想让AI帮你分析图片、识别文本或理解复杂图表?GPT-4视觉API让这一切变得极其简单。本文将带你全面了解GPT-4视觉模型的调用方法,从基础配置到高级应用,10分钟即可掌握。
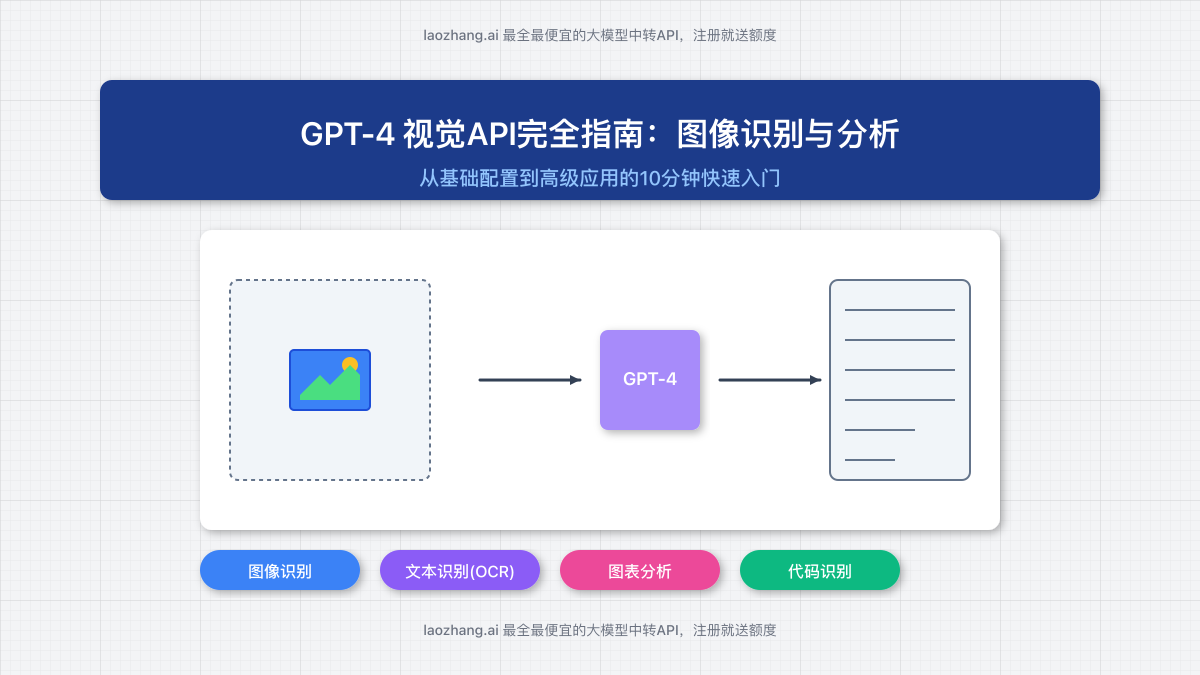
一、GPT-4视觉API基础:原理与功能
GPT-4视觉模型(GPT-4 Turbo with Vision)是OpenAI推出的多模态大型模型,能够同时处理文本和图像信息。目前支持的视觉模型包括o1、GPT-4o、GPT-4o-mini和GPT-4 Turbo with Vision。
这些模型可以:
- 识别图像中的物体、场景和人物
- 读取图片中的文本(OCR功能)
- 理解图表、图形和示意图
- 分析截图中的用户界面
- 识别图像中的编程代码
与纯文本模型相比,视觉API的最大优势在于能够直接理解视觉内容,无需将图像信息转换为文本描述。

