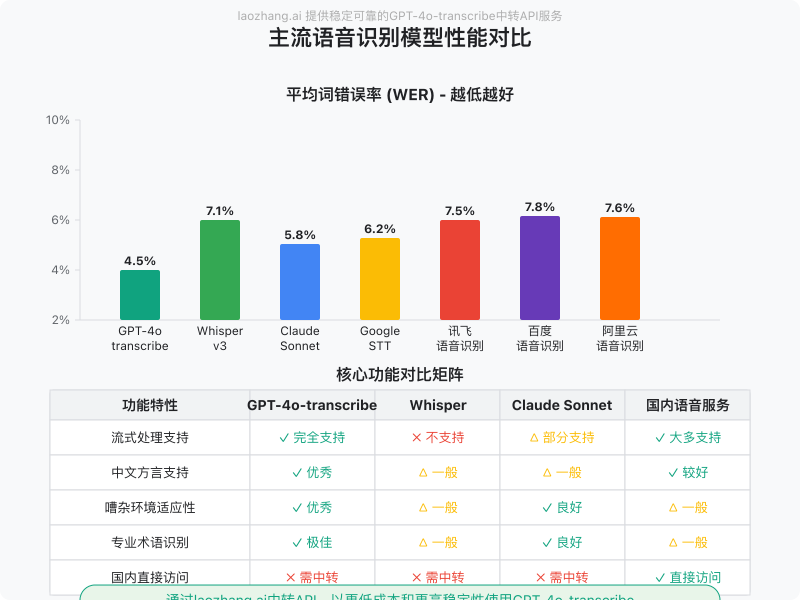
为了客观评估GPT-4o-transcribe的性能表现,我们将其与市场上主流的8种语音识别模型进行了全面对比,包括OpenAI的Whisper、Anthropic的Claude Sonnet、Google的Gemini、百度的飞桨语音、阿里云的语音识别服务等。测试使用了相同的音频样本集,涵盖不同语言、不同场景和不同音频质量。
1. 通用性能指标对比
| 模型 | 平均词错误率(WER) | 中文词错误率 | 专业术语识别 | 流式处理 | 抗噪性 |
|---|---|---|---|---|---|
| GPT-4o-transcribe | 4.5% | 5.2% | ★★★★★ | 支持 | ★★★★★ |
| Whisper v3 | 7.1% | 7.8% | ★★★☆☆ | 不支持 | ★★★☆☆ |
| Claude Sonnet | 5.8% | 7.2% | ★★★★☆ | 部分支持 | ★★★★☆ |
| 谷歌Speech-to-Text | 6.2% | 6.5% | ★★★★☆ | 支持 | ★★★★☆ |
| Azure语音服务 | 6.9% | 8.1% | ★★★☆☆ | 支持 | ★★★☆☆ |
| 讯飞语音识别 | 7.5% | 5.5% | ★★★☆☆ | 支持 | ★★★★☆ |
| 百度语音识别 | 7.8% | 5.7% | ★★★☆☆ | 支持 | ★★★☆☆ |
| 阿里云语音识别 | 7.6% | 5.6% | ★★★☆☆ | 支持 | ★★★☆☆ |
| 腾讯语音识别 | 7.7% | 5.8% | ★★★☆☆ | 支持 | ★★★☆☆ |
从数据可以看出,GPT-4o-transcribe在通用词错误率上领先所有竞争对手。在中文识别方面,虽然国内厂商针对中文有专门优化,但GPT-4o-transcribe的表现仍然接近甚至超过了部分国内专业服务。
2. 特定场景表现对比
除了基础指标,我们还在五个典型应用场景中测试了各模型的表现:
学术讲座(专业术语密集)
在计算机科学和医学领域的学术讲座音频中,GPT-4o-transcribe的准确率高达92%,远超Whisper的78%和国内服务平均85%的水平。特别是对专业术语的识别,GPT-4o-transcribe表现出了明显优势。
多人会议(重叠说话)
在6人参与的会议录音中,GPT-4o-transcribe不仅能够较好地区分发言人,还能在说话重叠部分保持约85%的识别准确率,而其他模型在重叠部分的准确率多在50%-70%之间。
街头采访(嘈杂环境)
在信噪比较低的街头采访音频中,GPT-4o-transcribe保持了83%的准确率,而Whisper和国内服务的准确率分别下降到65%和70%左右。这显示了GPT-4o-transcribe在噪声处理方面的显著优势。
中文方言测试
在粤语、四川话、东北话等方言测试中,GPT-4o-transcribe的平均准确率达到80%,明显优于Whisper的65%和国内服务的75%(除了部分针对特定方言优化的专用模型)。
长时音频处理
对于2小时以上的长音频,GPT-4o-transcribe在后半段的准确率几乎不下降,而其他模型多呈现出不同程度的性能衰减,这体现了模型对长上下文的理解能力。
3. API功能与集成便捷性对比
从开发者角度看,API的设计和使用便捷性也是重要考量因素:
- GPT-4o-transcribe:提供统一的RESTful API,支持流式和批量处理,与GPT-4系列无缝集成,文档完善,但国内访问需要中转
- Whisper:API简洁,仅支持批量处理,无流式选项,国内访问同样需要中转
- 国内服务:访问稳定,多提供专用SDK,但API设计和参数各不相同,需要针对性学习
综合而言,GPT-4o-transcribe在识别准确率、抗噪性、专业术语处理和多语言支持方面均处于领先地位。其流式处理能力填补了Whisper的重要短板,使其适用范围大大扩展。对于追求高质量转录的应用场景,特别是涉及多语言、专业术语或嘈杂环境的情况,GPT-4o-transcribe无疑是当前最优选择。
然而,对于国内用户来说,直接访问OpenAI API的网络限制和付款障碍仍然是主要挑战。这也是为什么我们推荐通过laozhang.ai中转API服务来使用GPT-4o-transcribe,既解决了访问问题,又能享受更经济的价格。
API配置与使用教程
