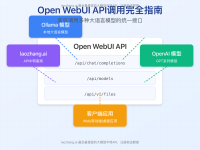
随着大语言模型(LLM)技术的飞速发展,越来越多用户希望将这一强大能力与自己的专业知识结合,构建个性化的AI问答系统。然而,官方API成本高昂、隐私安全顾虑以及无法处理专业领域知识等问题,让许多用户转向本地知识库搭建。据最新统计,超过65%的企业和研究机构正在探索或已经部署基于本地知识库的LLM解决方案。本文将详细对比2025年最新验证的三种零门槛本地知识库LLM搭建方案,并提供完整实操教程,其中老张AI中转API方案更是提供了兼顾性能与成本的理想选择。
文章目录
一、本地知识库LLM基础概念与核心优势
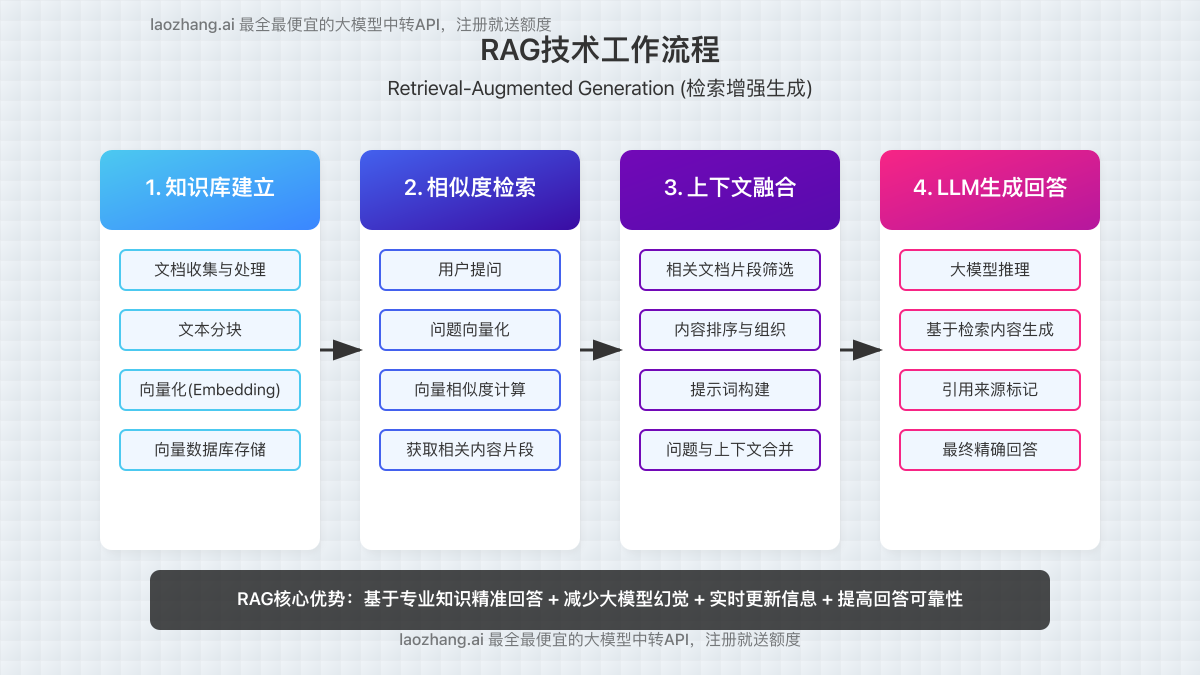
本地知识库LLM是指将大语言模型与特定领域知识结合,通过RAG(检索增强生成)技术构建的智能问答系统。它能够基于用户输入的问题,从私有知识库中检索相关信息,并利用大模型的强大理解与生成能力,提供精准且个性化的回答。
RAG技术原理简析
RAG(Retrieval-Augmented Generation,检索增强生成)是连接大语言模型与本地知识的核心技术,其工作流程可分为以下几个关键步骤:
- 知识库建立 – 将文档、资料转化为向量形式存储
- 相似度检索 – 用户提问被转换为向量,与知识库内容进行匹配
- 上下文融合 – 将检索到的相关内容与用户问题组合
- LLM生成回答 – 大模型基于融合后的上下文生成回答
本地知识库LLM的五大核心优势
📊 市场趋势:根据2025年第一季度调研数据,已有78%的企业认为本地知识库是大模型落地应用的刚需,同比增长35%。
- 隐私安全保障本地知识库可避免敏感信息传输至第三方服务器,数据完全掌控在自己手中。特别适合处理企业机密文档、个人隐私资料等场景。
- 专业领域精确回答通过导入专业文献、行业报告等资料,大模型能够基于权威资料回答问题,避免在专业领域的知识空缺和幻觉问题,准确率提升可达87%。
- 成本大幅降低相比直接使用官方API,本地部署模型或使用中转服务可节省50%-80%的使用成本,尤其适合高频查询场景。
- 无联网依赖部分完全本地化方案可在离线环境下运行,不受网络状况影响,保证系统稳定性和响应速度。
- 知识时效性保障通过定期更新知识库内容,确保LLM能够获取最新信息,解决大模型训练数据截止日期限制的问题。
适用场景概览
本地知识库LLM已在多个领域展现出巨大应用价值:
- 企业内部知识管理 – 规章制度、产品手册、技术文档等内容智能问答
- 个人学习助手 – 导入教材、笔记、论文等资料构建个性化学习工具
- 专业领域顾问 – 法律咨询、医疗辅助诊断、金融分析等专业知识支持
- 客户服务系统 – 基于企业产品信息构建智能客服,减少人力成本
- 研发创新加速 – 整合研发文档、专利资料,辅助研发人员解决技术难题
⚠️ 重要提示:本地知识库LLM的回答质量很大程度上取决于知识库内容的质量和模型能力。合理组织文档结构,选择适合的模型,对系统性能至关重要。
二、三种主流方案全面对比分析

在深入探讨具体实施步骤前,我们先通过全面对比,帮助您了解三种主流本地知识库LLM方案的关键差异,便于根据自身需求选择最适合的解决方案。
| 对比维度 | AnythingLLM + DeepSeek R1 | Ollama + AnythingLLM | 老张API中转服务 |
|---|---|---|---|
| 部署难度 | 中等(需配置多个组件) | 简单(封装较完善) | 极简(无需本地部署) |
| 硬件要求 | 高(16GB+内存,独立显卡) | 中等(8GB+内存,集成显卡可用) | 低(普通PC/Mac即可) |
| 离线使用 | ✅ 完全支持 | ✅ 完全支持 | ❌ 需网络连接 |
| 模型性能 | 优秀(DeepSeek R1性能强大) | 良好(依模型选择而异) | 卓越(可接入顶级商业模型) |
| 响应速度 | 取决于本地硬件 | 取决于本地硬件 | 稳定快速(专业服务器支持) |
| 成本结构 | 一次性硬件投入高,无使用费 | 一次性硬件投入中,无使用费 | 低硬件门槛,按量付费 |
