欢迎来到这篇全面汇总的ChatGPT教程!本文将详细介绍如何在GitHub上搭建、使用ChatGPT,以及解决常见问题。无论您是新手还是经验丰富的开发者,这篇文章都能为您提供宝贵的指导。
ChatGPT背景介绍
ChatGPT的定义和基本概念
ChatGPT是由OpenAI开发的一款基于GPT-3.5和GPT-4模型的对话生成AI。它能够理解和生成自然语言文本,可用于回答问题、撰写文章、编程帮助等多种任务。ChatGPT采用了大规模语言模型和深度学习技术,通过海量文本数据的训练,具备了强大的自然语言处理能力。
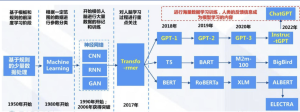
ChatGPT的发展历程
ChatGPT的发展历程如下:
- 2018年:OpenAI发布第一个GPT模型
- 2019年:GPT-2模型发布,性能大幅提升
- 2020年:GPT-3模型问世,参数量达到1750亿
- 2022年11月:ChatGPT正式发布
- 2023年3月:GPT-4模型发布,能力进一步增强
ChatGPT的每一次更新都带来了显著的性能提升,使其成为目前最强大的AI对话系统之一。
GitHub上的ChatGPT教程详细解读
1. 本地搭建ChatGPT环境
在本地搭建ChatGPT环境需要遵循以下步骤:
- 环境准备:
- 安装Python 3.7+和pip
- 确保系统内存至少8GB
- GPU加速(可选):安装CUDA和cuDNN
- 安装依赖:
pip install transformers torch numpy - 下载模型:
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("gpt2") model = AutoModelForCausalLM.from_pretrained("gpt2") - 配置文件:创建config.json文件,设置模型参数
{ "max_length": 50, "num_return_sequences": 1, "temperature": 0.7 } - 运行脚本:创建main.py文件,编写启动代码
import torch from transformers import GPT2LMHeadModel, GPT2Tokenizer model = GPT2LMHeadModel.from_pretrained('gpt2') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') prompt = "Hello, I'm ChatGPT. How can I help you today?" input_ids = tokenizer.encode(prompt, return_tensors='pt') output = model.generate(input_ids, max_length=100, num_return_sequences=1) generated_text = tokenizer.decode(output[0], skip_special_tokens=True) print(generated_text)
2. 在云平台上部署ChatGPT
将ChatGPT部署到云平台可以提高可用性和扩展性。以下是在云平台上部署ChatGPT的步骤:
- 选择云平台:
- AWS: 提供EC2实例和SageMaker服务
- Google Cloud: 提供Compute Engine和AI Platform
- Azure: 提供虚拟机和Azure ML服务
- 配置虚拟机:
- 选择高性能CPU/GPU实例
- 配置至少16GB内存
- 选择Ubuntu 18.04+操作系统
- 部署模型:使用Docker容器化部署
# Dockerfile FROM python:3.8 WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . CMD ["python", "main.py"] - 设置API:使用Flask创建RESTful API
from flask import Flask, request, jsonify app = Flask(name) @app.route('/chat', methods=['POST']) def chat(): input_text = request.json['input'] response = generate_response(input_text) return jsonify({'response': response}) if name == 'main': app.run(host='0.0.0.0', port=5000)
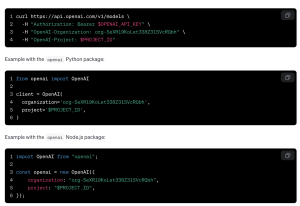
3. 使用ChatGPT API的代码示例
以下是使用Python调用ChatGPT API的示例代码:
import openai
openai.api_key = 'YOUR_API_KEY'
def chat_with_gpt(prompt):
try:
response = openai.Completion.create(
engine="text-davinci-002",
prompt=prompt,
max_tokens=150,
n=1,
stop=None,
temperature=0.7,
)
return response.choices[0].text.strip()
except openai.error.RateLimitError:
return "API rate limit exceeded. Please try again later."