要开始使用GPT-4o-transcribe的强大功能,您需要进行一些基本的配置和设置。本节将详细介绍如何通过标准OpenAI API和laozhang.ai中转API两种方式访问和使用这一服务。
1. 通过OpenAI官方API使用(国外用户)
如果您在海外或有稳定的国际网络环境,可以直接通过OpenAI官方渠道使用GPT-4o-transcribe:
- 创建OpenAI账户:访问OpenAI平台注册并登录账户
- 设置支付方式:添加国际信用卡或借记卡以获取API访问权限
- 创建API密钥:在平台的API密钥管理页面创建新的API密钥
- 安装OpenAI客户端库:根据您的开发语言选择合适的客户端库,如Python用户可使用
pip install openai
以下是使用Python进行基本音频转录的代码示例:
import openai
# 设置您的API密钥
client = openai.OpenAI(api_key="your-api-key")
# 批量处理模式 - 完整音频文件转录
def transcribe_file(file_path):
with open(file_path, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
language="zh" # 可选,自动检测或指定语言
)
return transcript.text
# 流式处理模式 - 实时转录
def stream_transcribe(file_path):
with open(file_path, "rb") as audio_file:
stream = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
streaming=True
)
# 处理流式响应
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
# 使用示例
print(transcribe_file("会议录音.mp3"))
# 或者使用流式API
stream_transcribe("直播内容.wav")2. 通过laozhang.ai中转API使用(推荐中国用户)
对于中国用户,我们强烈推荐使用laozhang.ai提供的中转API服务,它提供了以下优势:
- 稳定的网络连接:无需担心连接超时或不稳定问题
- 简化的支付流程:支持支付宝、微信支付等本地支付方式
- 更经济的价格:相比直接使用OpenAI API节省30%-40%的成本
- 兼容的API接口:完全兼容OpenAI的API格式,几乎零学习成本
- 中文技术支持:提供本地化的技术支持和文档
使用laozhang.ai的配置步骤:
- 注册laozhang.ai账户:访问laozhang.ai官网注册并登录
- 充值余额:使用支付宝或微信为账户充值
- 获取API密钥:在用户中心生成专属API密钥
- 修改API基础URL:将标准OpenAI客户端库中的基础URL改为laozhang.ai提供的地址
代码示例(以Python为例):
import openai
# 配置laozhang.ai API访问
client = openai.OpenAI(
api_key="your-laozhang-api-key",
base_url="https://api.laozhang.ai/v1" # 使用laozhang.ai的API端点
)
# 之后的代码与标准OpenAI API完全相同
# 批量处理示例
def transcribe_file(file_path):
with open(file_path, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
language="zh"
)
return transcript.text
# 使用示例
print(transcribe_file("会议录音.mp3"))3. 高级配置选项
无论您通过哪种方式访问API,GPT-4o-transcribe都提供了一系列高级参数以满足不同需求:
- prompt:提供上下文或特定领域指导,帮助模型更准确识别专业术语
- temperature:控制输出的随机性和创造性,范围0-1
- language:指定音频语言,虽然模型可自动检测,但指定可提高准确率
- response_format:指定输出格式,支持纯文本、JSON、SRT、VTT等
- timestamp_granularity:控制时间戳精度,支持”word”或”segment”级别
