



2025年4月14日,OpenAI发布了全新的GPT-4.1系列模型,包括旗舰版GPT-4.1、经济型GPT-4.1 Mini以及轻量版GPT-4.1 Nano。这些新模型在编码能力、指令遵循和上下文处理方面都有显著提升,同时提供了更具成本效益的选择。本文将深入分析GPT-4.1的价格结构,并提供实用策略帮助您最大限度地降低API使用成本。

一、GPT-4.1系列模型价格结构
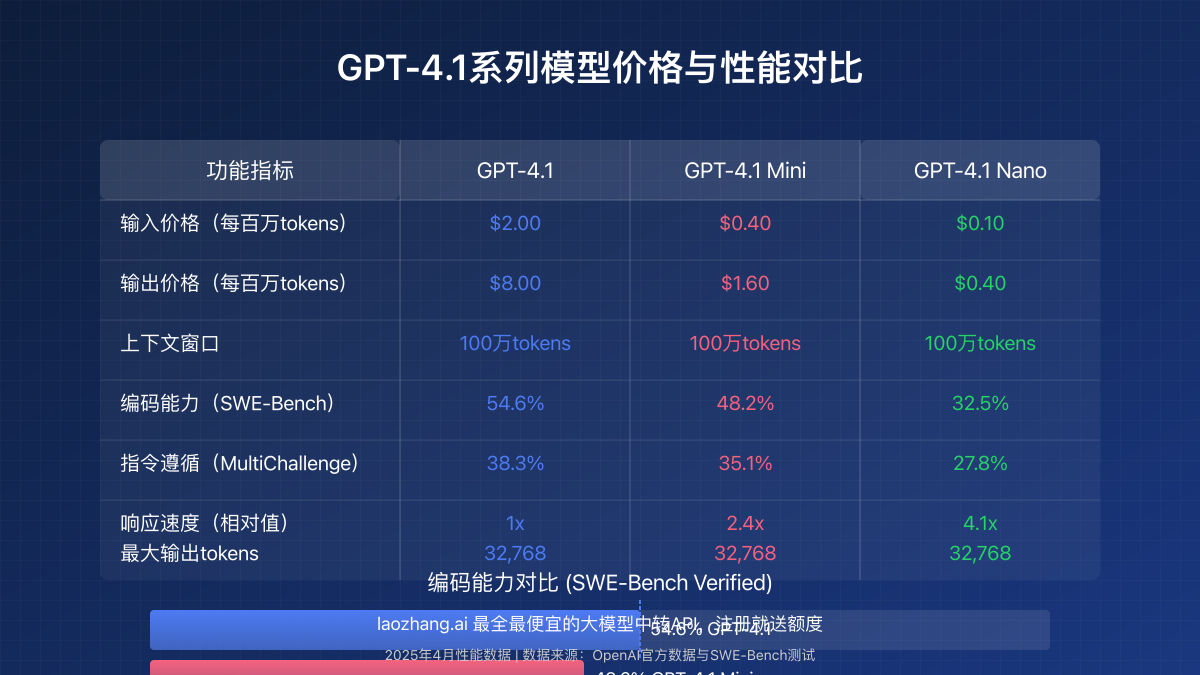
GPT-4.1系列包含三个不同定位的模型,每个模型都有不同的价格和性能特点:
1. GPT-4.1(旗舰版)
- 输入tokens:$2.00/百万tokens
- 输出tokens:$8.00/百万tokens
- 上下文窗口:100万tokens
- 最大输出:每次请求32,768 tokens
- 适用场景:复杂编码、多步骤推理和高级指令遵循
2. GPT-4.1 Mini
- 输入tokens:$0.40/百万tokens
- 输出tokens:$1.60/百万tokens
- 上下文窗口:100万tokens
- 最大输出:每次请求32,768 tokens
- 适用场景:中等复杂度任务,在性能和成本之间取得平衡
3. GPT-4.1 Nano
- 输入tokens:$0.10/百万tokens
- 输出tokens:$0.40/百万tokens
- 上下文窗口:100万tokens
- 最大输出:每次请求32,768 tokens
- 适用场景:最快速、最具成本效益的简单任务处理
二、理解Token成本:实际应用案例
为了帮助您更好地理解这些价格模型的实际影响,我们来看几个真实场景:
案例1:聊天机器人应用(日均10万对话)
- 平均输入:每次对话200 tokens
- 平均输出:每次对话150 tokens
- 日均量:10万次对话
各模型每日成本:
- GPT-4.1:$40(输入)+ $120(输出)= $160/天
- GPT-4.1 Mini:$8(输入)+ $24(输出)= $32/天
- GPT-4.1 Nano:$2(输入)+ $6(输出)= $8/天
案例2:代码生成服务(日均1万请求)
- 平均输入:每次请求1,000 tokens
- 平均输出:每次请求2,000 tokens
- 日均量:10,000次请求
各模型每日成本:
- GPT-4.1:$20(输入)+ $160(输出)= $180/天
- GPT-4.1 Mini:$4(输入)+ $32(输出)= $36/天
- GPT-4.1 Nano:$1(输入)+ $8(输出)= $9/天
三、性能基准:您的投资回报
了解这些模型之间的性能差异对于做出成本效益决策至关重要:
1. 编码性能(SWE-Bench Verified)
- GPT-4.1:54.6%
- GPT-4.1 Mini:48.2%
- GPT-4.1 Nano:32.5%
- 对比参考:Claude 3.7 Sonnet(62.3%),Gemini 2.5 Pro(63.8%)
