Playwright MCP完全指南:AI浏览器自动化从入门到精通(2025最新)
在AI飞速发展的今天,如何让大型语言模型(LLM)与真实网络世界交互成为关键问题。微软团队推出的Playwright MCP(Model Context Protocol)为此提供了革命性解决方案:让AI模型能够直接控制网页浏览器,执行复杂的交互任务,无需复杂的脚本编写。本文将全面解析Playwright MCP的工作原理、安装配置和实战应用,帮助你快速掌握这一强大工具。

一、Playwright MCP核心概念:突破AI与浏览器的交互壁垒
Playwright MCP是微软开发的一种服务器,允许大语言模型(LLM)通过结构化命令控制浏览器。它的核心创新在于依赖浏览器的可访问性树(accessibility tree)而非视觉图像处理,这带来了速度、可靠性和资源效率方面的显著优势。
1.1 传统浏览器自动化的局限
在Playwright MCP出现之前,AI与浏览器的交互主要依赖三种方式,各有明显缺陷:
- 截图识别法:模型通过分析网页截图来”理解”页面,再决定点击位置。这种方法资源密集、速度慢,且容易因界面微小变化而失效。
- HTML解析法:直接提取网页HTML给模型分析,但HTML结构复杂混乱,模型难以精确定位交互元素。
- 专用脚本法:为每个网站编写特定自动化脚本,开发成本高,维护困难,无法应对动态变化。
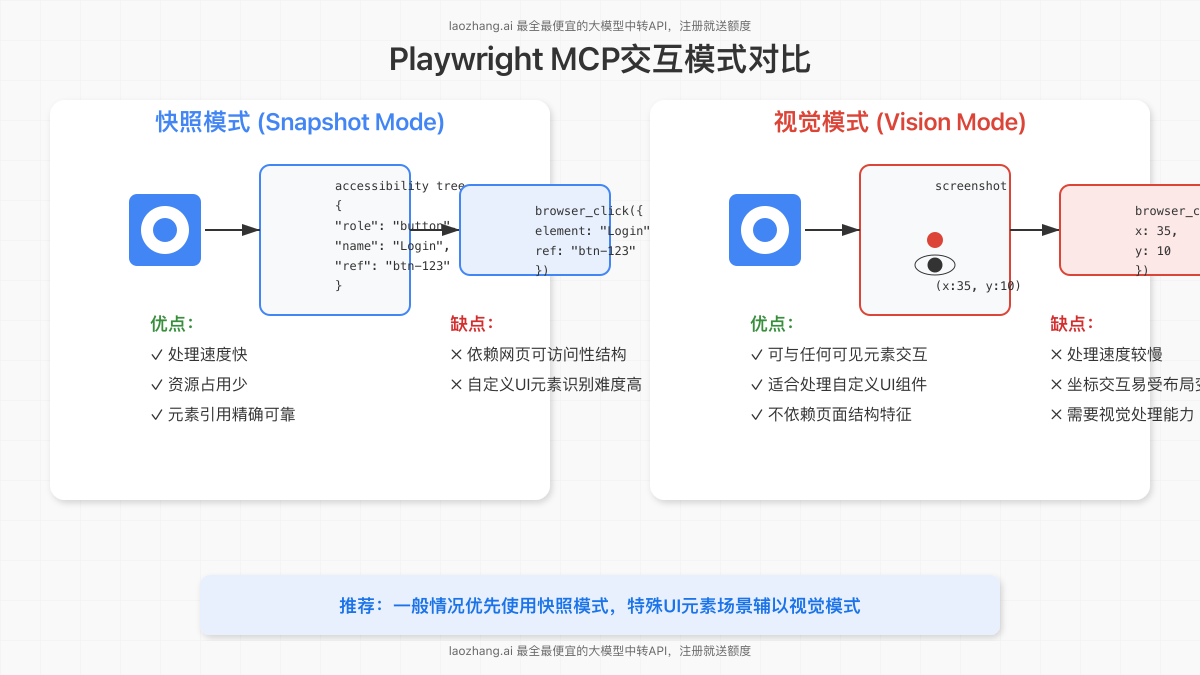
1.2 Playwright MCP的双重交互模式
Playwright MCP创新性地提出两种交互模式,针对不同场景提供最佳解决方案:
- 快照模式(Snapshot Mode,默认):不依赖视觉识别,而是利用浏览器的可访问性树,获取页面的结构化表示。这与屏幕阅读器使用的技术类似,包含元素的角色(按钮、链接、输入框)、名称、值和关系。
- 优势:处理速度快,资源占用少,提供结构化文本更适合LLM处理,交互精确且可靠。
- 局限:依赖网页具有良好的可访问性结构,对动态生成内容或自定义UI元素可能存在识别难度。
- 视觉模式(Vision Mode):类似传统视觉自动化工具,通过捕获网页截图,基于X、Y坐标进行交互。