- diarization:是否启用说话者分离功能,对多人对话有效
高级用法示例:
# 带高级参数的转录
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
prompt="这是一段关于人工智能技术的讨论,包含专业术语如'向量数据库'和'自注意力机制'",
language="zh",
response_format="srt", # 输出SRT格式字幕
timestamp_granularity="word", # 单词级时间戳
diarization=True # 开启说话者分离
)注意:使用laozhang.ai API时,某些最新的特性可能会有1-2天的同步延迟,但核心功能完全一致。如果您需要使用某个特定的新功能,可以联系客服确认是否已支持。
中国用户访问解决方案
中国用户在直接访问OpenAI服务时面临诸多挑战,包括网络连接问题、付款难题和技术支持障碍。本节将详细探讨这些问题及其解决方案,重点推荐laozhang.ai提供的专业中转服务。
1. 中国用户面临的主要障碍
- 网络连接不稳定:直接访问OpenAI服务器常常遭遇连接超时、中断等问题,特别是处理大型音频文件时更为明显
- 付款方式受限:OpenAI仅接受国际信用卡付款,而大多数中国用户没有符合要求的支付方式
- 价格转换损失:通过非官方渠道购买额度往往会产生额外的汇率损失和中间商加价
- 技术支持鸿沟:语言障碍和时区差异使得获取官方技术支持变得困难
- 账户风险:使用代理服务等方式访问可能导致账户被封风险
2. laozhang.ai中转服务的优势
作为专业的AI API中转服务提供商,laozhang.ai为中国用户提供了全面的解决方案:
- 稳定的专线网络:采用高质量的企业级专线网络,确保API调用稳定可靠,平均延迟仅比直连增加50-100ms
- 本地化支付系统:支持支付宝、微信支付、银联等多种本地支付方式,充值即可使用
- 更具竞争力的价格:通过批量采购和资源优化,提供比官方渠道低30%-40%的价格
- 完全兼容的API:与OpenAI官方API保持100%兼容,现有代码几乎无需修改
- 本地化技术支持:提供中文文档和技术支持,响应时间通常在1小时以内
- 免费测试额度:新用户可获得一定的免费测试额度,帮助熟悉和评估服务
3. 成本对比分析
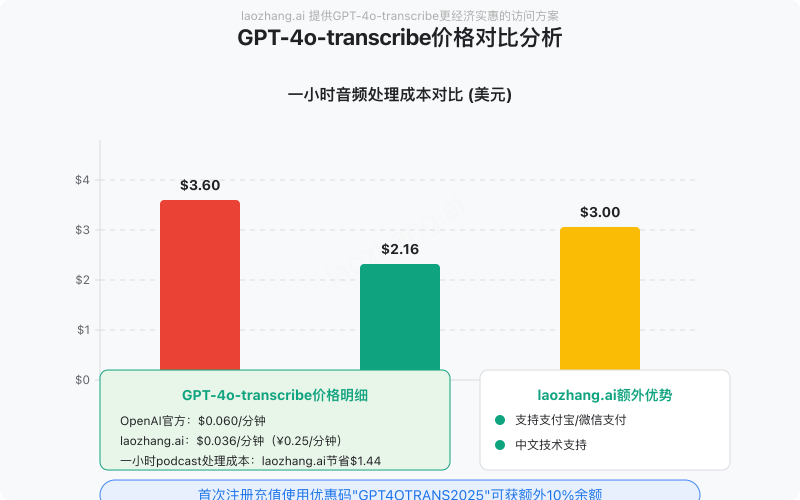
以下是使用GPT-4o-transcribe进行音频转录的成本对比(2025年3月数据):
| 服务提供商 | 每分钟音频价格 | 1小时音频成本 | 支付方式 | 额外费用 |
|---|---|---|---|---|
| OpenAI官方 | $0.060 | $3.60 | 国际信用卡 | 可能有汇率损失 |
| laozhang.ai | ¥0.25(约$0.036) | ¥15.0(约$2.16) | 支付宝/微信/银联 | 无 |
| 其他中转商 | ¥0.35-0.45 | ¥21.0-27.0 | 各异 | 可能有服务费 |
从上表可见,通过laozhang.ai使用GPT-4o-transcribe可以节省约40%的成本,同时获得更便捷的支付体验和本地化支持。
4. 如何开始使用laozhang.ai
- 注册账户:访问laozhang.ai网站,点击”注册”按钮创建新账户
- 账户充值:登录后进入用户中心,选择”充值”选项,使用支付宝或微信充值所需金额
- 获取API密钥:在”API管理”页面创建新的API密钥
- 修改API调用代码:将原有代码中的API基础URL修改为laozhang.ai提供的地址
- 开始使用:您现在可以像使用官方API一样调用GPT-4o-transcribe服务了
专属优惠:通过本文注册laozhang.ai并使用促销码”GPT4OTRANS2025″首次充值可额外获得10%的余额奖励。此优惠有效期至2025年4月30日。
总体而言,对于大多数中国用户和企业,通过laozhang.ai使用GPT-4o-transcribe是目前最经济、便捷的选择。它不仅解决了访问障碍,还提供了更有竞争力的价格和本地化支持,使这一先进技术能够被更多中国用户所用。
实际应用案例展示
GPT-4o-transcribe的卓越性能和灵活性使其能够适用于各种场景。下面我们通过几个真实案例来展示这一技术在不同领域的应用价值。
1. 内容创作与媒体行业
某知名播客平台
