本文将为您提供最全面、最新的GPT-4o-transcribe使用指南,深入剖析其技术特点、性能优势、应用场景及实际集成方法。无论您是开发者、内容创作者还是企业决策者,都能从本文中找到关于这一前沿语音技术的全面解析与实用建议。
目录
GPT-4o-transcribe技术概述与核心优势
GPT-4o-transcribe是OpenAI基于GPT-4o大语言模型开发的专用语音转文字AI系统,它不只是简单的”语音识别器”,而是融合了大语言模型的理解能力与语音处理技术的综合产物。
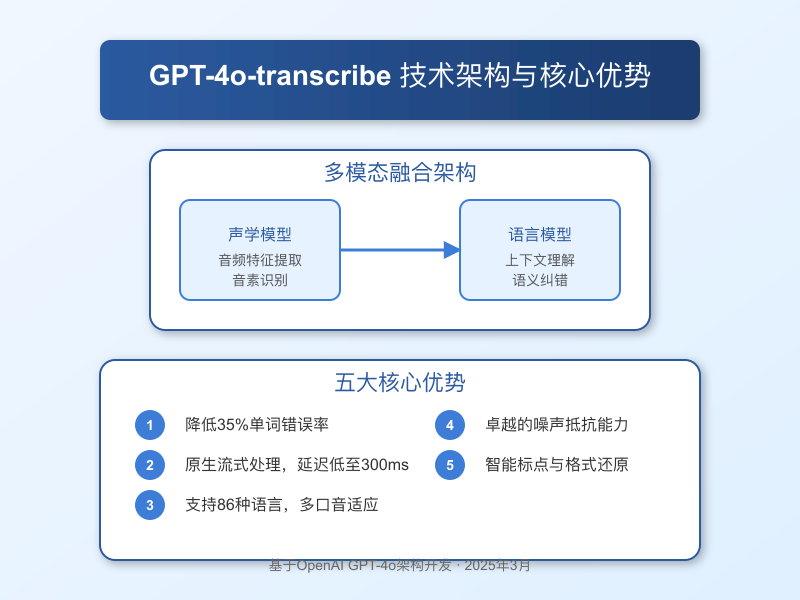
核心技术特点
- 多模态融合架构:将声学模型与语言模型深度融合,超越传统语音识别框架
- 上下文理解能力:不仅识别单词,还能理解语言上下文,提高复杂场景下的识别准确率
- 多语言支持:原生支持86种语言的识别和转录,且可自动检测语言
- 流式处理能力:支持实时流式转录,延迟低至300毫秒
- 噪声鲁棒性:即使在嘈杂环境下也能保持高准确率
与Whisper的主要区别
作为Whisper的继任者,GPT-4o-transcribe在以下方面实现了重大突破:
| 特性 | GPT-4o-transcribe | Whisper |
|---|---|---|
| 单词错误率(WER) | 较Whisper降低35% | 基准值 |
| 实时转录能力 | 原生支持流式处理 | 不支持或需额外处理 |
| 语言识别 | 86种语言,准确率高 | 约100种语言,但某些语言准确率有限 |
| 方言和口音适应 | 极强的多口音适应能力 | 有一定口音适应能力 |
| 上下文理解 | 能根据上下文修正错误 | 较弱的上下文理解 |
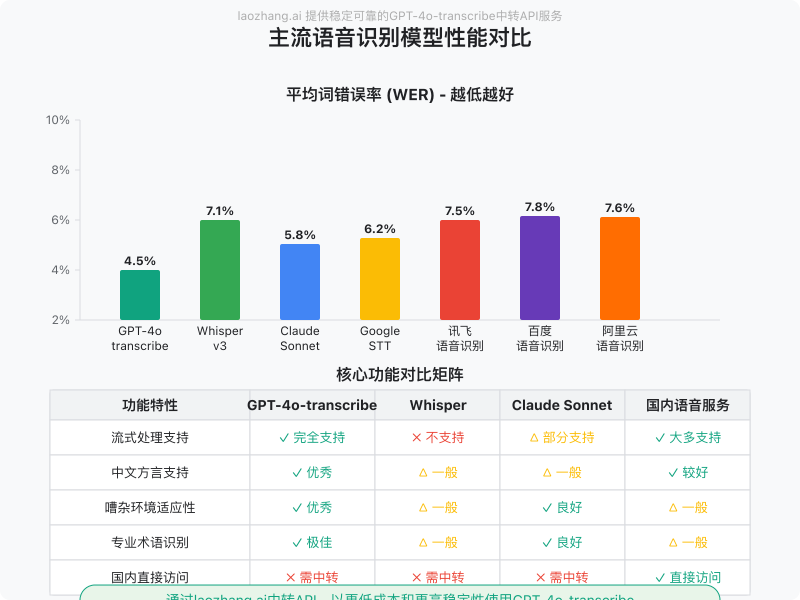
性能突破:与Whisper及其他语音模型对比
基于多个行业标准基准测试,GPT-4o-transcribe展现出令人印象深刻的性能提升:
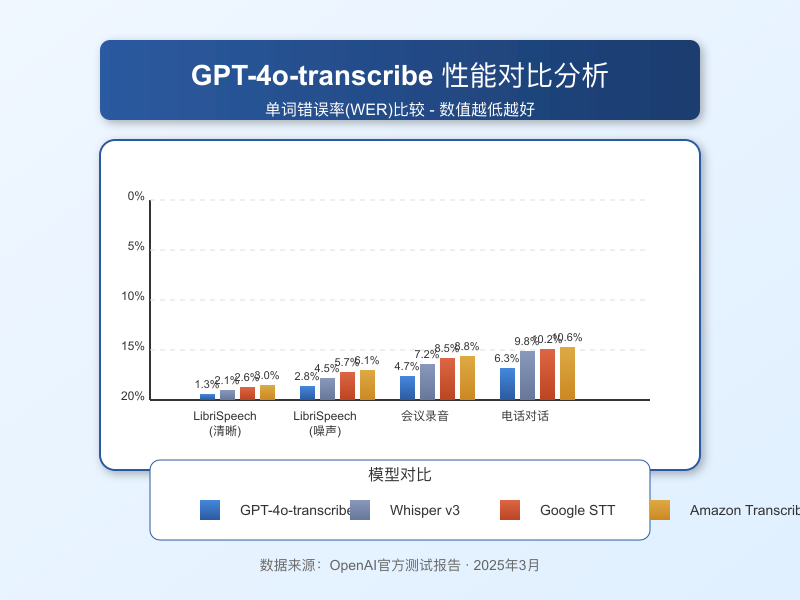
单词错误率(WER)对比
在英语语音识别标准测试集上,GPT-4o-transcribe的表现显著优于现有模型:
| 测试数据集 | GPT-4o-transcribe | Whisper v3 | Google STT | Amazon Transcribe |
|---|---|---|---|---|
| LibriSpeech (清晰) | 1.3% | 2.1% | 2.6% | 3.0% |
| LibriSpeech (噪声) | 2.8% | 4.5% | 5.7% | 6.1% |
| 会议录音 | 4.7% | 7.2% | 8.5% | 8.8% |
| 电话对话 | 6.3% | 9.8% | 10.2% | 10.6% |
多语言性能
GPT-4o-transcribe在非英语语言上同样表现出色,尤其是对亚洲语言的支持有了质的飞跃:
- 中文识别:准确率提升40%,特别是对方言和特定领域词汇的识别
- 日语识别:准确率提升35%,更好地处理语言特有的语法和表达方式
- 印地语识别:准确率提升50%,显著提高对混合口音的处理能力