- 优势:可与可访问性树中表示不清的元素交互,如自定义图形元素、画布绘图或视觉上独特的区域。
- 局限:速度较慢,基于坐标的交互容易因页面布局变化、窗口调整或元素位置移动而失效。
二、Playwright MCP安装与基础配置:从零开始
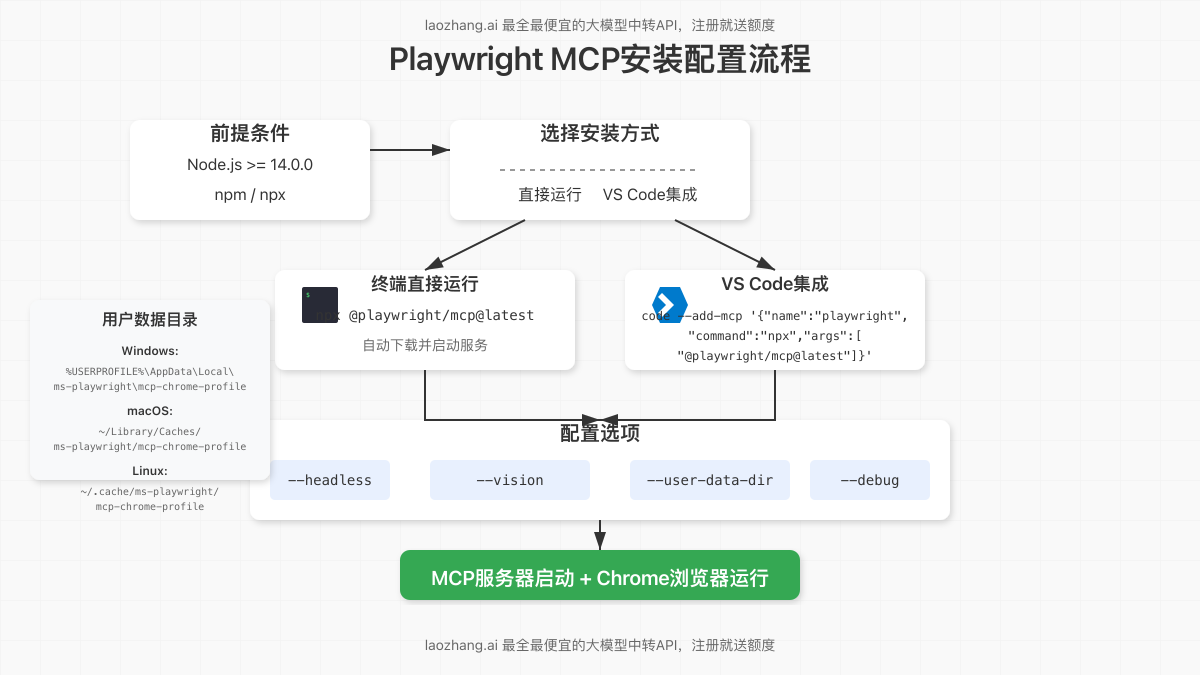
安装Playwright MCP非常简单,只需Node.js和npm(或npx)环境。下面提供几种常用的安装与配置方式。
2.1 直接运行服务器
最简单的启动方式是使用npx命令,无需永久安装:
npx @playwright/mcp@latest这个命令会:
- 下载最新版本的@playwright/mcp(如果本地缓存中没有)
- 启动MCP服务器
- 使用专用配置文件启动受控Chrome浏览器实例
- 监听来自MCP客户端的连接(如集成了VS Code的LLM代理或自定义应用程序)
默认情况下,服务器运行在快照模式并启动有界面浏览器(会显示浏览器窗口)。
2.2 在VS Code中安装配置
Playwright MCP设计了与VS Code中的GitHub Copilot等AI助手无缝集成的功能。配置方法如下:
方法1:使用VS Code命令行
# VS Code稳定版
code --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}'
# VS Code Insiders版
code-insiders --add-mcp '{"name":"playwright","command":"npx","args":["@playwright/mcp@latest"]}'这些命令将Playwright MCP服务器注册到VS Code的MCP处理系统,当浏览器自动化功能需要时,VS Code可自动启动并与该服务器通信。
方法2:手动配置(settings.json)
也可以在VS Code的settings.json文件中手动配置MCP服务器。打开设置(文件 > 首选项 > 设置或Ctrl/Cmd + ,),点击右上角的”打开设置(JSON)”图标,添加以下结构:
{
// ... 其他设置 ...