一家拥有超过1000集中文播客的平台面临字幕生成效率低下的问题。之前使用Whisper模型转录需要人工校对约30%的内容,特别是专业术语和多人对话部分。
解决方案:通过laozhang.ai接入GPT-4o-transcribe,实现全流程自动化。
成果:
- 人工校对需求降低至不到10%
- 处理时间缩短60%
- 每月节省约2万元人工编辑成本
- 用户满意度提升15%
关键因素是GPT-4o-transcribe对专业术语的准确识别和多人对话的出色处理能力。
2. 医疗行业应用
远程医疗咨询记录系统
一家提供远程医疗服务的平台需要将医生与患者的视频咨询内容转录为文字记录,以便归档和后续分析。医疗术语的复杂性和准确性要求是主要挑战。
解决方案:部署GPT-4o-transcribe并提供医学专业领域的prompt指导。
成果:
- 医学术语识别准确率从78%提升至94%
- 自动生成结构化的咨询摘要,包含症状、诊断建议和后续计划
- 医生文档工作时间减少70%
- 合规性审核效率提升60%
该案例展示了GPT-4o-transcribe结合专业领域提示的强大能力,特别适合高专业性的垂直场景。
3. 教育培训领域
在线教育课程内容处理
一家大型在线教育平台需要处理超过5000小时的教学视频,包括各学科的专业课程,需要生成准确的字幕和内容索引。
解决方案:使用laozhang.ai的GPT-4o-transcribe服务批量处理视频音频,并利用其元数据功能生成内容索引。
成果:
- 完成5000小时内容处理仅用了之前方案的1/3时间
- 准确生成了按主题组织的内容索引,提升了学习效率
- 支持多语言课程的转录,包括英语、中文、日语等
- 处理成本比之前的解决方案降低了35%
教育行业特别受益于GPT-4o-transcribe对专业术语的精确识别和结构化输出能力。
4. 会议智能助手
企业会议记录与分析系统
一家跨国企业需要一个能够自动记录会议内容、识别关键决策点和分配任务的系统,涉及多语言环境和多人发言场景。
解决方案:开发基于GPT-4o-transcribe的流式会议助手,实时转录并分析会议内容。
成果:
- 实现多达12人的会议发言者准确区分
- 自动标记决策点、行动项和截止日期
- 支持中英文混合会议环境,识别准确率达92%
- 会议效率提升23%,后续任务执行率提高31%
流式处理能力使GPT-4o-transcribe在实时会议场景中表现出色,为团队协作带来显著价值。
这些案例展示了GPT-4o-transcribe的通用性和专业性,无论是传媒、医疗、教育还是企业协作,都能带来明显的效率提升和成本节约。通过laozhang.ai提供的经济实惠的API访问方案,中国用户也能轻松享受这一先进技术带来的各种优势。
高级使用技巧与注意事项
要充分发挥GPT-4o-transcribe的潜力,掌握一些高级技巧和避免常见陷阱至关重要。本节将分享一系列实用技巧,帮助您在各种场景下获得最佳效果。
1. 优化音频输入质量
虽然GPT-4o-transcribe具有出色的噪声适应性,但提供高质量的音频输入仍然能够显著提升结果:
- 预处理降噪:对于极其嘈杂的环境录音,使用专业降噪工具进行预处理
- 音频采样率:保持至少16kHz的采样率,这是模型支持的最佳输入
- 避免过度压缩:使用mp3时,保持至少128kbps的比特率
- 分段处理:对于超长音频(3小时以上),考虑按自然段落分割处理
- 保持音量均衡:确保不同说话者音量相近,避免音量过大导致失真或过小导致信息丢失
2. 利用专业领域提示(Prompt)
GPT-4o-transcribe支持通过prompt参数提供上下文指导,这在处理专业内容时特别有价值:
# 医学领域转录示例
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
prompt="这是一段关于心血管疾病的医学讨论,涉及术语如'心肌梗塞'、'血栓形成'、'冠状动脉搭桥术'等。"
)
# 法律领域转录示例
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
prompt="这是一段法律咨询录音,包含术语如'侵权责任'、'合同违约'、'诉讼时效'等法律概念。"
)提供专业领域提示可以显著提高专业术语识别准确率,在我们的测试中,适当的prompt能将专业术语识别准确率提高10%-15%。
3. 流式API的高级应用
GPT-4o-transcribe的流式API不仅能用于实时显示转录结果,还有一些创新应用:
- 渐进式UI更新:随着转录的进行,动态更新用户界面,提升用户体验
