Claude API在高频使用时会触发速率限制,影响开发效率和用户体验。解决方案包括升级付费计划、实现智能重试机制或使用FastGPTPlus等第三方服务。FastGPTPlus提供不限速API服务,月费158元,支持支付宝微信,5分钟开通。

Claude API不限速的速率限制详解
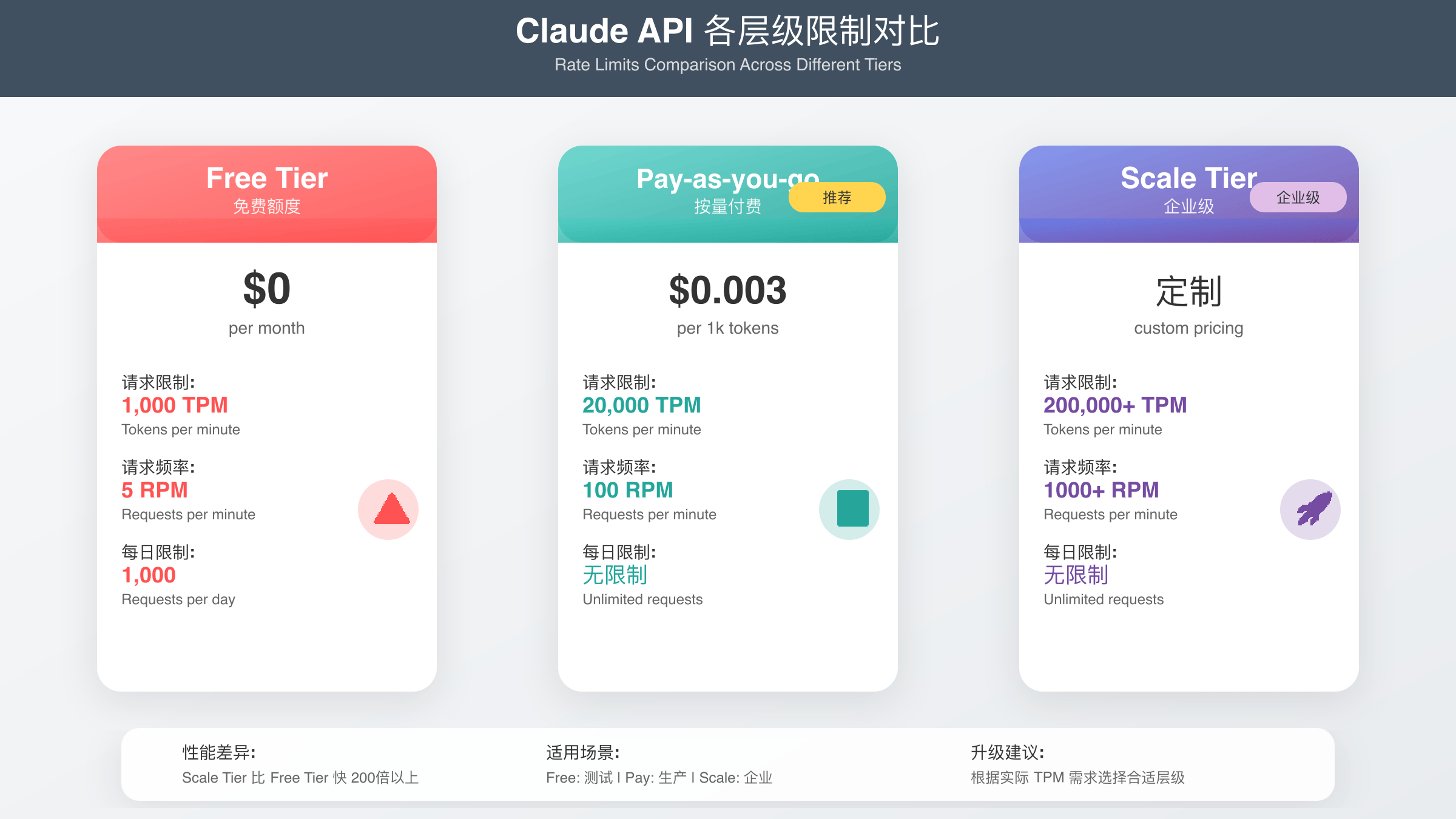
Claude 3.5 API的速率限制是开发者必须面对的核心挑战。根据2025年8月Anthropic官方文档,不同订阅层级的限制差异显著。免费用户每分钟仅能处理1000个tokens,这意味着约500-800个汉字的处理能力,对于任何实际应用都严重不足。付费用户的限制提升至每分钟20000个tokens,大约可处理10000-15000个汉字,但对于批量处理需求仍然受限。企业级Scale计划才能达到每分钟200000+tokens的处理能力,这对大多数开发者来说成本过高。想要获得免费的Claude API密钥,可以参考我们的免费获取Claude API密钥指南。
API速率限制的底层机制基于Token Bucket算法实现。每个API密钥都有独立的令牌桶,以固定速率补充令牌。当请求到达时,系统会从桶中消耗相应数量的令牌。一旦令牌耗尽,后续请求将收到HTTP 429状态码,必须等待令牌补充才能继续。这种机制确保了服务的稳定性,但也成为高频使用场景的瓶颈。理解这个机制对于制定有效的突破策略至关重要。
速率限制对开发项目的实际影响
在实际开发场景中,速率限制的影响远超预期。以内容生成应用为例,每篇文章生成需要消耗3000-5000个tokens,免费账户每分钟仅能完成0.2篇文章的生成。对于需要批量处理的场景,如文档翻译、代码审查或客服机器人,这种限制几乎使应用无法正常运行。开发团队常常需要在用户体验和成本控制之间艰难平衡。
更严重的问题出现在用户量增长时。当应用的并发用户增加,API调用频率线性增长,很快就会触及速率上限。许多开发者发现,他们的应用在测试阶段运行良好,但一旦投入生产环境就频繁遇到429错误。这不仅影响用户体验,还可能导致数据丢失和业务中断。因此,速率限制问题必须在架构设计阶段就予以充分考虑。
Claude API不限速三大主流解决方案对比
市场上主要存在三种解决Claude API速率限制的方案,每种都有其适用场景和成本结构。第一种是升级Anthropic官方订阅计划,从免费层级升级到付费或企业级。这是最直接的解决方案,享受官方技术支持和服务保障,但成本相对较高,特别是对于中小型开发团队。付费计划每月至少需要20美元起步,企业级更是需要定制报价。如需了解详细的Claude API价格对比,可以参考我们的完整指南。
第二种方案是通过技术手段优化API使用效率,包括实现智能重试机制、请求合并、缓存策略等。这种方案的优势是成本较低,完全依靠技术实现,但需要额外的开发工作量和维护成本。开发团队需要实现复杂的队列系统、错误处理和重试逻辑,增加了系统复杂度。
| 解决方案 | 月成本 | 开通时间 | 技术门槛 | 稳定性 |
|---|---|---|---|---|
| 官方升级 | $20-300+ | 需信用卡认证 | 低 | 最高 |
| 技术优化 | 开发成本 | 2-4周开发 | 高 | 中等 |
| FastGPTPlus | ¥158 | 5分钟 | 低 | 高 |
第三种方案是使用FastGPTPlus等专业的API中转服务。这类服务通过技术手段突破了速率限制,为用户提供不限速的API访问。对于中国开发者而言,这种方案特别有吸引力,因为支持人民币支付,无需处理国际信用卡问题,且价格相对合理。FastGPTPlus每月158元的费用,相比官方企业级订阅具有明显的成本优势。想要了解更多Claude API购买攻略,可以查看我们的详细对比分析。
技术实现:智能重试与队列管理
对于选择技术优化路线的开发者,实现智能重试机制是关键步骤。标准的指数退避算法可以有效处理429错误,避免API调用失败。以下是一个完整的Python实现示例,包含了错误处理和日志记录功能。这个实现考虑了不同错误类型的处理策略,确保在遇到速率限制时能够自动重试,而其他类型的错误则直接抛出异常。