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
// 根据需要添加其他参数(如--headless, --vision)
}
}
// ... 其他设置 ...
}2.3 用户数据目录
Playwright MCP创建独立的浏览器配置文件来存储Cookie、会话信息和其他浏览器数据,确保自动化会话不会干扰常规浏览配置文件。根据操作系统不同,该配置文件的位置为:
- Windows:
%USERPROFILE%\AppData\Local\ms-playwright\mcp-chrome-profile - macOS:
~/Library/Caches/ms-playwright/mcp-chrome-profile - Linux:
~/.cache/ms-playwright/mcp-chrome-profile
如果需要全新的浏览器会话(例如登出所有网站),可以在启动MCP服务器前或会话之间删除此目录。
三、Playwright MCP高级配置选项
可以通过添加命令行参数修改Playwright MCP服务器的行为。以下是常用的高级配置选项。
3.1 无界面模式运行
要在没有可见GUI的情况下运行浏览器(适用于后台任务或服务器环境),使用--headless标志:
# 直接运行时
npx @playwright/mcp@latest --headless
# VS Code settings.json配置
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--headless" // 添加无界面标志
]
}
}
}3.2 在无显示器的Linux上运行有界面模式
在没有物理显示器的Linux服务器上(如云服务器),可以使用--headed-on-linux标志结合xvfb运行有界面浏览器:
# 首先安装xvfb
sudo apt update && sudo apt install -y xvfb
# 使用xvfb-run启动MCP服务器
xvfb-run npx @playwright/mcp@latest --headed-on-linux3.3 启用视觉模式
若需要使用视觉模式(基于截图和坐标的交互),添加--vision标志:
npx @playwright/mcp@latest --vision视觉模式适用于需要与可访问性树不能充分表示的元素交互的场景。
3.4 自定义用户数据目录
如需指定自定义用户数据目录,使用--user-data-dir参数:
npx @playwright/mcp@latest --user-data-dir=/path/to/custom/profile这对于在不同项目间分离浏览器配置非常有用。
3.5 调试模式
要在详细调试模式下运行服务器,添加--debug标志:
npx @playwright/mcp@latest --debug这将输出更详细的日志信息,帮助排查问题。
四、使用Playwright MCP工具:实际操作
Playwright MCP提供了一系列工具,让AI模型能够执行各种浏览器操作。这些工具根据交互模式(快照或视觉)而略有不同。
4.1 快照模式工具(默认)
以下是快照模式下的核心工具:
| 工具名称 | 功能描述 | 关键参数 |
|---|---|---|
browser_navigate |
导航到指定URL | url:要访问的完整URL |
browser_go_back |
返回上一页 | 无参数 |
browser_go_forward |
前进到下一页 | 无参数 |
browser_snapshot |
获取当前页面的可访问性快照 | 无参数 |
browser_click |
点击特定元素 |
element:元素描述ref:从快照获取的元素引用ID
|
browser_hover |
鼠标悬停在特定元素上 |
element:元素描述ref:元素引用ID
|
browser_type |
在可编辑元素中输入文本 |
element:元素描述ref:元素引用IDtext:要输入的文本submit:输入后是否按回车键(可选,默认false)
|
browser_select_option |
在下拉菜单中选择选项 |
element:元素描述ref:select元素的引用IDvalues:要选择的选项值数组
|
browser_press_key |
模拟按键操作 | key:键名(如”Enter”、”ArrowLeft”) |
browser_take_screenshot |
截取当前页面截图 | raw:可选,返回无损PNG格式 |
browser_wait |
暂停执行一段时间 | time:等待秒数(最多10秒) |
4.2 视觉模式工具
视觉模式下,工具集更加依赖坐标定位:
| 工具名称 | 功能描述 | 关键参数 |
|---|---|---|
browser_navigate |
导航到指定URL | url:要访问的完整URL |
browser_screenshot |
捕获当前页面截图 | 无参数 |
browser_move_mouse |
移动鼠标到特定坐标 |
x:水平坐标y:垂直坐标
|
browser_click |
在特定坐标处点击 |
x:水平坐标y:垂直坐标
|
browser_drag |
使用坐标执行拖放操作 |
startX:起始水平坐标startY:起始垂直坐标endX:结束水平坐标endY:结束垂直坐标
|
browser_type |
在当前光标位置输入文本 |
text:要输入的文本submit:是否按回车键(可选)
|
五、Playwright MCP实战案例