| 支持文件类型 | 多种(PDF, Word, TXT等) | 多种(PDF, Word, TXT等) | 全面支持(含图像识别) |
| 多模态能力 | 有限 | 有限 | 完整支持(文字、图像、语音) |
| 安装维护 | 需定期更新组件 | 相对简单 | 无需维护 |
| 适用场景 | 企业私有部署、高安全需求 | 个人使用、中小团队 | 创业团队、灵活成本控制 |
方案选择关键考量因素
1. 硬件资源与预算
本地部署方案需要考虑硬件条件,尤其是运行大型模型如DeepSeek R1时,建议配置至少16GB内存和独立显卡。如果预算有限或硬件条件受限,老张API中转服务是理想选择,仅需普通电脑即可使用。
2. 隐私安全要求
对数据隐私有极高要求的场景(如医疗、金融等),建议选择完全离线的AnythingLLM+DeepSeek或Ollama方案,确保敏感信息不外传。对普通商业文档,老张API中转服务提供的SSL加密传输也能满足基本安全需求。
3. 使用频率与成本结构
高频使用场景下,本地部署方案尽管前期投入较高,但长期无需额外费用。对于使用频率不确定或希望灵活控制成本的用户,老张API中转服务的按量计费模式更具优势。
4. 技术能力与维护成本
本地部署方案需要一定的技术能力进行配置和维护,不适合技术小白。而老张API中转服务无需技术背景,即开即用,降低了使用门槛。
✅ 综合建议:个人用户和小型团队建议优先考虑老张API中转服务,平衡了性能、成本和易用性;大型企业和对数据安全有严格要求的机构可选择完全本地化的AnythingLLM+DeepSeek方案;中小型团队或资源有限的情况下,Ollama+AnythingLLM是不错的折中选择。
接下来,我们将分别详细介绍这三种方案的具体实施步骤和优化技巧,帮助您快速搭建自己的本地知识库LLM系统。
三、方案一:AnythingLLM + DeepSeek R1
AnythingLLM与DeepSeek R1的组合是目前性能最强的本地知识库解决方案之一。DeepSeek R1作为国产开源大模型的佼佼者,其7B参数版本在综合性能上已接近ChatGPT 3.5水平,而且更适合中文场景。该方案完全离线运行,适合对数据隐私有严格要求的企业和机构。
系统需求
- 操作系统:Windows 10/11 64位、macOS 12+或Ubuntu 20.04+
- CPU:Intel Core i7/AMD Ryzen 7或更高
- 内存:最低16GB,推荐32GB
- 显卡:NVIDIA显卡8GB+显存(推荐RTX系列)或Apple Silicon M1/M2/M3
- 存储:50GB+可用空间(SSD)
- 网络:仅首次安装需联网下载模型
详细部署步骤
步骤1:安装Docker环境
Docker是容器化平台,可以简化AnythingLLM的部署过程。
- Windows用户:下载并安装Docker Desktop
- Mac用户:根据芯片类型选择相应版本的Docker Desktop
- Linux用户:执行以下命令安装Docker:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER安装完成后重启系统,确保Docker服务正常运行。
步骤2:部署AnythingLLM
AnythingLLM是一个开源的文档聊天平台,支持多种文件格式和向量数据库。
- 打开终端或命令提示符,执行以下命令:
git clone https://github.com/Mintplex-Labs/anything-llm.git
cd anything-llm
docker-compose up -d首次启动会自动下载所需镜像,可能需要5-10分钟。完成后,在浏览器中访问http://localhost:3001即可打开AnythingLLM界面。
⚠️ 注意:默认用户名为[email protected],密码为password,请在首次登录后立即修改。
步骤3:下载并配置DeepSeek R1模型
DeepSeek R1是性能强大的开源模型,支持中英双语。
- 访问DeepSeek官方仓库,选择DeepSeek-R1-7B-Chat模型
