



ChatGPT Plus o3 API Access: Complete Developer Guide 2025
Last Updated: April 19, 2025 – OpenAI’s o3 model represents a significant advancement in AI reasoning capabilities, now accessible via API to qualifying developers. This comprehensive guide explains how to access, implement, and optimize your applications with the powerful o3 model in 2025.
Understanding OpenAI’s o3 Model: The Advanced Reasoning Powerhouse
OpenAI’s o3 model stands as their most advanced reasoning-focused large language model, offering exceptional capabilities across coding, math, science, visual perception, and complex problem-solving. Released as part of OpenAI’s strategic focus on specialized models, o3 brings unprecedented reasoning abilities to both ChatGPT Plus users and API developers.
Unlike its predecessors, o3 features:
- Enhanced multi-step reasoning abilities for complex problem solving
- Superior code generation and debugging capabilities
- Refined tool use and function calling
- Improved mathematical accuracy and scientific analysis
- Structured thinking that mirrors expert human reasoning
However, accessing o3 through the API has distinct requirements, quotas, and implementation approaches that developers must understand to leverage its full potential.
API Access Requirements: Getting Started with o3
Unlike general models like GPT-4o, access to o3 through the API requires specific qualifications and proper setup:
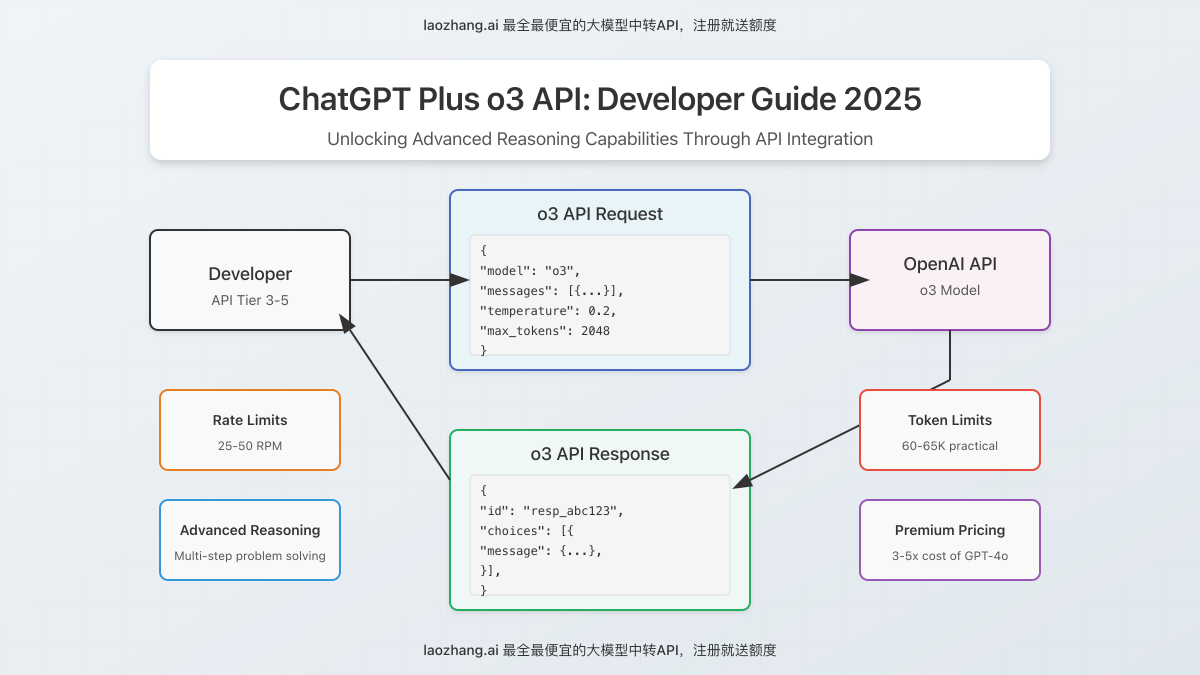
Account Tier Requirements
Access to o3 via API is restricted to accounts with:
- API Usage Tier: Level 3-5 accounts (higher volume customers)
- Subscription Status: Active payment method with good standing
- Usage History: Established pattern of responsible API usage
For developers who don’t currently qualify for direct o3 API access, alternative solutions like laozhang.ai provide mediated access through their API proxy services, with free credits upon registration.

Important o3 API Limitations to Consider
Before implementing o3 in your applications, developers should understand several critical limitations:
1. Rate Limit Considerations
API access to o3 comes with stricter rate limits compared to other models:
- Requests Per Minute (RPM): 25-50 RPM depending on account tier
- Tokens Per Minute (TPM): 60,000-150,000 TPM depending on account tier
- Concurrent Requests: 5-15 depending on account tier
These limits are significantly lower than those for GPT-4o or GPT-3.5 Turbo, reflecting the computational intensity of the model.