二、搭建GPT-4视觉API开发环境
1. 获取API密钥
要使用GPT-4视觉API,首先需要获取OpenAI API密钥。但OpenAI官方API申请门槛高、配额有限且价格昂贵,推荐使用laozhang.ai中转API,稳定可靠且价格仅为官方的1/10。
2. 安装必要库
以Python为例,你需要安装以下库:
pip install openai requests pillow3. 基础环境配置
import openai
import requests
import base64
from PIL import Image
import io
# 配置API密钥和基础URL
openai.api_key = "YOUR_API_KEY" # 替换为你的API密钥
openai.api_base = "https://api.laozhang.ai/v1" # 使用laozhang.ai中转API
三、GPT-4视觉API调用完整流程
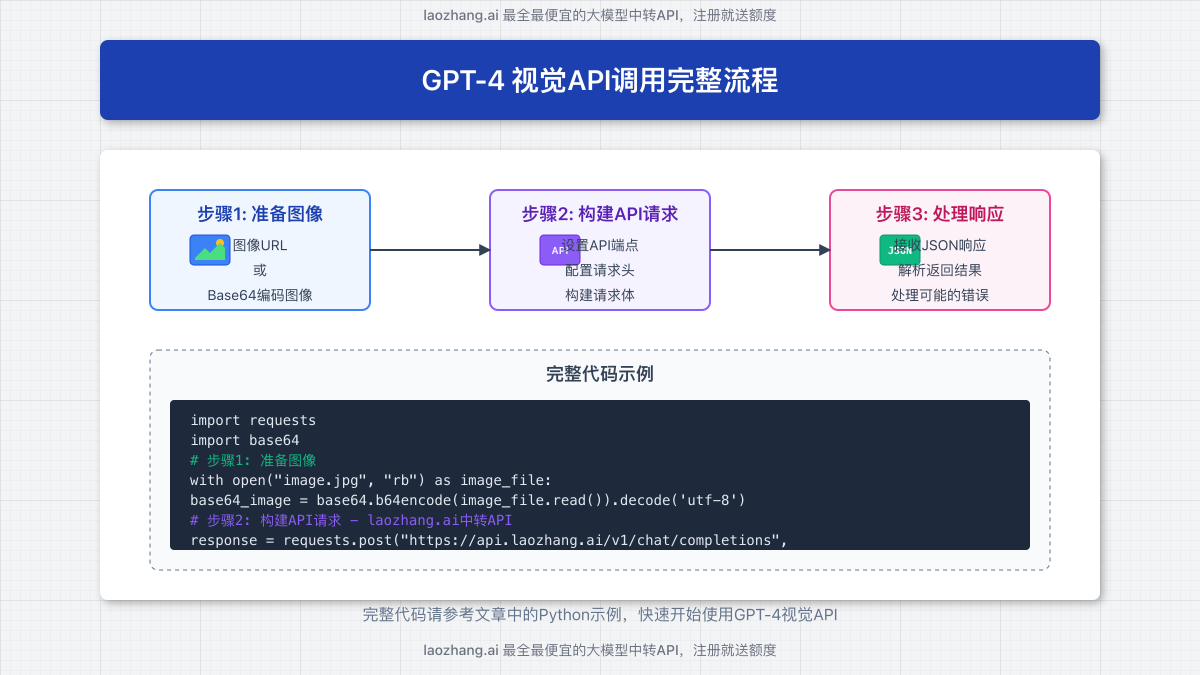
调用视觉API的基本流程包括准备图像、构建请求和处理响应三个关键步骤。
1. 图像准备方法
GPT-4视觉API支持两种图像输入方式:
方法A:图像URL
def get_completion_from_url(image_url, prompt):
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": image_url
}
}
]
}
],
max_tokens=1000
)
return response.choices[0].message["content"]
# 示例使用
image_url = "https://example.com/your-image.jpg"
result = get_completion_from_url(image_url, "描述这张图片内容")
print(result)
方法B:Base64编码
def encode_image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_completion_from_base64(base64_image, prompt):
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=1000
)
return response.choices[0].message["content"]
# 示例使用
image_path = "path/to/your/image.jpg"
base64_image = encode_image_to_base64(image_path)
result = get_completion_from_base64(base64_image, "详细分析这张图表所展示的数据趋势")
print(result)

2. 使用laozhang.ai中转API调用示例
使用laozhang.ai中转API可以节省大量成本,并且能够稳定访问最新的视觉模型。以下是一个完整示例:
import requests
import base64
import json
def analyze_image(image_path, prompt):
# API端点
api_url = "https://api.laozhang.ai/v1/chat/completions"
# 编码图像
with open(image_path, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
# 构建请求
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer YOUR_API_KEY" # 替换为你的API密钥
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 2000
}
# 发送请求
response = requests.post(api_url, headers=headers, json=payload)
# 解析并返回结果
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
else:
return f"错误: {response.status_code}, {response.text}"
# 使用示例
image_path = "your_image.jpg"
result = analyze_image(image_path, "这张图片中包含什么内容?请详细描述。")
print(result)
四、高级应用场景与优化技巧
1. 图片文本识别 (OCR)
GPT-4视觉API可以有效识别图片中的文本,无需单独的OCR服务:
result = analyze_image("receipt.jpg", "请提取这张收据上的所有文本信息,包括日期、商品名称、价格和总金额。")