下面通过几个实际案例,展示Playwright MCP在不同场景中的应用。
5.1 自动化表单填写
以自动填写注册表单为例,基本流程如下:
- 导航到目标网站
- 获取页面快照
- 定位并填写表单字段
- 提交表单
具体实现步骤:
// 1. 导航到注册页面
browser_navigate(url="https://example.com/register")
// 2. 获取页面快照
snapshot = browser_snapshot()
// 3. 找到用户名输入框并填写
// 假设我们从快照中获取到用户名输入框的ref为"input-123"
browser_type(element="用户名输入框", ref="input-123", text="testuser", submit=false)
// 4. 找到密码输入框并填写
// 假设密码输入框的ref为"input-456"
browser_type(element="密码输入框", ref="input-456", text="securepassword", submit=false)
// 5. 找到注册按钮并点击
// 假设注册按钮的ref为"button-789"
browser_click(element="注册按钮", ref="button-789")5.2 自动化数据提取
以从产品页面提取信息为例:
// 1. 导航到产品页面
browser_navigate(url="https://example.com/products")
// 2. 获取页面快照
snapshot = browser_snapshot()
// 3. 分析快照内容,找到产品名称、价格、评分等关键信息
// 这一步通常由AI模型完成,从结构化的快照中提取所需数据
// 4. 如需翻页继续提取
// 假设"下一页"按钮的ref为"button-next"
browser_click(element="下一页按钮", ref="button-next")
// 5. 获取新页面快照
snapshot = browser_snapshot()
// 6. 继续提取数据...5.3 多步骤交互流程自动化
以电子商务网站购物流程为例:
// 1. 导航到电商网站
browser_navigate(url="https://example.com/shop")
// 2. 搜索特定产品
snapshot = browser_snapshot()
// 假设搜索框的ref为"input-search"
browser_type(element="搜索框", ref="input-search", text="智能手机", submit=true)
// 3. 从搜索结果中选择产品
snapshot = browser_snapshot()
// 假设第一个产品链接的ref为"link-product-1"
browser_click(element="产品链接", ref="link-product-1")
// 4. 添加到购物车
snapshot = browser_snapshot()
// 假设"添加到购物车"按钮的ref为"button-add-cart"
browser_click(element="添加到购物车按钮", ref="button-add-cart")
// 5. 进入购物车
browser_wait(time=1) // 等待购物车更新
snapshot = browser_snapshot()
// 假设"查看购物车"按钮的ref为"button-view-cart"
browser_click(element="查看购物车按钮", ref="button-view-cart")
// 6. 进入结账流程
snapshot = browser_snapshot()
// 假设"结账"按钮的ref为"button-checkout"
browser_click(element="结账按钮", ref="button-checkout")六、使用laozhang.ai中转API服务增强您的Playwright MCP应用
想要将Playwright MCP与强大的大语言模型结合使用?laozhang.ai提供高效稳定的API中转服务,让您轻松接入OpenAI、Claude、Gemini等顶级模型,实现真正智能化的浏览器自动化。
6.1 laozhang.ai中转API优势
- 最全面的模型支持:OpenAI全系列模型、Claude全系列、Gemini、Mistral等
- 超高性价比:相比官方API节省30-50%成本
- 稳定可靠:多节点冗余,保障服务24/7高可用
- 简单易用:与官方API完全兼容,仅需修改接口地址
- 免费额度:注册即送试用额度,无需信用卡
6.2 与Playwright MCP结合使用示例
以下是使用laozhang.ai API调用GPT模型进行网页内容分析的示例代码:
// 假设我们已经获取到网页快照
snapshot = browser_snapshot()
// 调用laozhang.ai API分析网页内容
const response = await fetch('https://api.laozhang.ai/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_API_KEY'
},
body: JSON.stringify({
model: 'gpt-3.5-turbo',
messages: [
{role: 'system', content: 'You are a web page analyzer.'},