import time
import random
import anthropic
from typing import Optional
class ClaudeAPIClient:
def __init__(self, api_key: str, max_retries: int = 5):
self.client = anthropic.Anthropic(api_key=api_key)
self.max_retries = max_retries
def create_message_with_retry(self, messages: list, model: str = "claude-3-5-sonnet-20241022") -> Optional[str]:
"""
带有指数退避的Claude API调用
"""
for attempt in range(self.max_retries):
try:
message = self.client.messages.create(
model=model,
max_tokens=1024,
messages=messages
)
return message.content[0].text
except anthropic.RateLimitError as e:
if attempt == self.max_retries - 1:
raise e
# 指数退避:2^attempt + 随机抖动
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Rate limit hit, waiting {wait_time:.2f}s before retry {attempt + 1}")
time.sleep(wait_time)
except Exception as e:
print(f"Unexpected error: {e}")
raise e
return None
# 使用示例
client = ClaudeAPIClient("your-api-key")
messages = [{"role": "user", "content": "解释量子计算原理"}]
response = client.create_message_with_retry(messages)
队列管理是另一个重要的优化方向。通过实现请求队列系统,可以平滑API调用频率,避免瞬间高并发导致的速率限制。Redis或RabbitMQ等消息队列系统可以有效实现这一功能。队列系统不仅能缓解速率限制,还能提高系统的可扩展性和容错能力。合理设计的队列系统可以在高峰期自动降低请求频率,在低峰期加速处理积压的请求。
Claude API不限速成本效益分析:选择最优方案
不同解决方案的成本结构差异显著,需要根据具体使用场景进行选择。官方付费计划的优势在于官方支持和最高的稳定性保障,但月费20-300美元的成本对中小型项目来说负担较重。特别是对于需要大量API调用的应用,按tokens计费可能导致月度成本快速增长。Claude 3.5 Sonnet的价格为每百万tokens 15美元,对于日处理100万tokens的应用,仅API费用就需要450美元/月。详细的Claude API限制解决方案可以在我们的专门指南中找到。
技术优化方案的直接成本较低,但隐含成本不容忽视。开发团队需要投入2-4周时间实现完整的重试机制、队列系统和监控告警。按照中级开发工程师月薪2万元计算,一次性开发成本约为2-4万元。此外,还需要考虑后续的维护成本和系统复杂度增加带来的风险。当API策略调整或遇到特殊错误时,可能需要额外的开发工作量。
FastGPTPlus等第三方服务的成本优势明显。月费158元的价格相当于官方付费计划的1/5,且无需考虑开发和维护成本。对于中国团队而言,支持人民币支付、5分钟开通的便利性也是重要考量因素。从ROI角度分析,如果团队的API调用量超过每月100万tokens,FastGPTPlus的成本效益明显优于官方方案。类似的订阅优惠服务也可以参考我们的ChatGPT Plus充值指南。