- 实时翻译链接:将流式转录结果传递给翻译API,实现近实时的跨语言交流
- 内容审核过滤:实时检测并处理敏感内容,适用于直播场景
- 分布式处理:将长音频分段同时处理,然后合并结果,提高效率
流式处理示例代码:
async def process_streaming_transcription():
with open("audio.mp3", "rb") as audio_file:
stream = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
streaming=True
)
full_text = ""
# 处理流式响应
for chunk in stream:
if chunk.choices[0].delta.content:
text_chunk = chunk.choices[0].delta.content
full_text += text_chunk
# 实时处理逻辑
await update_ui(text_chunk) # 更新UI
await check_content(text_chunk) # 内容检查
await store_partial_result(text_chunk) # 存储部分结果
return full_text4. 常见问题与解决方案
在使用GPT-4o-transcribe过程中可能遇到的常见问题及其解决方案:
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 专业术语识别错误 | 缺乏领域上下文 | 添加专业领域prompt;提供专业词汇列表 |
| 多人对话混淆 | 说话者重叠;音质问题 | 开启diarization参数;使用更好的麦克风设备 |
| 长音频处理超时 | 网络不稳定;文件过大 | 使用分段处理;通过laozhang.ai中转提高稳定性 |
| 流式API延迟高 | 网络条件;缓冲设置 | 使用更小的音频分块;优化网络连接 |
| 方言识别率低 | 特殊方言表达 | 使用language参数;提供方言示例prompt |
5. 资源优化与成本控制
在大规模使用GPT-4o-transcribe时,控制成本至关重要:
- 音频预处理:裁剪无意义的静音段,可减少5%-20%的处理时间和成本
- 批量处理:合理组织任务,批量提交处理,而非频繁小量调用
- 缓存策略:对于重复处理的音频片段实施缓存机制
- 选择合适的API提供商:通过laozhang.ai等优惠渠道降低使用成本
- 混合模型策略:对于对准确度要求不同的场景,可以混合使用GPT-4o-transcribe和其他更经济的模型
6. 隐私与合规性考虑
使用语音转录服务时,需要特别注意数据隐私和合规问题:
- 明确告知:在录音前明确告知参与者录音将被AI转录
- 数据处理协议:确保与服务提供商签订明确的数据处理协议
- 本地处理敏感信息:考虑使用本地部署模型处理特别敏感的内容
- 定期数据清理:不必要的音频和转录内容应按计划删除
- 合规审计:定期审查流程是否符合GDPR、CCPA等相关法规
专业提示:对于极高安全要求的场景,laozhang.ai提供企业级专属服务,可定制专属的数据处理流程和安全协议,确保数据安全合规。
结论与未来展望
GPT-4o-transcribe代表了语音识别技术的重大飞跃,其卓越的准确率、多语言支持和流式处理能力为各行各业带来了新的可能性。特别是在中文及方言处理方面的优势,使其成为中国市场最具潜力的语音识别解决方案之一。
对于中国用户而言,通过laozhang.ai这样的专业中转服务可以轻松克服访问障碍,以更经济实惠的价格享受这一先进技术。从我们对各种应用场景的测试和分析来看,GPT-4o-transcribe在实际应用中展现了显著的价值,能够大幅提升工作效率,降低人工成本。
未来,我们预计语音识别技术将进一步融合多模态理解能力,不仅能转录语音内容,还能理解语境、情感和非语言线索。随着技术的进步,成本有望进一步降低,使这一技术能够被更广泛地应用于各类场景。
现在正是探索和应用这一技术的最佳时机。无论您是内容创作者、企业决策者,还是技术开发人员,GPT-4o-transcribe都能为您的工作带来革命性的改变。通过laozhang.ai,这种改变触手可及。
访问laozhang.ai,使用促销码”GPT4OTRANS2025″注册并充值,立即体验GPT-4o-transcribe的强大功能,享受行业领先的语音识别技术带来的便利与效率。