GPT-4.1 API Pricing Guide 2025: Complete Cost Breakdown & Money-Saving Tips
OpenAI released its cutting-edge GPT-4.1 family of models on April 14, 2025, featuring significant improvements in coding capabilities, instruction following, and context handling. With three different models in the lineup – GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano – developers now have more options to balance performance and cost. This comprehensive guide breaks down everything you need to know about GPT-4.1 API pricing, with practical examples and expert strategies to maximize your budget.

GPT-4.1 API Models and Pricing Structure
The GPT-4.1 family includes three distinct models with different capabilities and pricing tiers:
1. GPT-4.1 (Full Model)
- Input tokens: $2.00 per million tokens
- Output tokens: $8.00 per million tokens
- Context window: 1 million tokens
- Max output: 32,768 tokens per request
- Use case: Complex coding, multi-step reasoning, and advanced instruction following
2. GPT-4.1 Mini
- Input tokens: $0.40 per million tokens
- Output tokens: $1.60 per million tokens
- Context window: 1 million tokens
- Max output: 32,768 tokens per request
- Use case: Balance between performance and cost for moderate complexity tasks
3. GPT-4.1 Nano
- Input tokens: $0.10 per million tokens
- Output tokens: $0.40 per million tokens
- Context window: 1 million tokens
- Max output: 32,768 tokens per request
- Use case: Fastest and most cost-effective for simple tasks requiring low latency

Understanding Token Costs: Real-World Examples
To help you better understand the practical implications of these pricing models, let’s examine some real-world scenarios:
Example 1: Chatbot Application (100,000 daily conversations)
- Average input: 200 tokens per conversation