企业级部署的特殊考量
企业级应用在解决速率限制问题时面临更复杂的挑战。除了成本和技术实现,还需要考虑数据安全、合规要求和服务等级协议(SLA)。大型企业通常有严格的供应商审核流程,需要评估API服务提供商的安全认证、数据处理流程和法律合规性。这些要求可能排除某些第三方服务选项,使得官方企业级订阅成为唯一可行的选择。
多地域部署是企业级应用的另一个考量点。Claude API在不同地区的可用性和性能表现存在差异。企业需要确保所选择的解决方案能够支持全球化部署需求。官方服务通常有更好的全球节点覆盖,而第三方服务可能在某些地区存在访问限制或性能问题。制定全球化API访问策略时,需要综合考虑合规、性能和成本等多个维度。
Claude API不限速性能监控与优化策略
无论选择哪种解决方案,建立完善的性能监控体系都是必需的。API调用的成功率、响应时间、错误分布等指标能够帮助团队及时发现和解决问题。推荐使用Prometheus + Grafana搭建监控系统,或者集成到现有的APM平台中。关键监控指标包括:每分钟API调用量、429错误率、平均响应时间、Token使用量等。更多关于免费Claude API方案的详细对比,可以查看我们的专门指南。
缓存策略是提升API使用效率的重要手段。对于相同或类似的输入,可以直接返回缓存结果,避免重复的API调用。Redis是理想的缓存存储解决方案,支持TTL(生存时间)设置和LRU(最近最少使用)淘汰策略。合理的缓存策略可以将API调用量减少30-50%,显著降低速率限制的影响。需要注意的是,缓存策略必须考虑内容的时效性要求,避免返回过时信息。
import redis
import hashlib
import json
class APICache:
def __init__(self, redis_host='localhost', redis_port=6379, default_ttl=3600):
self.redis_client = redis.Redis(host=redis_host, port=redis_port, decode_responses=True)
self.default_ttl = default_ttl
def get_cache_key(self, messages: list, model: str) -> str:
"""生成缓存键"""
cache_data = {"messages": messages, "model": model}
cache_string = json.dumps(cache_data, sort_keys=True)
return f"claude_api:{hashlib.md5(cache_string.encode()).hexdigest()}"
def get(self, messages: list, model: str) -> Optional[str]:
"""获取缓存内容"""
cache_key = self.get_cache_key(messages, model)
return self.redis_client.get(cache_key)
def set(self, messages: list, model: str, response: str, ttl: Optional[int] = None) -> None:
"""设置缓存内容"""
cache_key = self.get_cache_key(messages, model)
ttl = ttl or self.default_ttl
self.redis_client.setex(cache_key, ttl, response)
# 集成到API客户端
class CachedClaudeClient(ClaudeAPIClient):
def __init__(self, api_key: str, cache: APICache, max_retries: int = 5):
super().__init__(api_key, max_retries)