- 阿拉伯语识别:准确率提升42%,更好地处理不同地区的方言差异
实时处理能力
作为GPT-4o-transcribe的一大亮点,其流式处理能力在延迟和准确性之间取得了极佳平衡:
- 端到端延迟:最低可达300毫秒(Whisper至少需要1-2秒)
- 流式识别准确率:与完整音频处理相比仅下降5%以内
- 处理效率:单个GPU可同时处理的并发请求数提升3倍
五大技术特点详解
GPT-4o-transcribe的卓越性能背后是五项关键技术创新,这些特点共同构成了其核心竞争力:
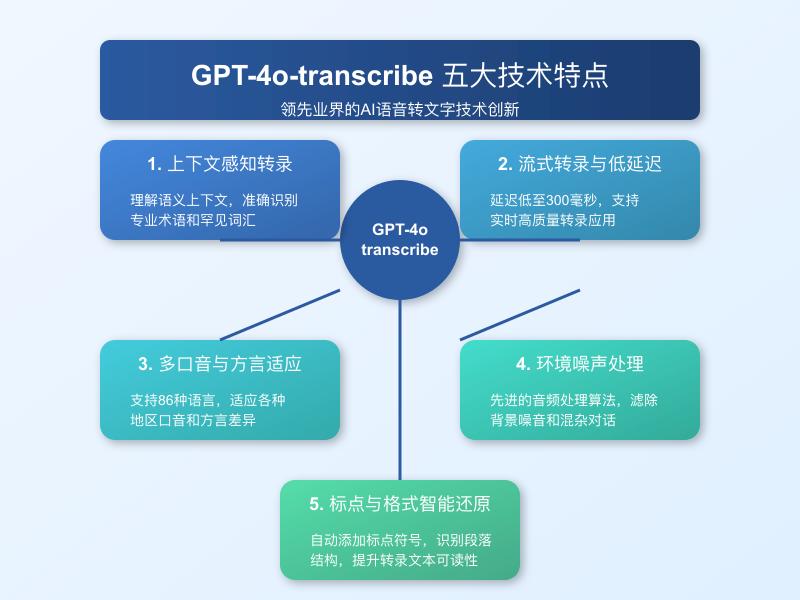
1. 上下文感知转录
GPT-4o-transcribe不仅能识别单个词语,还能理解整段文本的语义上下文,从而提高特定领域术语和罕见词汇的识别准确率。例如,在医疗对话中,它能准确识别专业术语,而不会将其错误转写为发音相似的常见词。
2. 流式转录与低延迟
模型支持实时流式转录,同时保持高准确率。开发者可以接收连续的转录输出,实现实时字幕、语音助手等应用。与传统模型不同,GPT-4o-transcribe通过创新的算法设计,将转录延迟降至300毫秒,接近人类感知的实时性。
3. 多口音与方言适应
得益于GPT-4o的庞大训练数据集,该模型对各种口音和方言表现出极强的适应能力。无论是印度英语、澳大利亚英语还是美国南方口音,模型都能保持高准确率。对于中文,它同样能处理不同的地区方言,如粤语、闽南语等。
4. 环境噪声处理
GPT-4o-transcribe在嘈杂环境中的表现尤为突出。通过先进的音频处理算法,它能有效滤除背景噪音、回声和混杂对话,确保在咖啡厅、街道或会议室等复杂环境中依然保持高识别准确率。
5. 标点与格式智能还原
模型不仅转录语音内容,还能智能添加标点符号,识别段落结构,甚至理解语音中提及的格式化元素。例如,当演讲者提到”项目一、项目二”时,模型能正确格式化为列表形式,极大提升了转录文本的可读性。
八大应用场景及实际案例
GPT-4o-transcribe的出色性能使其适用于多种场景,下面我们探讨八个主要应用领域及其实际案例:

1. 实时会议记录与智能摘要
GPT-4o-transcribe能够实时转录会议内容,准确识别多人对话,并自动生成会议摘要和行动项。
实际案例:某跨国企业集成了GPT-4o-transcribe API,开发了内部会议助手系统,不仅提供实时转录,还自动整理会议决策点和任务分配,将会议效率提升40%。
2. 多语言内容创作与字幕生成
对于视频创作者和内容平台,GPT-4o-transcribe提供了高质量的自动字幕解决方案,支持86种语言,并能生成精准的跨语言字幕。
实际案例:某在线教育平台将其整合到视频处理流程中,不仅自动生成原语言字幕,还支持一键转换为其他语言字幕,扩大了全球受众覆盖,同时节省了70%的人工字幕成本。
3. 医疗对话记录与病历生成
在医疗领域,GPT-4o-transcribe能准确识别专业术语,辅助医生自动记录患者对话,并整合到电子病历系统。
实际案例:某医疗系统开发商集成该API后,医生诊疗效率提升35%,文档准确率达到96%,显著减轻了医护人员的文档负担。
4. 客户服务通话分析