2. 指令遵循能力(MultiChallenge)
- GPT-4.1:比GPT-4o提高10.5%
- GPT-4.1 Mini:比GPT-4o mini提高7.3%
- GPT-4.1 Nano:与GPT-4o mini相当
3. 响应生成速度
- GPT-4.1:标准速度
- GPT-4.1 Mini:比GPT-4.1快2.4倍
- GPT-4.1 Nano:比GPT-4.1快4.1倍(OpenAI最快的模型)
四、GPT-4.1与其他热门模型价格对比
| 模型 | 输入价格($/百万tokens) | 输出价格($/百万tokens) | 上下文窗口 | 编码能力(SWE-Bench) |
|---|---|---|---|---|
| GPT-4.1 | $2.00 | $8.00 | 100万tokens | 54.6% |
| GPT-4o | $2.50 | $10.00 | 128K tokens | 33.2% |
| GPT-4.5 Preview | $75.00 | $150.00 | 128K tokens | 28.0% |
| o1 | $15.00 | $60.00 | 200K tokens | 41.0% |
| o3-mini | $1.10 | $4.40 | 200K tokens | 27.8% |
| Claude 3.7 Sonnet | $3.00 | $15.00 | 200K tokens | 62.3% |
注意:OpenAI已宣布将在2025年7月14日停用GPT-4.5 Preview,因为GPT-4.1在许多关键功能上提供了更好或相似的性能,且成本和延迟更低。
五、7大实用策略降低GPT-4.1 API成本
实施以下优化策略可以帮助您显著降低API费用:

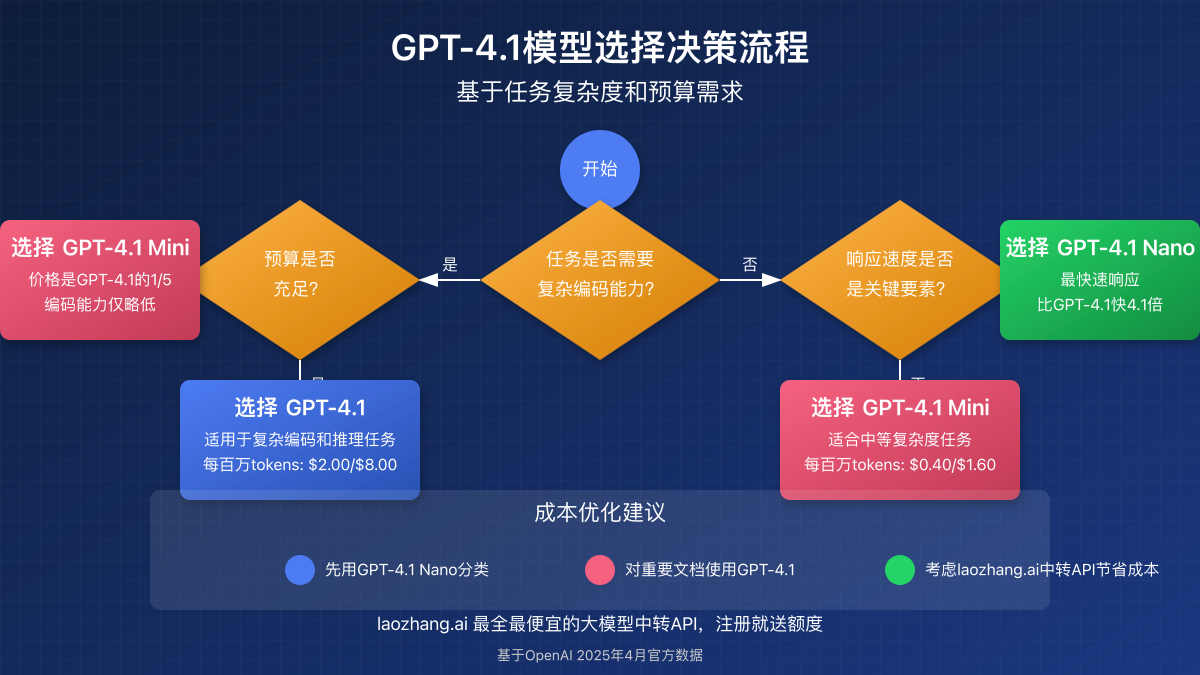
1. 战略性模型选择
为应用工作流的不同部分选择适当的模型。例如,使用GPT-4.1 Nano进行初始用户意图分类,然后仅在需要复杂处理时切换到GPT-4.1或GPT-4.1 Mini。
2. 提示工程优化
精炼您的提示,使其简洁但具体。输入中的每个不必要的token都会花费金钱。对于重复性任务,投入时间进行提示工程,以减少token使用量同时保持质量。
3. 实现响应缓存
对于常见查询或场景,实施缓存层存储先前的响应。这可以减少30-50%的API调用,特别适用于常见问题回答或相似请求处理。
4. 使用输入压缩技术
对于长上下文应用,实现技术来压缩输入数据,通过总结不太相关的部分同时保留关键信息,有效减少token消耗。
5. 批量处理
尽可能将类似请求批量处理,而不是进行单独的API调用。这减少了开销并允许更好的资源利用。
6. 混合架构
将GPT-4.1模型与本地运行的轻量级开源模型结合使用进行初步处理,只将精炼的提示发送到OpenAI API。
7. 使用成本效益更高的API提供商
考虑使用通过批量购买和优化提供OpenAI模型折扣价格的第三方API提供商,如laozhang.ai。
六、中转API服务:降低成本的另一种选择