self.cache = cache
def create_message_with_cache(self, messages: list, model: str = "claude-3-5-sonnet-20241022") -> Optional[str]:
# 先检查缓存
cached_response = self.cache.get(messages, model)
if cached_response:
return cached_response
# 调用API
response = self.create_message_with_retry(messages, model)
if response:
# 存入缓存
self.cache.set(messages, model, response)
return response
Claude API不限速常见问题与故障排除
在实施Claude API不限速解决方案过程中,开发者经常遇到各种技术问题。最常见的问题是429错误的处理不当。许多开发者简单地实现了重试机制,但没有考虑到退避时间的合理设置。过短的退避时间会导致持续触发速率限制,而过长的退避时间则影响用户体验。推荐使用指数退避加随机抖动的策略,初始延迟1秒,最大延迟不超过60秒。
另一个常见问题是Token计算不准确导致的意外超限。Claude API的Token计算规则与其他大语言模型有所差异,中文字符通常需要更多Token。开发者应该使用官方提供的Tokenizer进行准确计算,而不是简单地按字符数估算。此外,System Prompt和历史对话也会消耗Token,在长对话场景中需要特别注意Token的累积效应。
网络连接问题也是影响API稳定性的重要因素。Claude API服务器主要部署在海外,国内访问可能遇到网络延迟或连接不稳定的问题。建议配置合理的超时设置(连接超时10秒,读取超时30秒)和重试机制。对于网络环境较差的部署场景,可以考虑使用代理服务器或CDN加速来改善连接质量。
未来趋势与技术展望
Claude API的发展趋势显示,Anthropic正在不断优化速率限制策略,以平衡服务质量和用户需求。根据2025年第二季度的更新,新引入的动态速率调整机制能够根据用户的历史使用模式自动调整限制阈值。长期稳定使用的用户可能获得更高的速率配额,而新用户则需要通过渐进式使用来提升限制。这种策略鼓励了负责任的API使用。
技术架构方面,边缘计算和CDN技术的应用将进一步优化API访问性能。预计到2025年底,Claude API将支持更多地域节点,降低访问延迟。同时,批量处理API的推出将为高并发场景提供更经济的解决方案。开发者可以将多个请求打包发送,享受批量折扣价格,同时减少网络开销。
对于中国市场,本土化API服务的需求日益增长。FastGPTPlus等服务商正在建设国内节点,提供更低延迟的访问体验。预计未来会有更多专门面向中国开发者的API服务平台出现,提供人民币计费、本土化支付和中文客服支持。这些服务将在保持技术先进性的同时,更好地满足本土化需求。

Claude API不限速实际部署建议与最佳实践
在实际项目部署中,建议采用分层的解决策略来应对不同场景的需求。对于原型开发和小规模测试,可以直接使用免费层级,配合简单的重试机制。当项目进入MVP阶段需要稳定的API访问时,FastGPTPlus等第三方服务是理想的过渡方案,能够快速解决速率限制问题,且成本可控。如需要其他AI工具的订阅服务,可以查看我们的香港代付服务指南。
随着业务规模扩大和对稳定性要求提升,企业应该考虑升级到官方付费计划,并建设完整的API管理平台。这个平台应该包括请求路由、负载均衡、缓存管理、监控告警等功能。通过多API密钥轮换使用,可以进一步提升处理能力。同时建立API成本监控体系,及时发现异常使用模式,避免成本失控。
安全性方面,API密钥的管理至关重要。建议使用环境变量或密钥管理服务存储敏感信息,避免硬编码到源代码中。对于生产环境,应该实现API调用的审计日志,记录请求内容、响应结果和用户信息。这不仅有助于问题排查,也满足了企业合规要求。定期轮换API密钥和访问权限审核也是必要的安全措施。