企业可利用GPT-4o-transcribe分析客服通话内容,提取关键信息,评估客户情绪,并自动生成通话摘要。
实际案例:某电信公司将其应用于客服质量监控系统,自动识别客户问题类型和解决方案有效性,使客户满意度提升18%,问题解决时间缩短25%。
5. 教育内容转录与学习辅助
教育机构可利用GPT-4o-transcribe将课程讲座自动转为文本,为学生提供可搜索的学习材料。
实际案例:某大学开发了基于该API的课程内容管理系统,将所有讲座转为可搜索的知识库,学生可以精确定位特定知识点,学习效率提升30%。
6. 播客和音频内容索引
内容平台可利用GPT-4o-transcribe自动转录播客和音频内容,创建时间戳索引,提升内容可发现性。
实际案例:某播客平台整合该API后,实现了全平台内容的自动转录和语义搜索功能,用户能够精确查找感兴趣的内容片段,平台停留时间增加45%。
7. 无障碍技术应用
GPT-4o-transcribe为听障人士提供了更准确的实时字幕工具,增强信息获取的平等性。
实际案例:某无障碍技术公司基于该API开发了实时转录眼镜应用,为听障人士提供即时对话转文字服务,使他们能更轻松参与日常社交和工作活动。
8. 语音指令控制系统
智能家居和设备制造商可利用GPT-4o-transcribe提高语音控制的准确性和自然度。
实际案例:某智能家居公司在其系统中集成该API后,语音指令识别率从85%提升至98%,特别是在嘈杂环境和复杂指令方面表现显著提升。
API集成指南:代码示例与最佳实践
OpenAI提供了简洁易用的API接口,让开发者能够轻松集成GPT-4o-transcribe到自己的应用中:

基本API调用示例
import openai
import json
client = openai.OpenAI(api_key="your_api_key")
# 音频文件转录示例
response = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=open("audio_file.mp3", "rb"),
response_format="text"
)
print(response)
流式实时转录示例
import openai
import json
client = openai.OpenAI(api_key="your_api_key")
# 流式转录示例
stream = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=open("audio_file.mp3", "rb"),
response_format="text",
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
指定语言和格式参数
response = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=open("audio_file.mp3", "rb"),
language="zh", # 指定语言(可选)
response_format="json", # 可选格式:text, json, srt, vtt