2. Token Limitations
A critical consideration for developers is o3’s token handling:
- Context Window: Theoretical limit up to 200K tokens
- Practical Input Limit: 60-65K tokens per message (recently reduced from ~100K)
- Maximum Output: 4,096 tokens by default
The recent reduction in practical token limits (as reported by Pro users) creates challenges for applications handling large documents or complex datasets. Developers report that the actual usable context is smaller than the theoretical maximum, requiring careful prompt engineering.
3. Cost Considerations
o3 represents OpenAI’s premium tier for reasoning tasks, with corresponding pricing:
- Input Tokens: $0.015 per 1K tokens
- Output Tokens: $0.06 per 1K tokens
- Average Request Cost: 3-5x the cost of GPT-4o for equivalent tasks
Implementing o3 Through the API: Code Examples
Accessing o3 requires proper implementation through OpenAI’s API endpoints. Here are the essential code patterns for different languages:
Python Implementation
import openai
client = openai.OpenAI(api_key="YOUR_API_KEY")
response = client.chat.completions.create(
model="o3", # Specify the o3 model
messages=[
{"role": "system", "content": "You are an AI specialized in scientific reasoning."},
{"role": "user", "content": "Analyze the following experiment results and suggest possible explanations..."}
],
temperature=0.2, # Lower temperature for more focused reasoning
max_tokens=2048,
response_format={"type": "json_object"} # Optional structured output
)
print(response.choices[0].message.content)Node.js Implementation
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
async function generateResponse() {
const response = await openai.chat.completions.create({
model: 'o3',
messages: [
{ role: 'system', content: 'You are an AI specialized in multistep reasoning.' },
{ role: 'user', content: 'Develop a strategy for solving this complex problem...' }
],
temperature: 0.2,
max_tokens: 2048,
top_p: 0.95
});
return response.choices[0].message.content;
}Alternative Implementation Through laozhang.ai
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "o3",
"messages": [
{"role": "system", "content": "You are a reasoning specialist."},
{"role": "user", "content": "Analyze this complex scenario..."}
],
"temperature": 0.2,
"max_tokens": 2048
}'The key difference when using o3 versus other models is the need for carefully structured prompts that leverage its reasoning capabilities, along with proper error handling for the more restrictive rate limits.
Optimizing o3 API Implementation: Best Practices
To maximize the value of o3 while managing its constraints, consider these implementation strategies:
1. Strategic Model Selection
Not every request requires o3’s advanced reasoning:
- Use o3 for: Complex reasoning, multi-step problem solving, scientific analysis, advanced code generation
- Use o4-mini for: Standard content generation, classification, summarization, everyday tasks
- Use GPT-4o for: General-purpose requests with visual components
Implementing intelligent model routing in your application can significantly reduce costs while maintaining performance.
2. Token Optimization Techniques
Given the reduced practical token limits, optimize your usage:
- Implement chunking strategies for large documents, processing sequentially with summarized context
- Use embeddings to store and retrieve context instead of sending full history
- Structure prompts efficiently to reduce token usage while maintaining reasoning quality
- Compress relevant information by removing redundant content before sending
3. Rate Limit Management
Handle o3’s stricter rate limits with proper engineering:
- Implement exponential backoff for rate limit errors (429 responses)
- Create request queuing systems to manage high-volume applications
- Monitor usage patterns to distribute requests evenly throughout the day
- Consider batch processing for non-time-sensitive operations
Example rate limit handling in Python:
import time
import random
def make_o3_request(prompt, max_retries=5):
retries = 0
while retries < max_retries:
try:
response = client.chat.completions.create(
model="o3",
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
return response
except openai.RateLimitError:
# Exponential backoff with jitter
sleep_time = (2 ** retries) + random.random()
print(f"Rate limit exceeded. Retrying in {sleep_time:.2f} seconds...")
time.sleep(sleep_time)
retries += 1
raise Exception("Max retries exceeded")Real-world Applications: Where o3 API Excels
The o3 model’s advanced reasoning capabilities make it particularly valuable for specific use cases:
1. Scientific Research Analysis
o3’s ability to follow complex chains of reasoning makes it ideal for analyzing scientific papers, experiment results, and research methodologies. Applications can help researchers identify patterns, suggest hypotheses, or find inconsistencies in data.