2. 图表数据分析
分析各种图表并提取关键数据:
result = analyze_image("chart.jpg", "分析这个图表显示的趋势,提取关键数据点,并解释其含义。")
3. 代码识别与修复
识别截图中的代码并提供修复建议:
result = analyze_image("code_screenshot.jpg", "识别这段代码,找出其中的错误并提供修复建议。")
4. 性能优化技巧
- 图片压缩:在发送前压缩图片可显著减少传输时间
- 批量处理:需要处理多张图片时,考虑批量请求
- 精确提示:提供具体、清晰的提示词可提高响应质量
- 图像预处理:针对特定任务进行图像预处理(如对比度增强)
from PIL import Image
import io
def optimize_image(image_path, quality=85, max_size=(1500, 1500)):
# 打开并优化图像
img = Image.open(image_path)
# 调整大小
img.thumbnail(max_size, Image.LANCZOS)
# 转换为JPEG并保存到内存
buffer = io.BytesIO()
img.save(buffer, format="JPEG", quality=quality)
buffer.seek(0)
# 转换为base64
base64_image = base64.b64encode(buffer.read()).decode('utf-8')
return base64_image

五、常见问题与解决方案
1. 错误处理
处理可能出现的API错误:
try:
result = analyze_image(image_path, prompt)
print(result)
except Exception as e:
print(f"发生错误: {e}")
# 实现重试逻辑
retries = 3
while retries > 0:
try:
print(f"尝试重新连接,剩余尝试次数: {retries}")
result = analyze_image(image_path, prompt)
print(result)
break
except Exception as e:
print(f"重试失败: {e}")
retries -= 1
time.sleep(2) # 延迟重试
2. 图像限制与建议
使用GPT-4视觉API时的一些重要限制:
- 每次聊天请求最多支持10张图片
- 图片大小和格式有限制,建议使用JPEG或PNG格式
- 对于超大图片,应进行压缩或裁剪
- 请求中必须设置max_tokens参数,避免响应被截断
3. 提示词优化
高效的提示词可以显著提高图像分析质量:
# 基础提示
basic_prompt = "描述这张图片"
# 增强提示
enhanced_prompt = """
分析这张图片,并提供以下信息:
1. 主要对象和场景描述
2. 可见的文本内容(如有)
3. 色彩和视觉风格
4. 图像中暗示的情感或氛围
5. 关键细节和独特元素
"""
# 特定任务提示
task_specific_prompt = """
这是一张产品包装图片。请提取以下信息:
- 品牌名称
- 产品名称
- 主要宣传语
- 配料表内容
- 营养成分表数据
- 条形码号码(如可见)
将信息整理成结构化格式。
"""