{role: 'user', content: `分析以下网页快照,提取关键信息:${JSON.stringify(snapshot)}`}
]
})
});
const result = await response.json();
const analysis = result.choices[0].message.content;
// 根据分析结果执行下一步操作
// ...6.3 注册并开始使用
立即访问https://api.laozhang.ai/register/?aff_code=JnIT注册账号,获取免费试用额度。注册后,您将获得个人API密钥,可立即开始使用laozhang.ai的中转API服务。
更多咨询,请添加微信:ghj930213
七、常见问题与解决方案
7.1 无法启动MCP服务器
问题:执行npx @playwright/mcp@latest命令后,服务器无法启动。
解决方案:
- 确保Node.js版本≥14.0.0。可通过
node -v检查版本。 - 检查网络连接,确保能够下载Playwright包。
- 尝试清除npm缓存:
npm cache clean --force后重试。 - 在某些企业网络环境下,可能需要配置npm代理。
7.2 浏览器未显示(有界面模式)
问题:服务器启动成功,但浏览器窗口未显示。
解决方案:
- 检查是否意外使用了
--headless参数。 - 确认系统有图形界面支持。在远程服务器上,可能需要配置X11转发。
- 重启服务器,确保使用正确的启动命令。
- 尝试明确指定
--headed参数。
7.3 元素交互失败
问题:使用browser_click或browser_type等工具时,无法与目标元素交互。
解决方案:
- 确保在交互前已调用
browser_snapshot获取最新快照。 - 验证元素引用(ref)是否正确。这些引用在页面刷新或导航后会变化。
- 尝试添加
browser_wait(time=1)等待页面加载或动画完成。 - 对于动态加载内容,可能需要实现等待策略,多次获取快照直到目标元素出现。
- 考虑切换到视觉模式(
--vision),某些现代网站使用复杂UI框架可能在可访问性树中表示不完整。
7.4 权限或安全问题
问题:访问某些网站时遇到权限错误或安全限制。
解决方案:
- 某些网站可能检测自动化浏览器。尝试添加适当的用户代理参数。
- 对于需要登录的网站,确保正确管理Cookie和会话状态。
- 某些网站可能限制自动化访问。检查该网站的robots.txt和使用条款。
- 尝试使用自定义用户数据目录,保留登录状态:
--user-data-dir=/custom/path。
7.5 与特定AI模型集成问题
问题:AI模型无法正确解析或响应Playwright MCP输出。
解决方案:
- 确保AI模型有足够上下文理解网页快照结构。
- 对于复杂页面,可以使用预处理步骤简化快照数据。
- 明确提示模型如何解析和理解Playwright MCP的数据格式。
- 考虑使用laozhang.ai中转API连接高级模型如GPT-4或Claude 3,这些模型对结构化数据处理能力更强。
八、Playwright MCP进阶技巧
8.1 自动化测试集成
将Playwright MCP与自动化测试框架结合,可实现AI驱动的端到端测试:
- 使用大模型自动生成测试场景和测试数据
- 让AI分析测试结果,识别潜在问题
- 实现自适应测试,根据应用变化自动调整测试策略
8.2 内容审核与监控
结合AI和Playwright MCP可以创建强大的网站监控工具:
- 定期访问目标网站,检查内容变化
- 自动识别不适当内容或安全问题
- 监控竞争对手网站,分析价格和产品变化
8.3 多浏览器上下文管理
高级应用可能需要同时控制多个浏览器会话:
- 启动多个MCP服务器实例,每个使用不同端口
- 实现浏览器会话池管理,优化资源使用
- 使用不同用户配置文件模拟多用户场景
8.4 自定义插件开发
Playwright MCP支持扩展其功能集:
- 开发自定义工具增强MCP功能
- 创建特定领域的命令简化常见操作
- 实现特定网站的优化适配器
8.5 性能优化策略
在大规模应用中优化Playwright MCP性能:
- 实现智能快照策略,减少不必要的快照获取
- 优化元素选择策略,加快交互速度
- 利用浏览器缓存减少加载时间
- 在适当场景下使用快照模式和视觉模式的混合策略
九、结论与未来展望
Playwright MCP代表了AI与网络交互的重要突破。通过提供结构化的浏览器控制机制,它解决了传统自动化方法的核心痛点,为AI模型提供了一种高效、可靠的方式来理解和操作网页。
随着AI技术的快速发展,我们可以预见Playwright MCP未来将在以下方向继续演进:
- 增强理解能力:提供更丰富的语义信息,帮助AI更好理解网页内容和结构
- 多模态交互:整合视觉、音频和其他感知模式,实现更自然的网页交互
- 安全与隐私保障:发展更健全的权限模型,确保自动化操作的安全边界
- 跨平台扩展:将类似功能扩展到移动应用和其他界面系统
对于开发者和企业而言,现在正是开始探索和应用这一技术的最佳时机。通过结合像laozhang.ai这样的高性能API服务,您可以构建智能度更高、效率更优的自动化系统,释放AI与网络交互的无限潜力。
立即行动
1. 安装并尝试Playwright MCP:npx @playwright/mcp@latest
2. 注册laozhang.ai获取免费API额度:https://api.laozhang.ai/register/?aff_code=JnIT
3. 探索更多学习资源:Playwright官方文档、Github代码库、社区示例
让我们共同迎接AI驱动的浏览器自动化新时代!