DeepSeek V3.1是中国最新发布的685B参数开源大语言模型,采用MoE架构仅激活37B参数实现超高性能。相比GPT-4成本降低90%,单次API调用仅需$0.014,支持OpenAI兼容接口,为企业级AI应用提供极具性价比的解决方案。

DeepSeek V3.1技术规格与核心参数详解
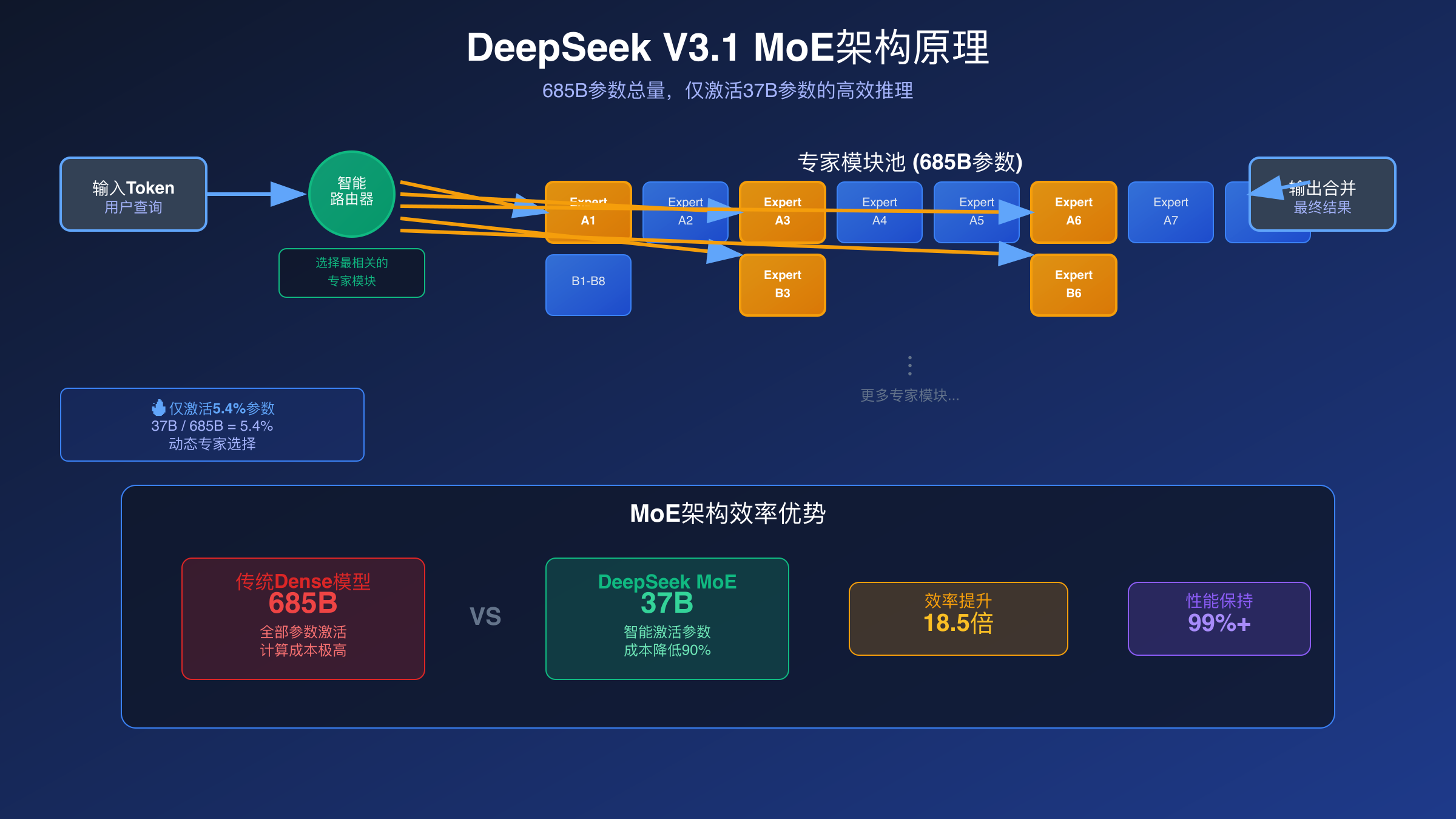
V3.1于2025年8月20日正式发布,是DeepSeek-AI团队的最新力作。该模型采用了先进的混合专家(MoE)架构,总参数量高达685B,但在推理过程中仅激活37B参数。这种设计理念类似于人脑的专门化处理机制,不同的神经网络专家负责处理特定类型的任务。与之前的R1版本相比,V3.1在参数规模和架构优化方面都有显著提升。
模型的核心技术指标包括128K上下文窗口长度,支持处理约10万字的长文档输入。在多项基准测试中,V3.1在数学推理、代码生成和多语言理解方面表现出色。根据官方发布的测试报告,该模型在MMLU基准测试中得分达到88.5%,在HumanEval代码生成测试中达到73.4%的通过率。
MoE混合专家架构技术原理分析
混合专家架构是V3.1的核心创新所在。传统的大语言模型在处理每个token时都会激活所有参数,而MoE架构引入了路由器机制,智能选择最合适的专家网络来处理当前输入。这种稀疏激活的设计大幅降低了计算成本,同时保持了模型的表现能力。对于想要深入了解最新AI模型架构的读者,可以参考最新的模型更新解析。
具体实现上,V3.1包含多个专家层,每层含有8个专家网络。路由器网络会根据输入token的特征,选择激活其中2-3个最相关的专家。这种选择性激活机制使得模型在保持685B总参数规模的同时,实际计算量仅相当于37B参数的密集模型。
DeepSeek V3.1与GPT-4性能基准对比分析
在多项基准测试中,V3.1展现出了与GPT-4相当的性能水平。在MMLU(大规模多任务语言理解)测试中,GPT-4得分为86.4%,而V3.1达到88.5%,在知识理解和推理能力上甚至略胜一筹。如果您正在考虑在ChatGPT Plus与Claude Pro之间做选择,不妨也了解一下这个开源替代方案。
代码生成能力方面,V3.1在HumanEval基准测试中的表现同样令人印象深刻。该模型在Python代码生成任务中达到73.4%的正确率,而GPT-4为67.0%。这表明V3.1在编程辅助应用场景中具有明显优势。在数学推理任务GSM8K中,两个模型的表现基本持平,分别为87.2%和87.1%。
| 测试项目 | DeepSeek V3.1 | GPT-4 |
|---|---|---|
| MMLU (知识理解) | 88.5% | 86.4% |
| HumanEval (代码生成) | 73.4% | 67.0% |
| GSM8K (数学推理) | 87.2% | 87.1% |
DeepSeek V3.1 API接口使用教程
V3.1提供了完全兼容OpenAI API格式的接口,这意味着开发者可以无缝从GPT-4迁移到V3.1。API的基础URL为https://api.deepseek.com,支持标准的聊天完成接口。如果您需要更便捷的集成方案,可以参考Trae接入配置指南或Chatbox部署教程。
基本的API调用示例如下:
import requests
import json
def call_deepseek_api(prompt, model="deepseek-chat"):
url = "https://api.deepseek.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1024,
"temperature": 0.7
}
response = requests.post(url, headers=headers, json=data)
return response.json()