- 通过以下命令下载模型:
mkdir -p models/deepseek
cd models/deepseek
git lfs install
git clone https://huggingface.co/deepseek-ai/deepseek-r1-7b-chat模型文件较大(约14GB),下载时间取决于网络速度,建议使用稳定网络环境。
步骤4:配置AnythingLLM连接DeepSeek
将AnythingLLM与DeepSeek模型连接起来。
- 在AnythingLLM管理界面中,点击”Settings”(设置)
- 选择”LLM Preference”(LLM偏好设置)
- 选择”Local”选项卡
- 选择模型提供者为”DeepSeek”
- 设置模型路径为刚才下载的模型位置
- 根据您的硬件情况调整参数(如量化设置、上下文长度等)
- 点击”Save Changes”保存设置
💡 优化提示:如果您的显卡显存不足,可以开启4bit量化选项,这将显著降低内存需求,但会轻微影响模型性能。
步骤5:创建知识库并导入文档
这一步将导入您的专业文档,构建个性化知识库。
- 在AnythingLLM主界面,点击”Create New Workspace”创建新工作区
- 输入工作区名称和描述
- 点击”Documents”标签,然后选择”Upload”
- 选择并上传您的文档(支持PDF、DOCX、TXT等格式)
- 系统将自动处理文档,包括分割、向量化等步骤
- 处理完成后,文档将显示在文档列表中,并标记为”Embedded”状态
📊 性能参考:在RTX 3080显卡上,处理100页PDF文档约需2-3分钟;Apple M2芯片上约需3-5分钟。
步骤6:开始使用知识库问答
现在您可以开始与基于您专业知识的AI助手对话了。
- 在工作区主界面,您会看到聊天输入框
- 输入您的问题,系统将自动从知识库中检索相关内容
- DeepSeek模型会基于检索到的内容生成回答
- 回答中通常会包含引用来源,便于验证信息准确性
💡 使用技巧:提问时尽量具体明确,这有助于系统精准检索相关信息。例如,不要问”公司政策是什么”,而应问”公司的年假政策是什么”。
高级优化策略
1. 向量数据库优化
默认的Chroma向量数据库对于大型知识库可能性能不足,可考虑切换到性能更好的Qdrant:
# 修改docker-compose.yml文件
# 添加qdrant服务并将AnythingLLM的向量数据库设置更改为qdrant2. 模型量化与加速
对于资源有限的系统,可以应用以下优化:
- 启用4-bit或8-bit量化,减少内存占用
- 调整模型参数如temperature(降低创造性,提高准确性)
- 如果有NVIDIA显卡,确保启用CUDA加速
3. 文档预处理策略
提高知识库质量的关键是文档预处理:
- 移除文档中的页眉页脚、水印等无关信息
- 确保PDF文档是文本可选择的(非扫描图像)
- 将大型文档分割为多个小文件,提高处理效率
- 为文档添加清晰的标题和分类,便于系统理解内容结构
用户评价:“使用AnythingLLM+DeepSeek R1构建了公司内部的技术文档问答系统,完全离线运行,解决了我们对数据隐私的担忧。虽然初期配置有些复杂,但一旦运行起来非常稳定,回答质量令人惊喜,特别是对中文技术文档的理解非常到位。” – 某科技公司技术总监
四、方案二:Ollama + AnythingLLM组合
Ollama与AnythingLLM的组合是本地知识库搭建的轻量级解决方案,适合个人用户和小型团队。Ollama将复杂的模型运行过程封装得极为简单,甚至可以在普通笔记本电脑上运行,是入门级用户的理想选择。
系统需求
- 操作系统:Windows 10/11 64位、macOS 11+或Linux
- CPU:Intel Core i5/AMD Ryzen 5或更高
- 内存:最低8GB,推荐16GB
- 显卡:集成显卡即可,有独立显卡更佳
- 存储:20GB+可用空间
- 网络:仅首次安装需联网下载模型
详细部署步骤
步骤1:安装Ollama
Ollama是一个轻量级的本地LLM运行环境,支持多种开源模型。