2. Advanced Code Generation and Analysis
For software development, o3 excels at:
- Generating optimized algorithms for complex problems
- Debugging sophisticated code with deep understanding
- Suggesting architectural improvements based on system analysis
- Translating complex requirements into functional code
3. Financial and Legal Analysis
The structured reasoning of o3 makes it valuable for:
- Analyzing complex financial documents and identifying risk factors
- Reviewing legal agreements for potential issues or conflicts
- Modeling financial scenarios with multiple variables
- Evaluating compliance with regulatory frameworks
4. Education and Training Systems
o3’s ability to break down complex concepts makes it excellent for:
- Creating personalized learning paths with step-by-step explanations
- Generating detailed feedback on student work with reasoning
- Developing complex problem sets with worked solutions
- Simulating expert tutoring in specialized subjects
Troubleshooting Common o3 API Issues
Developers commonly encounter several issues when working with the o3 API:
1. Token Limitation Errors
When encountering “This model’s maximum context length is X tokens” errors despite being within theoretical limits:
- Verify your token count with a reliable tokenizer
- Remember that the practical limit (60-65K) is lower than the theoretical maximum
- Break requests into smaller chunks with summarized context
- Consider using the Chat Completions API with multiple messages instead of a single large message
2. Rate Limit Handling
For “Rate limit exceeded” errors:
- Implement proper exponential backoff with jitter
- Monitor and distribute requests throughout the day
- Consider using batch endpoints for bulk processing
- For high-volume needs, explore alternative APIs like laozhang.ai that offer different rate limit structures
3. Quality and Performance Optimization
To address inconsistent reasoning or performance:
- Structure prompts to explicitly request step-by-step reasoning
- Use lower temperature settings (0.1-0.3) for more focused responses
- Provide clear instructions and examples in system messages
- Consider implementing Chain-of-Thought prompting techniques
Future of o3 API: What to Expect
As OpenAI continues to develop its reasoning-focused models, developers can anticipate several evolutionary paths for the o3 API:
Expected Developments
- Expanded Access: Gradually wider availability to more API tiers
- Token Limit Adjustments: Potential restoration of higher token limits based on user feedback
- Specialized Variants: Introduction of domain-specific o3 models (similar to the o4-mini-high for coding)
- Improved Tooling: Enhanced SDKs and tools specifically designed for o3’s reasoning capabilities
- Integration Features: Deeper integration with other OpenAI products and services
Developers should stay informed through OpenAI’s announcements and community discussions to adapt their implementations as the API evolves.
Conclusion: Leveraging o3’s Power Through API
The o3 API represents a significant advancement in making sophisticated reasoning capabilities available to developers. While it comes with important limitations around token handling, rate limits, and access requirements, these constraints reflect the computational intensity of this advanced model.
By implementing the best practices outlined in this guide—strategic model selection, token optimization, and proper rate limit handling—developers can effectively harness o3’s capabilities for applications requiring deep reasoning, complex problem-solving, and expert-level analysis.
For those facing access limitations, alternative API providers like laozhang.ai offer pathways to these advanced capabilities with different pricing and access structures.
As the reasoning capabilities of AI models continue to advance, mastering the implementation patterns for models like o3 will become increasingly valuable for developers looking to create truly intelligent applications.
Frequently Asked Questions
Can I access o3 through the API with a standard OpenAI account?
No, o3 API access is currently restricted to accounts with API usage tiers 3-5. Standard accounts do not have access to o3 through direct API calls. Alternatives include using ChatGPT Plus for manual interactions or utilizing third-party API providers like laozhang.ai.
Why has the token limit for o3 been reduced to 60-65K in practice?
While OpenAI hasn’t officially commented on the reduced practical token limit, it likely relates to optimizing computational resources and system stability. The theoretical limit remains higher, but users report consistent failures when exceeding approximately 60-65K tokens per message.
How does o3 compare to o4-mini for API implementation?
o3 offers superior reasoning capabilities but with stricter rate limits and higher costs. o4-mini provides a more balanced approach with higher rate limits, lower costs, and good (though less advanced) reasoning abilities. The choice depends on your specific use case requirements and budget constraints.
Can I fine-tune the o3 model for my specific needs?
Currently, OpenAI does not offer fine-tuning capabilities for o3. The model is designed to follow instructions precisely through prompt engineering rather than custom fine-tuning. This approach preserves the model’s general reasoning capabilities while allowing specialization through careful prompting.
What are the alternatives if I exceed o3’s rate limits?
If you’re consistently exceeding o3’s rate limits, consider: 1) Implementing request queuing and batch processing, 2) Strategically distributing requests across time periods, 3) Using multiple API keys if permitted by your agreement, or 4) Utilizing third-party API providers with different rate limit structures.