except openai.error.AuthenticationError:
return "Invalid API key. Please check your OpenAI API key."
except Exception as e:
return f"An error occurred: {str(e)}"
使用示例
prompt = "你好,ChatGPT!能简单介绍一下你自己吗?"
response = chat_with_gpt(prompt)
print(response)ChatGPT使用技巧
为了更好地使用ChatGPT,这里有一些实用的技巧:
- 优化提示词:使用清晰、具体的提示词,如”请用简单的语言解释量子计算的基本原理”
- 控制输出长度:通过设置max_tokens参数控制回复长度,如max_tokens=100
- 利用上下文:提供更多背景信息,如”假设我是一个10岁的孩子,请解释…”
- 使用温度参数:调整temperature值(0-1)控制输出的随机性,0更保守,1更创造性
- 分步骤提问:将复杂问题拆分成多个简单问题,逐步引导ChatGPT
- 定期更新模型:使用最新版本的GPT模型,如gpt-3.5-turbo或gpt-4
ChatGPT常见问题及解决方案
1. API调用超时问题
错误信息: “OpenAI API request timed out”
解决方案:
- 增加超时时间:
openai.api_requestor.APIRequestor(timeout=30) - 优化网络连接,使用更稳定的网络
- 减少单次请求的token数量
2. 不相关或不准确的回答
问题描述: ChatGPT提供了与问题无关或不准确的回答
解决方案:
- 提供更详细的上下文信息
- 使用”few-shot learning”技术,给出几个示例
- 调整temperature参数,降低随机性
- 使用最新的模型版本,如gpt-4
3. API调用频率限制
错误信息: “Rate limit reached for requests”
解决方案:
- 实现请求队列和重试机制:
import time import openai def retry_with_exponential_backoff( func, initial_delay: float = 1, exponential_base: float = 2, jitter: bool = True, max_retries: int = 10, errors: tuple = (openai.error.RateLimitError,), ): def wrapper(args, kwargs): num_retries = 0 delay = initial_delay while True: try: return func(args, kwargs) except errors as e: num_retries += 1 if num_retries > max_retries: raise Exception(f"Maximum number of retries ({max_retries}) exceeded.") delay = exponential_base (1 + jitter random.random()) time.sleep(delay) return wrapper @retry_with_exponential_backoff def chat_with_gpt(prompt): return openai.Completion.create(engine="text-davinci-002", prompt=prompt, max_tokens=100) 使用示例 response = chat_with_gpt("Hello, ChatGPT!") - 升级到更高的API使用额度
- 使用多个API密钥轮换调用
4. 模型输出不一致
问题描述: 相同输入得到不同的输出结果
解决方案:
- 设置固定的随机种子:
import random import torch def set_seed(seed): random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed) set_seed(42) # 使用固定的随机种子 - 降低temperature参数值,如设置为0.2
- 使用top_p采样方法替代temperature
5. API密钥安全问题
问题描述: API密钥泄露或被滥用
解决方案:
- 使用环境变量存储API密钥:
import os from dotenv import load_dotenv load_dotenv() openai.api_key = os.getenv("OPENAI_API_KEY") - 实现API密钥轮换机制
- 使用API密钥管理服务,如AWS Secrets Manager
- 定期审查API使用情况,监控异常活动
总结
本文全面介绍了ChatGPT的搭建方法、使用技巧和常见问题解决方案。通过学习这些内容,您应该能够:
- 在本地和云平台上成功搭建ChatGPT环境
- 熟练使用ChatGPT API进行开发
- 优化ChatGPT的输出质量
- 解决使用过程中遇到的各种技术问题
随着人工智能和自然语言处理技术的不断发展,ChatGPT将在更多领域发挥重要作用。希望本文能帮助您更好地利用这一强大工具,提升工作效率和创新能力。如果您想深入学习,建议访问OpenAI的官方GitHub仓库,那里有更多详细的示例和最佳实践。