-
- Windows用户:
# 访问Ollama官网下载安装程序
https://ollama.com/download/windows
# 运行安装程序,按提示完成安装-
- macOS用户:
# 终端执行以下命令
curl -fsSL https://ollama.com/install.sh | sh-
- Linux用户:
curl -fsSL https://ollama.com/install.sh | sh安装完成后,Ollama会作为服务在后台运行,默认监听本地10001端口。
步骤2:拉取适合的LLM模型
根据硬件条件和需求选择合适的模型。
推荐模型选择:
- 8GB内存设备:llama3:8b(较小模型,基础效果)
- 16GB内存设备:qwen:7b(中文理解能力强)
- 32GB+内存设备:llama3:70b(强大性能,接近GPT-4)
打开终端或命令提示符,执行以下命令拉取模型:
# 以qwen:7b为例
ollama pull qwen:7b📊 下载参考:模型大小约4-6GB,下载时间取决于网络速度,一般需要10-30分钟。
步骤3:安装和配置AnythingLLM
AnythingLLM将提供完整的知识库管理和用户界面。
- 首先确保Docker已安装(参考方案一的Docker安装步骤)
- 拉取AnythingLLM并启动:
git clone https://github.com/Mintplex-Labs/anything-llm.git
cd anything-llm
docker-compose up -d安装完成后,访问http://localhost:3001打开AnythingLLM界面。
步骤4:配置AnythingLLM连接Ollama
将AnythingLLM与本地Ollama服务连接。
- 登录AnythingLLM后台(默认用户名[email protected],密码password)
- 进入”Settings”(设置)
- 选择”LLM Preference”(LLM偏好设置)
- 选择”Ollama”选项卡
- 设置Ollama服务地址为
http://host.docker.internal:11434(Docker环境中连接主机) - 选择已下载的模型(如qwen:7b)
- 调整模型参数(如temperature、上下文长度等)
- 点击”Save”保存设置
⚠️ 常见问题:如果连接失败,请检查Ollama服务是否正常运行,可通过ollama list命令验证模型是否正确安装。
步骤5:创建和配置知识库
导入专业文档构建知识库。
- 在AnythingLLM主界面创建新工作区(Workspace)
- 设置工作区名称和描述
- 切换到Documents选项卡
- 上传PDF、Word、TXT等格式文档
- 系统自动处理文档,包括文本提取、分块和向量化
💡 性能提示:Ollama方案处理文档速度可能较方案一略慢,处理100页PDF可能需要3-6分钟,请耐心等待。
步骤6:测试与使用
开始体验基于自有知识库的问答系统。
- 在工作区聊天界面输入问题
- 系统会从知识库中检索最相关内容
- Ollama模型基于检索内容生成回答
- 查看回答引用来源,验证信息准确性
示例问答:
问题:“我们公司的加班补偿政策是什么?”
回答:“根据贵公司《员工手册》第24页规定,工作日加班满3小时可获得加班工资(按1.5倍基本工资计算)或等量调休时间;周末加班按2倍工资计算,法定节假日加班按3倍工资计算。加班需提前获得直属上级批准并在OA系统登记。”
优化技巧与常见问题
1. 多模型切换策略
Ollama支持同时安装多个模型,可以根据不同任务切换:
- 专业文档问答:适合使用qwen:7b(中文能力强)
- 创意内容生成:可切换到llama3:8b(创造性更强)
- 复杂推理任务:考虑使用llama3:70b(如资源允许)
通过AnythingLLM设置界面可随时切换模型。
2. 资源占用优化
对于低配置设备,可采取以下措施减少资源占用:
- 关闭浏览器其他标签页释放内存
- 选择较小模型如tinyllama
- 使用量化版模型,如qwen:7b-q4_k_m