- Average output: 150 tokens per conversation
- Daily volume: 100,000 conversations
Daily costs per model:
- GPT-4.1: $40 (input) + $120 (output) = $160/day
- GPT-4.1 Mini: $8 (input) + $24 (output) = $32/day
- GPT-4.1 Nano: $2 (input) + $6 (output) = $8/day
Example 2: Code Generation Service (10,000 daily requests)
- Average input: 1,000 tokens per request
- Average output: 2,000 tokens per request
- Daily volume: 10,000 requests
Daily costs per model:
- GPT-4.1: $20 (input) + $160 (output) = $180/day
- GPT-4.1 Mini: $4 (input) + $32 (output) = $36/day
- GPT-4.1 Nano: $1 (input) + $8 (output) = $9/day
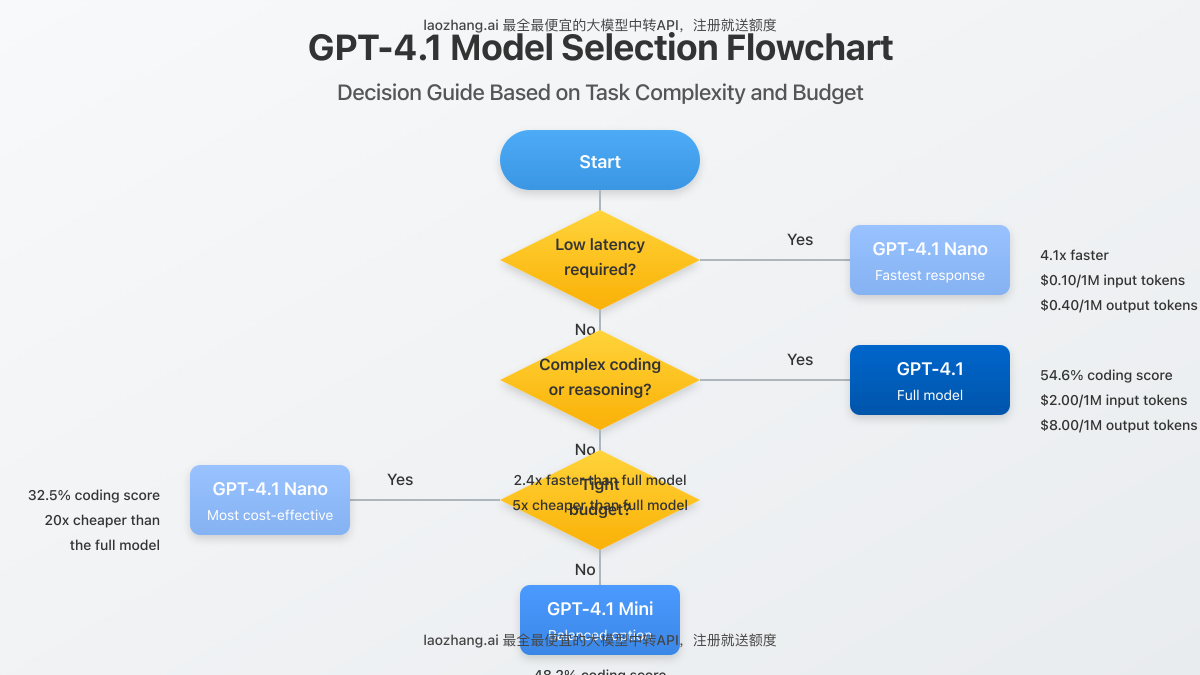
Performance Benchmarks: What You Get for Your Money
Understanding the performance differences between these models is essential for making cost-effective decisions:
Coding Performance (SWE-Bench Verified)
- GPT-4.1: 54.6%
- GPT-4.1 Mini: 48.2%
- GPT-4.1 Nano: 32.5%
- Comparison points: Claude 3.7 Sonnet (62.3%), Gemini 2.5 Pro (63.8%)
Instruction Following (MultiChallenge)
- GPT-4.1: 10.5% improvement over GPT-4o
- GPT-4.1 Mini: 7.3% improvement over GPT-4o mini
- GPT-4.1 Nano: Comparable to GPT-4o mini
Response Generation Speed
- GPT-4.1: Standard
- GPT-4.1 Mini: 2.4x faster than GPT-4.1
- GPT-4.1 Nano: 4.1x faster than GPT-4.1 (OpenAI’s fastest model)
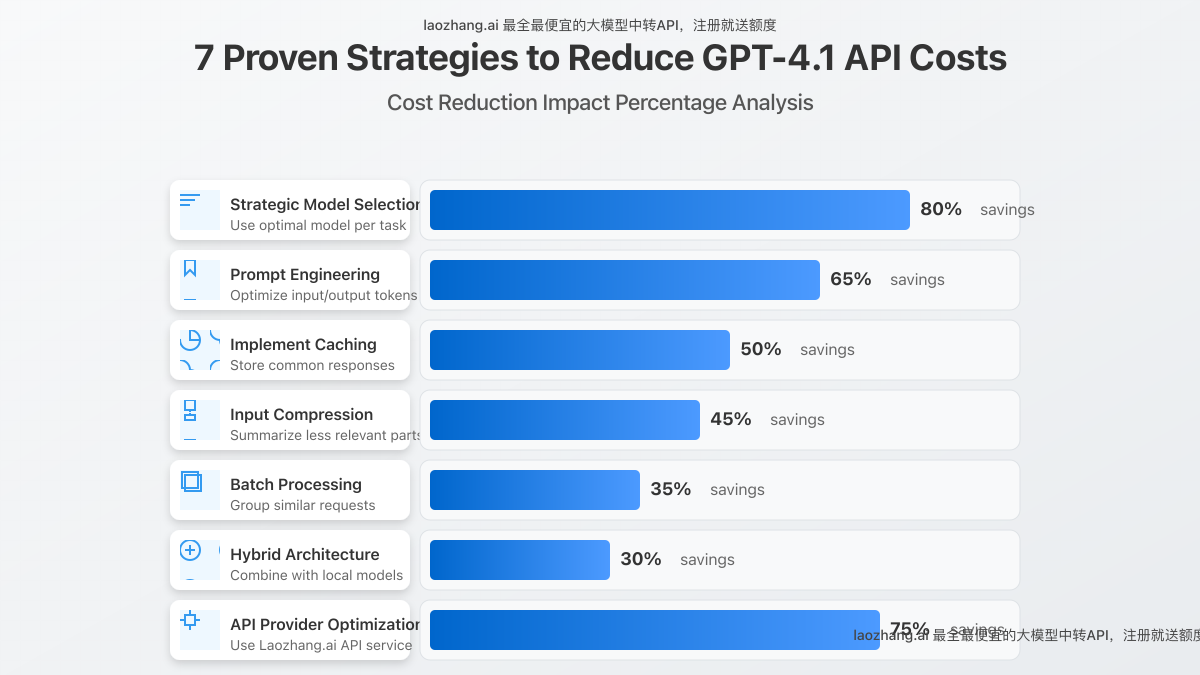
7 Proven Strategies to Reduce GPT-4.1 API Costs
Implementing these optimization strategies can help you significantly reduce your API expenses:
1. Strategic Model Selection
Choose the appropriate model for different parts of your application workflow. For example, use GPT-4.1 Nano for initial user intent classification, then switch to GPT-4.1 or GPT-4.1 Mini only when needed for complex processing.