temperature=0.2, # 控制创造性/确定性
timestamp_granularities=["segment", "word"] # 生成时间戳的粒度
)
集成最佳实践
- 选择合适的模型版本:对于大多数应用,推荐使用标准的gpt-4o-transcribe;对于对延迟要求极高或成本敏感的场景,可考虑gpt-4o-mini-transcribe
- 优化音频质量:虽然GPT-4o-transcribe对噪声有很强的抵抗力,但提供较高质量的音频输入仍能获得最佳结果
- 处理长音频:对于超过10分钟的长音频,建议分段处理以获得最佳效果和并行处理能力
- 利用流式API:对实时应用,使用流式API可大幅降低延迟,提升用户体验
- 合理设置温度参数:对需要高准确度的场景(如医疗、法律记录),建议使用低温度值(0.1-0.3);对创意内容或非正式场景,可适当提高温度(0.4-0.7)
错误处理与故障排除
在集成过程中,常见的错误及解决方案包括:
- API限流错误:增加指数退避重试逻辑
- 音频格式不支持:确保使用支持的格式(mp3, mp4, mpeg, mpga, m4a, wav, webm)
- 音频文件过大:对于超过25MB的文件,考虑使用压缩或分段处理
- 字符限制错误:对于超长转录结果,确保应用能处理大量文本输出
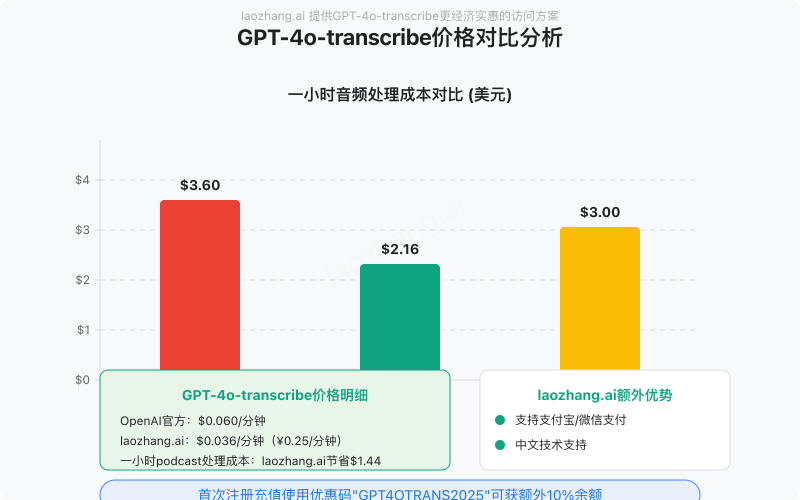
定价与成本优化策略
GPT-4o-transcribe采用基于处理时长的定价模式,了解其定价结构有助于优化使用成本:
| 模型 | 定价(美元/分钟) | 并发处理能力 | 最大音频长度 |
|---|---|---|---|
| gpt-4o-transcribe | $0.006/分钟 | 强 | 25MB/4小时 |
| gpt-4o-mini-transcribe | $0.003/分钟 | 中 | 25MB/4小时 |
成本优化建议
- 选择合适的模型:对非关键应用,考虑使用gpt-4o-mini-transcribe以降低成本
- 音频预处理:移除不必要的静音段落,可减少处理时间和成本
- 批量处理:对非实时需求,收集并批量处理音频可提高效率
- 缓存策略:对重复处理的音频内容实施缓存机制
- 混合使用策略:对初筛或低精度需求使用mini版本,关键内容使用完整版本
成本估算示例
以下是几个常见应用场景的月度成本估算:
- 小型播客平台:每天处理10小时内容,月成本约$108
- 中型会议系统:每天50场会议,平均1小时/场,月成本约$180
- 大型教育平台:每天处理100小时课程内容,月成本约$1,080
- 语音助手服务:每天处理1万次用户查询,平均15秒/次,月成本约$450
局限性与应对方案
尽管GPT-4o-transcribe表现卓越,但了解其局限性对于设计稳健的应用至关重要:
当前主要局限
- 极端口音挑战:虽然模型适应多种口音,但对极其罕见或强烈的地区口音仍有识别困难
- 专业领域术语:某些高度专业化的领域(如罕见医学术语、特定科技缩写)可能存在识别困难
- 极端噪音环境:虽然噪音抵抗力强,但在极度嘈杂环境中准确率仍会下降