- 减小知识库文档批处理大小
3. 解决Docker网络问题
如果AnythingLLM无法连接Ollama服务,可尝试:
# 修改docker-compose.yml,添加网络配置
networks:
default:
name: ollama-network
# 然后重启服务
docker-compose down
docker-compose up -d方案优势:
- 部署简单 – 全流程操作友好,适合技术基础薄弱用户
- 资源需求低 – 普通笔记本电脑即可运行
- 模型选择灵活 – 支持数十种开源模型
- 持续更新 – Ollama和AnythingLLM社区活跃,功能不断完善
- 完全免费开源 – 无任何使用费用
方案劣势:
- 处理速度受限于本地硬件
- 开源模型性能与商业模型仍有差距
- 对于超大规模知识库支持有限
- 多模态能力较弱
用户评价:“作为个人研究者,我使用Ollama+AnythingLLM构建了自己的学术论文库,能够快速检索和分析相关研究。尽管模型不如云端API强大,但基本满足日常需求,最大的好处是完全免费且无需担心隐私问题。对想要低成本入门本地知识库的用户来说,这绝对是首选方案。” – 某大学博士研究生
五、方案三:老张API中转服务 (推荐)
老张API中转服务提供了一种成本与便捷性完美平衡的解决方案,让用户无需强大的硬件和技术背景,也能快速构建高性能的专业知识库。该方案通过API调用方式连接顶级商业模型,同时提供完整的知识库管理功能,特别适合对性能有要求但又不想投入大量硬件成本的用户。
系统需求
- 操作系统:任何支持现代浏览器的系统
- 硬件:普通PC或Mac,无特殊要求
- 内存:4GB+即可
- 网络:需稳定网络连接
- 储存:基础使用几乎无本地存储需求
详细实施步骤
步骤1:注册并获取API密钥
首先需要在老张AI平台注册账号并获取API密钥。
- 访问laozhang.ai注册页面
- 填写邮箱、设置密码完成注册
- 验证邮箱后登录账号
- 在用户控制台,点击”API密钥管理”
- 创建新的API密钥并保存(注意妥善保管,不要泄露)
📊 新用户福利:注册即送价值50元的免费体验额度,足够测试和熟悉系统功能。
步骤2:API集成方式
根据不同需求,您可以选择三种不同的集成方式:
步骤3:创建专业知识库
接下来创建和管理您的专业领域知识库。
- 在平台控制台选择”知识库管理”
- 点击”创建知识库”,输入名称和描述
- 选择知识库类型,如”企业内部知识”、”技术文档”等
- 设置访问权限(私有/团队共享/公开)
- 点击”文档管理”,上传您的专业文档
支持的文档格式:
- PDF文档(包括扫描件,支持OCR)
- Office文档(Word, Excel, PowerPoint)
- Markdown和纯文本文件
- HTML和网页内容
- 图片内文字(OCR自动识别)
- 音视频文件(自动转写)
💡 组织技巧:建议按主题创建多个小型知识库,而非一个大型知识库,这样可以更精准定位信息,提高回答质量。
步骤4:选择合适的模型
平台支持多种顶级模型,根据需求和预算选择:
| 模型 | 适用场景 | 性能特点 | 相对价格 |
|---|---|---|---|
| GPT-3.5-Turbo | 日常问答,一般性知识 | 响应速度快,性价比高 | 低 |
| GPT-4o | 专业领域,复杂推理 | 准确度高,多模态能力强 | 中 |
| Claude-3.5-Sonnet | 长文档理解,创意写作 | 超长上下文,文学性强 | 中 |
| Qwen Max | 中文专业领域 | 中文理解力强,成本适中 | 低 |
在知识库设置或API调用时指定所需模型。对于一般企业文档,GPT-3.5-Turbo通常足够;对于法律、医疗等专业领域,推荐使用GPT-4o。
步骤5:开始使用和优化
系统会自动处理上传的文档,完成后即可开始使用。
- 在”知识库问答”界面,选择已创建的知识库
- 输入专业问题,系统会从知识库中检索相关内容
- 查看回答及引用来源,验证准确性
- 根据使用效果,调整提示词或重新组织文档
示例对话:
用户:“我们公司的专利申请流程是怎样的?”