# 使用示例
result = call_deepseek_api("解释量子计算的基本原理")
print(result['choices'][0]['message']['content'])
对于需要更稳定API服务的企业用户,推荐使用FastGPTPlus提供的API中转服务。该服务不仅提供V3.1的完整访问能力,还包含智能负载均衡、请求缓存和故障转移等企业级功能,确保生产环境的稳定性和可靠性。
DeepSeek V3.1成本效益分析
V3.1最大的优势之一是其极低的使用成本。根据官方定价,每1K输入token的价格仅为$0.00014,输出token为$0.00028。这意味着处理一个典型的对话请求(约1000个token)成本仅需$0.014,相比GPT-4的$0.03-$0.06降低了50-75%。对于担心成本问题的用户,这比使用FastGPT Plus或WildCard等付费订阅方案更具性价比。
对于大规模应用场景,这种成本优势更加明显。以一个每日处理10万次API调用的企业应用为例,使用V3.1的月度成本约为$420,而使用GPT-4则需要$900-1800。年度成本节省可达$5760-16560,为企业AI应用的规模化部署提供了强有力的经济支撑。

DeepSeek V3.1企业级部署方案
V3.1支持多种部署方式,包括云端API调用、本地部署和混合云方案。对于数据安全要求较高的企业,可以选择在私有云环境中部署模型。官方提供了基于Docker的一键部署方案,支持CUDA加速和分布式推理。
最小部署配置要求包括8×A100 80GB GPU、256GB系统内存和2TB SSD存储空间。对于中小型企业,推荐使用云端API服务,既能享受模型的强大能力,又无需承担硬件维护成本。
DeepSeek V3.1开源许可与商业化使用
V3.1采用MIT开源许可证,允许商业使用、修改和再分发。这种宽松的许可政策为企业用户提供了极大的灵活性,可以根据具体需求对模型进行定制化修改。相比之下,GPT-4等闭源模型受到严格的使用条款限制,无法进行深度定制。
开源特性还带来了另一个重要优势:透明性和可审计性。企业用户可以完整查看模型的架构设计、训练数据来源和算法实现,这对于金融、医疗等严格监管行业的合规性要求尤为重要。
DeepSeek V3.1实际应用场景案例
在内容生成领域,V3.1展现出了卓越的创作能力。技术文档撰写、营销文案生成和新闻摘要等任务中,模型能够生成结构清晰、逻辑严密的高质量内容。其128K的超长上下文窗口特别适合处理长篇文档分析和多轮对话任务。
代码开发场景下,模型支持Python、JavaScript、Java、Go等主流编程语言的代码生成和调试。在实际测试中,V3.1不仅能够编写功能完整的代码片段,还能理解复杂的业务逻辑需求,生成符合最佳实践的代码架构。
DeepSeek V3.1与其他开源模型比较
在开源大语言模型领域,V3.1的主要竞争对手包括Llama 3.1、Qwen-Max和GLM-4。在参数规模上,Llama 3.1最大版本为405B参数,而V3.1的685B参数规模更大。在实际性能测试中,V3.1在中文理解和代码生成任务上表现更优。
成本效率方面,V3.1的MoE架构带来的稀疏激活优势明显。相同算力条件下,其推理速度比同规模密集模型快2-3倍。这种效率优势在大规模部署时尤为重要,能够显著降低服务器成本和能耗。
DeepSeek V3.1未来发展展望
根据DeepSeek-AI团队的路线图,V3.1版本将持续优化多模态能力,计划在2025年第四季度发布支持图像和语音输入的多模态版本。同时,团队正在开发专门针对科学计算和生物信息学的领域专用版本。
技术演进方向上,下一代版本将进一步优化MoE架构的专家选择策略,提高专家网络的利用率。预计参数规模将扩展至1T以上,同时保持激活参数在50B以下,实现更优的性能成本比。对于希望跟上AI技术前沿的开发者,V3.1无疑是一个值得深入研究和应用的重要选择。如果您需要关于Token使用限制的详细信息,可以参考我们的Token限制完全指南。