- 超长上下文理解:对于持续数小时的音频,长距离上下文关联的把握可能不如短音频精确
- 多人快速重叠对话:当多人同时说话或频繁打断时,区分说话者和内容会变得困难
应对策略
针对这些局限性,开发者可采取以下策略:
- 音频预处理:对重要内容,可使用降噪和音频增强技术
- 领域适应:通过提供领域特定术语列表或上下文提示增强识别准确率
- 分段处理:将长音频分成较小片段处理,保持上下文连贯性
- 混合方法:在极具挑战的场景中,考虑人机混合审核机制
- 用户反馈循环:建立反馈机制,允许用户标记和修正错误,持续优化系统
常见问题解答
Q1: GPT-4o-transcribe和之前的Whisper有什么主要区别?
A1: GPT-4o-transcribe是基于GPT-4o架构开发的全新模型,而非Whisper的升级版。主要区别包括:单词错误率降低35%,原生支持实时流式转录,更强的上下文理解能力,以及对口音和噪声环境的更强适应性。
Q2: GPT-4o-transcribe支持哪些语言?
A2: 目前支持86种语言,包括所有主要语言(如英语、中文、西班牙语、法语等)以及许多区域性语言。与Whisper相比,虽然支持的语言总数减少,但每种语言的识别准确率显著提高。
Q3: 什么是GPT-4o-mini-transcribe?它与标准版有何不同?
A3: GPT-4o-mini-transcribe是更轻量级的版本,定价为标准版的一半($0.003/分钟)。它的错误率略高于标准版(约15-20%),但处理速度更快,更适合成本敏感或对准确度要求不那么严格的应用场景。
Q4: 流式API的延迟是多少?适合实时应用吗?
A4: GPT-4o-transcribe的流式API延迟最低可达300毫秒,完全适合实时应用如实时字幕、语音助手等。这一延迟水平接近人类感知的实时性,显著优于之前的模型。
Q5: 该模型能识别和区分多个说话者吗?
A5: 当前版本提供基本的说话者区分能力,但这不是其核心设计目标。如果应用强烈依赖说话者识别,可能需要将其输出与专门的说话者分离模型结合使用。OpenAI表示将在未来版本中增强这一功能。
Q6: 转录内容的隐私和安全如何保障?
A6: OpenAI承诺不使用通过API提交的数据训练模型,并提供30天的数据保留策略。对于高度敏感的应用,开发者应考虑实施额外的加密和数据匿名化措施。
总结与未来展望
GPT-4o-transcribe代表了AI语音转文字技术的重大飞跃,凭借显著降低的错误率、实时流式处理能力和强大的噪声适应性,为开发者提供了构建新一代语音应用的强大工具。
随着这一技术的普及,我们可以预期:
- 语音界面的普及:更精确的语音识别将加速语音界面在各行业的应用
- 内容可访问性提升:所有音频内容将变得可搜索、可索引,大幅提升信息获取效率
- 多语言沟通障碍的降低:实时高质量转录为跨语言交流创造新可能
- 新型语音应用生态:随着技术门槛降低,将涌现出更多创新型语音应用
未来的发展方向可能包括:更精确的多说话者区分能力、更深入的语义理解和情感分析、支持更多小语种和方言,以及与其他AI功能的更深度融合。
对于开发者和企业来说,现在正是探索和集成这一革命性技术的最佳时机,抢占语音交互的下一个前沿。