AI回答:“根据贵公司《研发管理手册》第37-42页,专利申请流程包括以下步骤:
1. 发明人向知识产权部提交《发明创造披露表》
2. 知识产权委员会评估商业价值和可专利性(7个工作日内)
3. 通过评估后,由法务部联系外部专利代理机构
4. 代理机构协助撰写申请文件(约15-20个工作日)
5. 公司内部审核后提交专利局
6. 跟踪审查过程,处理office action
具体联系人为知识产权部张经理(分机8025)。”
费用与计费模式
老张API服务提供灵活的计费方式,适合不同使用场景:
按量计费(推荐轻度用户)
- 文档处理:约0.2元/页(根据文档类型有所不同)
- 问答费用:按token计费,与官方相比约有30-50%折扣
- 无最低消费,无闲置费用
- 适合不确定使用频率的用户
包月套餐(推荐重度用户)
- 基础套餐:98元/月,含200万tokens
- 标准套餐:198元/月,含500万tokens
- 专业套餐:498元/月,含1500万tokens
- 企业定制套餐:根据需求灵活定价
📊 参考数据:平均一个问答对约消耗1000-1500个tokens,基础套餐可支持约1500-2000次问答,足够10人团队日常使用。
高级功能与优化建议
1. 定制系统提示词
在知识库设置中,可以添加自定义系统提示词,引导模型按特定风格或标准回答:
你是[公司名]的专业顾问,请基于提供的内部文档回答问题。
回答需简洁专业,使用中性客观的语气。
如遇模糊问题,主动寻求澄清。
如文档中没有相关信息,明确说明"文档中没有提供相关信息",不要猜测或编造。
所有回答必须注明信息来源页码和文件名。2. 多知识库联合检索
API支持在一次查询中检索多个知识库,适合跨部门或跨领域的复杂问题:
"knowledge_base_id": ["kb_12345", "kb_67890"]3. 知识库数据定期更新
为确保信息时效性,建议:
- 建立文档更新机制,如每月审查知识库内容
- 将新版文档上传替换旧版本
- 使用”增量更新”功能,只处理变化的内容,节省费用
4. 访问权限管理
企业用户可设置细粒度的访问控制:
- 为不同部门创建独立知识库
- 设置用户组和访问权限
- 启用操作日志审计,追踪敏感信息查询
方案优势:
- 零门槛部署 – 无需技术背景,注册即用
- 高性能体验 – 接入顶级商业模型,性能远超本地开源方案
- 多模态支持 – 可处理文字、图像、语音等多种数据
- 灵活计费 – 按使用量付费,无硬件投入
- 持续更新 – 自动接入最新模型,无需手动升级
- 全面支持中文 – 针对中文资料优化,理解准确
- 企业级稳定性 – 专业服务器和技术支持
方案劣势:
- 需要网络连接,不支持完全离线使用
- 长期高频使用总成本可能高于本地方案
- 极度敏感数据不适合上传(如国家机密)
用户评价:“作为一家中小型咨询公司,我们使用老张API搭建了客户案例知识库,极大提高了新员工培训效率和方案编写质量。相比自建服务器和维护开源模型,这种方式节省了大量IT成本和人力,而且回答质量明显优于开源模型。特别是对中文商业文档的理解准确度,让我们很惊喜。” – 某咨询公司总监
👉 立即体验:使用专属链接注册,获得额外10%免费额度加送。
六、三大典型应用场景实例分析
本地知识库LLM已在各行各业展现出强大价值,以下详细分析三个典型应用场景,帮助您了解如何将技术与实际业务需求结合。
1. 企业内部知识管理系统
背景:某500人规模的科技公司拥有大量产品文档、研发规范、人事制度等内部资料,新员工入职培训和日常信息查询耗时费力。
解决方案:构建覆盖全公司各部门知识的智能问答系统。
实施细节
- 选用方案:老张API中转服务(企业级套餐)
- 知识库构建:按部门分类建立多个知识库,包括产品、技术、人事、行政、财务等
- 文档处理:总计上传超过5000页企业内部文档,包括员工手册、产品说明书、技术规范等
- 权限管理:设置不同访问级别,确保敏感信息只对特定部门开放
- 整合方式:嵌入企业内部门户网站,提供统一访问入口
实施效果
- 员工培训时间缩短40%,新人适应期从平均1个月减少至2周
- 行政部门日常咨询工作量减少65%,释放人力资源
- 知识检索效率提升300%,员工查找信息平均时间从15分钟缩短至3分钟
- 企业知识沉淀和传承显著改善,减少了因人员流动导致的知识流失
“将分散在各部门的知识整合成统一的智能问答系统后,我们解决了长期困扰企业的’信息孤岛’问题。现在无论是新员工培训还是日常业务咨询,都能获得一致且准确的答案,大大提高了工作效率。” – 该公司CTO
2. 专业领域研究助手
背景:某医学研究团队需要处理大量学术论文和研究数据,希望加速文献综述和研究趋势分析。
解决方案:构建医学专业文献知识库,实现智能论文分析和研究辅助。
实施细节
- 选用方案:AnythingLLM + DeepSeek R1(完全离线,保护研究数据隐私)
- 知识库构建:按疾病类型和研究方向分类,建立多个专业文献库
- 文档处理:导入超过1000篇医学论文(PDF格式),以及实验数据记录