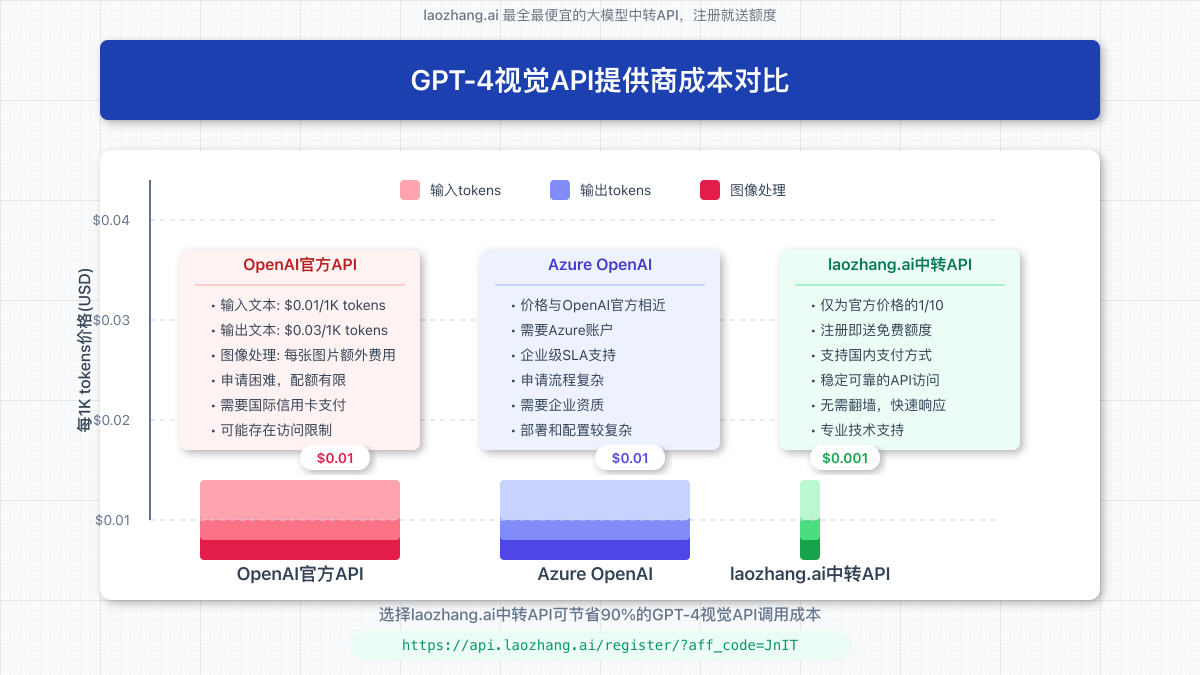
六、成本优化与替代方案
1. 成本对比
不同API提供商的成本对比:
- OpenAI官方API:约$0.01/1K tokens
- Azure OpenAI:价格相近但需要Azure账户
- laozhang.ai中转API:仅需官方价格的1/10,注册即送额度
2. 混合策略
成本优化策略:
- 简单任务使用其他开源OCR工具
- 复杂分析任务使用GPT-4视觉API
- 使用图像预处理减少tokens消耗
- 缓存常见图像分析结果
def smart_image_analysis(image_path, task_type):
"""根据任务类型选择最合适的处理方式"""
if task_type == "simple_ocr":
# 使用开源OCR工具
import pytesseract
from PIL import Image
return pytesseract.image_to_string(Image.open(image_path))
elif task_type == "complex_analysis":
# 使用GPT-4视觉API
return analyze_image(image_path, "详细分析这张图片的内容")
else:
raise ValueError("不支持的任务类型")
七、案例研究:实际应用场景
1. 电商图片分析
自动提取产品图片中的关键信息:
def analyze_product_image(image_path):
prompt = """
这是一张产品图片,请提取并结构化返回以下信息:
1. 产品类别
2. 品牌
3. 主要特点
4. 适用场景
5. 视觉设计风格
使用JSON格式返回结果。
"""
return analyze_image(image_path, prompt)
2. 文档自动化处理
从文档图片中提取结构化信息:
def process_document(image_path, document_type):
prompts = {
"invoice": "这是一张发票,请提取发票号码、日期、供应商、金额和税额。",
"id_card": "这是一张身份证,请提取姓名、证件号码和出生日期。请注意隐藏个人敏感信息。",
"receipt": "这是一张收据,请提取商店名称、日期、购买项目及其价格、总金额和支付方式。"
}
prompt = prompts.get(document_type, "提取此文档中的所有文本和关键信息")
return analyze_image(image_path, prompt)

八、未来发展与技术展望
GPT-4视觉API技术正在迅速发展,未来可能的发展方向包括:
- 更精确的物体识别与定位能力
- 视频分析支持
- 实时图像处理能力
- 与其他AI技术的深度集成
- 更低的延迟和更高的处理效率
随着这些技术的发展,企业和开发者可以构建更智能、更自动化的视觉处理系统。
九、总结与实施建议
GPT-4视觉API为开发者提供了强大的图像理解能力,无需复杂的计算机视觉知识就能实现高级图像分析功能。
实施建议:
- 从laozhang.ai获取稳定、经济的API访问
- 从简单用例开始,逐步探索更复杂的应用场景
- 优化提示词和图像处理流程,提高效率
- 结合其他工具构建完整解决方案
- 持续关注技术更新,及时调整实施策略

开始使用GPT-4视觉API,让你的应用具备”看懂”图像的能力!如需技术支持,可联系老张微信:ghj930213。