如果你希望显著降低GPT-4.1 API成本同时保持所有模型功能的完整访问,中转API服务可能是一个值得考虑的选择。下面我们详细介绍laozhang.ai中转API的优势:

laozhang.ai:最具成本效益的GPT-4.1 API提供商
- 折扣价格:比标准OpenAI价格节省高达75%
- 完整模型访问:完全支持所有GPT-4.1系列模型
- 注册奖励:注册即送免费token
- 简单集成:与OpenAI API完全兼容的端点
- 可靠性能:企业级基础设施,99.9%的正常运行时间
laozhang.ai API请求示例
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4.1",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "用简单的语言解释GPT-4.1价格。"}
]
}'要开始使用折扣GPT-4.1 API访问,点击这里注册并立即获得免费token。对于企业解决方案或自定义定价,请通过微信直接联系:ghj930213。
七、GPT-4.1 API价格常见问题
GPT-4.1是否提供批量折扣?
OpenAI目前不为GPT-4.1模型提供官方批量折扣。但是,企业客户可以直接联系OpenAI,根据批量承诺获取自定义定价选项。或者,通过laozhang.ai等中转服务获取更具成本效益的定价。
GPT-4.1价格与之前模型相比如何?
GPT-4.1的价格与GPT-4o在高端相似,但在编码任务和指令遵循方面提供了更好的性能。Mini和Nano变体提供了比之前模型世代更具成本效益的选择,适合不同场景需求。
我可以在同一应用中切换GPT-4.1模型吗?
是的,您可以根据任务的复杂性为每个API调用动态选择使用哪个GPT-4.1模型。这允许在单个应用程序中同时优化成本和性能。
GPT-4.1 API有免费层吗?
OpenAI不专门为GPT-4.1模型提供免费层。新开发者在注册时可以获得$5的免费积分,可用于任何模型,包括GPT-4.1。通过中转服务如laozhang.ai注册可以获得额外的免费额度。
100万token的上下文窗口有多准确?
虽然GPT-4.1模型技术上可以处理高达100万tokens,但OpenAI指出,输入非常大时可靠性会降低。为了获得最佳性能,OpenAI建议在需要高精度时将输入保持在30万tokens以下。
八、结论:2025年充分利用GPT-4.1 API
GPT-4.1代表了AI能力的重大进步,特别是在编码和复杂指令遵循方面。通过Mini和Nano变体的引入,开发者现在有更多灵活性来根据特定需求平衡性能和成本。
通过实施本指南中概述的成本优化策略并考虑像laozhang.ai这样的替代API提供商,您可以有效降低GPT-4.1 API费用,同时仍然利用最先进的AI能力为您的应用提供支持。
对于专注于编码应用的开发者,尽管与之前世代相比成本较高,GPT-4.1在这一领域的改进使其特别有价值。与任何API集成一样,监控使用模式并不断完善您的实现将是最大化投资回报的关键。