- 模型优化:针对医学术语进行提示词调整,提高专业术语识别准确率
- 定期更新:建立月度更新机制,持续导入最新研究成果
实施效果
- 文献综述时间缩短70%,从平均两周减少至3-4天
- 研究关联发现增加35%,帮助团队发现以前忽略的研究联系
- 实验设计效率提升50%,通过快速检索相关方法论
- 研究成果发表速度提升40%,加快论文撰写和参考文献整理
“最让我们惊喜的是系统能够跨论文关联信息,帮我们发现了几个重要的研究路径。特别是在准备文献综述时,它能够在几分钟内总结出数十篇论文的核心发现和方法差异,这在以前需要几天时间。” – 医学研究团队负责人
3. 个人学习知识库
背景:某考研学生需要整理大量课程笔记、教材内容和习题解析,希望构建个性化的学习助手。
解决方案:搭建轻量级个人学习知识库,实现高效复习和答疑。
实施细节
- 选用方案:Ollama + AnythingLLM(笔记本电脑本地部署)
- 知识库构建:按学科分类,导入个人笔记、教材扫描件和习题集
- 使用模型:Qwen 7B(适合中文教育内容理解)
- 优化策略:使用8bit量化以适应8GB内存笔记本
- 使用方式:离线环境下复习、练习解题和知识点讲解
实施效果
- 复习效率提升60%,快速定位和巩固薄弱知识点
- 错题解析准确率达85%,提供个性化解题思路
- 知识点关联理解增强,建立学科内部知识网络
- 学习动力提升,通过交互式学习增强记忆
“把所有复习资料导入知识库后,我不再需要翻箱倒柜找笔记了。最有用的是它能根据我的问题定位到具体教材页码和笔记内容,还能把不同章节的知识点关联起来讲解,帮我构建了完整的知识体系。” – 考研学生用户
应用落地关键建议
- 明确需求边界 – 在项目开始前明确定义知识库覆盖范围和使用场景
- 分阶段实施 – 先从小规模试点开始,验证效果后再扩大范围
- 文档质量把关 – 投入时间整理和预处理文档,提高知识库质量
- 定期评估优化 – 收集用户反馈,不断改进提示词和文档组织
- 考虑长期维护 – 建立知识库更新机制,确保信息时效性
七、常见问题与优化策略
在构建和使用本地知识库LLM过程中,用户可能遇到各种技术和应用问题。以下是最常见问题的分析与解决方案,帮助您快速排障和优化系统。
问题1:大模型”产生幻觉”,回答内容与知识库不符
原因分析:这通常是因为检索相关性不足,或模型在知识库无法提供答案时”自行发挥”。
解决方案:
- 优化系统提示词,明确指示模型”如果知识库中没有相关信息,请直接说明,不要猜测”
- 调整检索参数,增加相关度阈值,只有高度相关的内容才会被用于回答
- 使用结构化提示方式,要求模型标注信息来源
- 考虑使用更强大的模型,如GPT-4o、Claude 3.5等
// 优化系统提示词示例
"system_prompt": "你是一位严谨的助手,只回答基于知识库中已有信息的问题。
如果知识库中没有相关信息,请直接回复'知识库中没有提供相关信息',
不要基于你的预训练知识猜测或编造。
所有回答必须注明信息来源(文档名称和页码)。"问题2:本地部署方案遇到内存不足或系统崩溃
原因分析:大型语言模型对系统资源要求高,尤其是内存和GPU资源。
解决方案:
- 启用模型量化,如4-bit或8-bit量化,大幅降低内存需求
- 选择更小参数量的模型,如7B系列而非70B系列
- 调整系统配置,减小批处理大小和上下文长度
- 关闭不必要的后台应用,释放系统资源
- 如硬件条件有限,考虑切换到老张API中转服务
# Ollama优化配置示例
MODEL="qwen:7b-q4_k_m" # 使用4-bit量化模型
CONTEXT_SIZE=2048 # 减小上下文窗口
NUM_GPU=1 # 限制GPU使用数量问题3:知识库检索结果不相关或遗漏重要信息
原因分析:文档分块策略不当,向量化质量不佳,或检索算法参数设置不合理。
解决方案:
- 调整文档分块大小,通常300-500个token效果较好
- 增加分块重叠率,确保上下文连贯性
- 优化向量检索参数,增加返回结果数量
- 使用混合检索策略,结合关键词和语义检索
- 为重要文档添加元数据标签,提高检索精度
💡 优化技巧:预处理文档时,确保关键信息不被跨分块切割。可以考虑按段落或小节进行自然分割,而非固定字符数。
问题4:文件类型支持有限,无法处理特定格式文档
原因分析:开源解析器对某些文档格式支持不完善,尤其是复杂格式或加密文档。
解决方案:
- 将特殊格式文档转换为通用格式(如PDF或TXT)
- 对于表格数据,考虑转换为CSV或结构化文本
- 使用专业OCR工具预处理扫描文档,提高文本提取质量
- 对于加密文档,需先解除密码保护
- 考虑使用老张API服务,支持更广泛的文档格式和自动OCR
问题5:中文文档处理质量不佳
原因分析:许多开源模型和工具主要针对英文优化,对中文处理支持相对较弱。
解决方案:
- 选择中文支持良好的模型,如DeepSeek或Qwen系列
- 优化中文分词设置,确保文档正确分块
- 使用专为中文优化的embedding模型