2. Prompt Engineering Optimization
Refine your prompts to be concise yet specific. Every unnecessary token in your input costs money. For recurring tasks, invest time in prompt engineering to reduce token usage while maintaining quality.
3. Implement Cached Responses
For common queries or scenarios, implement a caching layer that stores previous responses. This can reduce API calls by 30-50% for many applications.
4. Use Input Compression Techniques
For long-context applications, implement techniques to compress input data by summarizing less relevant portions while preserving key information.
5. Batch Processing
Where possible, batch similar requests together rather than making individual API calls. This reduces overhead and allows for better resource utilization.
6. Hybrid Architecture
Combine GPT-4.1 models with lightweight open-source models that run locally for preliminary processing, only sending refined prompts to the OpenAI API.
7. Use a Cost-Effective API Provider
Consider using third-party API providers that offer reduced rates for OpenAI models through bulk purchasing and optimization.
Introducing Laozhang.ai: The Most Cost-Effective GPT-4.1 API Provider
If you’re looking to significantly reduce your GPT-4.1 API costs while maintaining full access to all model capabilities, Laozhang.ai offers the most comprehensive and affordable API intermediary service:
- Discounted rates: Save up to 75% on standard OpenAI pricing
- Full model access: Complete support for all GPT-4.1 family models
- Free signup bonus: Get free tokens upon registration
- Simple integration: Drop-in replacement for OpenAI API with identical endpoints
- Reliable performance: Enterprise-grade infrastructure with 99.9% uptime
Sample API Request with Laozhang.ai
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4.1",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain GPT-4.1 pricing in simple terms."}
]
}'To get started with discounted GPT-4.1 API access, register here and receive free tokens immediately. For enterprise solutions or custom pricing, contact directly via WeChat: ghj930213.

GPT-4.1 API Pricing FAQ
Does GPT-4.1 offer volume discounts?
OpenAI does not currently offer official volume discounts for GPT-4.1 models. However, enterprise customers can contact OpenAI directly for custom pricing options based on volume commitments.
How does GPT-4.1 pricing compare to previous models?
GPT-4.1 is priced similarly to GPT-4o at the higher end, but offers better performance for coding tasks and instruction following. The Mini and Nano variants provide significantly more cost-effective options compared to previous model generations.
Can I switch between GPT-4.1 models in the same application?
Yes, you can dynamically select which GPT-4.1 model to use for each API call based on the complexity of the task. This allows for optimizing both cost and performance within a single application.
Is there a free tier for GPT-4.1 API access?
OpenAI does not offer a free tier specifically for GPT-4.1 models. New developers can access $5 in free credits upon signing up, which can be used with any model including GPT-4.1.
How accurate is the 1 million token context window?
While GPT-4.1 models can technically process up to 1 million tokens, OpenAI notes that reliability decreases with extremely large inputs. For optimal performance, OpenAI recommends keeping inputs under 300,000 tokens when high accuracy is critical.
Conclusion: Making the Most of GPT-4.1 API in 2025
GPT-4.1 represents a significant advancement in AI capabilities, particularly for coding and complex instruction following. With the introduction of Mini and Nano variants, developers now have more flexibility to balance performance and cost based on their specific needs.
By implementing the cost optimization strategies outlined in this guide and considering alternative API providers like Laozhang.ai, you can effectively reduce your GPT-4.1 API expenses while still leveraging state-of-the-art AI capabilities for your applications.
For developers focused on coding applications, GPT-4.1’s improvements in this area make it particularly valuable despite the higher cost compared to previous generations. As with any API integration, monitoring usage patterns and continuously refining your implementation will be key to maximizing ROI.