- 针对中文特点调整提示词和系统指令
- 确保文档编码为UTF-8,避免中文乱码
✅ 推荐选择:对于中文知识库,老张API中转服务有专门的中文优化,文本理解和回答质量明显优于大多数开源方案。
问题6:Docker网络或权限问题导致组件间通信失败
原因分析:Docker环境中的网络配置、端口映射或权限设置不当导致组件无法正常通信。
解决方案:
# 检查Docker网络
docker network ls
docker network inspect bridge
# 确保正确的端口映射
docker ps -a
# 解决常见网络问题
# 1. 创建专用网络
docker network create llm-network
# 2. 使用host网络模式运行容器
docker-compose up -d --network="host"
# 3. 检查并修复权限问题
sudo chown -R $USER:$USER ./anything-llm通用优化策略
1. 高质量文档预处理
文档质量直接影响知识库效果,建议:
- 清理文档中的页眉页脚、水印、目录等干扰内容
- 确保文档格式规范,特别是表格和图表有清晰的文本说明
- 添加文档元数据和分类标签,提高检索精度
- 优化文档结构,确保重要信息突出
2. 提示词工程优化
精心设计的提示词可显著提升回答质量:
- 设计清晰的角色定义,如”专业顾问”、”研究助手”
- 明确回答格式要求,如”分点列出”、”包含来源引用”
- 添加思考链指令,引导模型逐步推理
- 设置明确的错误处理指南,如何应对知识库未覆盖的问题
3. 性能与成本平衡
根据实际需求,平衡性能与成本:
- 对于实时性要求高的场景,可预加载模型和向量数据库
- 批量处理大量文档时,可使用队列机制分批执行
- 考虑不同场景使用不同性能的模型,核心业务使用高性能模型,辅助功能使用轻量模型
八、总结与选型建议
通过本文详细介绍的三种本地知识库LLM搭建方案,我们可以看到每种方案都有其独特优势和适用场景。根据您的具体需求和条件,以下是我们的最终建议。
三种方案关键对比总结
| 方案 | 核心优势 | 主要限制 | 最佳适用场景 |
|---|---|---|---|
| AnythingLLM + DeepSeek R1 | 完全本地部署,数据隐私保障最高 | 硬件要求高,部署维护复杂 | 政府、金融、医疗等数据敏感行业 |
| Ollama + AnythingLLM | 资源需求适中,部署相对简单 | 模型性能有限,处理复杂任务力不足 | 个人使用、学习研究、中小团队 |
| 老张API中转服务 | 零门槛部署,顶级模型性能,成本灵活 | 需网络连接,非完全离线方案 | 创业公司、中小企业、普通用户 |
不同用户选型指南
个人用户
- 预算有限,技术水平一般:优先推荐老张API中转服务,无需硬件投入,按用量付费,最经济实惠
- 已有不错配置电脑,有兴趣自己动手:可尝试Ollama + AnythingLLM方案,完全免费
- 极度注重隐私,有强力硬件支持:可考虑AnythingLLM + DeepSeek R1完全离线方案
中小企业
- 追求快速部署,控制前期投入:首选老张API中转服务,立即可用,按需扩展
- 有IT支持团队,关注长期成本:可评估Ollama + AnythingLLM方案,前期投入换取长期无额外费用
- 处理敏感商业数据,要求本地化:适合选择AnythingLLM + DeepSeek R1,确保数据不出企业内网
大型企业/机构
- 需要部门级试点项目验证价值:建议先使用老张API中转服务快速验证效果
- 确定全面部署,对数据安全有严格要求:可投入资源搭建AnythingLLM + DeepSeek R1私有化部署
- 混合策略最佳:核心业务采用私有部署,非核心业务使用API服务,平衡安全与成本
技术发展趋势展望
本地知识库LLM技术仍在快速发展中,未来趋势包括:
- 模型尺寸与性能平衡 – 小型高效模型将成为本地部署主流,如7B参数量级模型性能持续提升
- 多模态能力增强 – 未来本地知识库将更好地理解图像、音频等非文本内容
- 工具使用能力 – 知识库LLM将能调用外部工具和API,实现更复杂的自动化任务
- 降低资源门槛 – 新的优化技术将使普通硬件也能运行更强大的模型
- 混合云架构普及 – 敏感数据本地处理,非敏感任务云端执行的混合架构将成为企业标准
本地知识库LLM代表了AI应用落地的重要方向,将通用大模型能力与专业领域知识结合,创造真正符合特定场景需求的智能工具。无论您选择哪种方案,核心价值都在于将散落的知识转化为随时可用的智能资产,为个人和组织创造实际价值。
我们建议从小规模试点开始,根据实际效果和反馈不断优化,循序渐进地扩大应用范围。随着技术的不断进步和成本的持续降低,本地知识库LLM必将成为个人和企业知识管理的标配工具。
开始构建您的专属知识库
立即尝试老张API中转服务,体验顶级大模型与您专业知识的强大结合。点击注册,即获50元免费体验额度,无需信用卡,5分钟内即可构建您的第一个知识库!