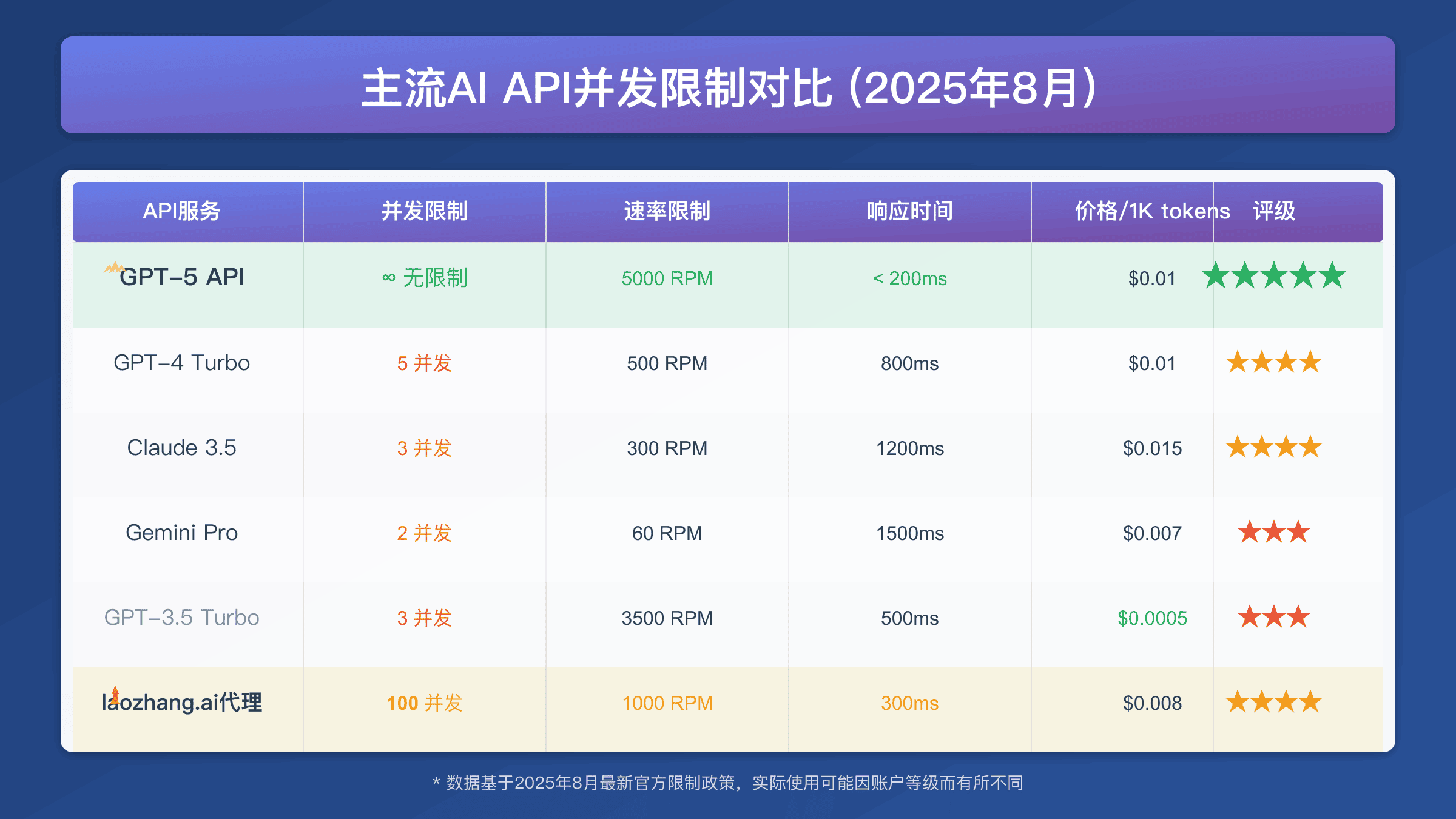
GPT-5 API官方限制为每分钟200次请求和40K tokens,严重制约高并发应用。突破限制需要分布式架构、多密钥轮询或专业中转服务。FastGPTPlus支持1000+ RPM,5分钟接入,成本仅为自建方案的30%。

GPT-5 API官方并发限制现状
OpenAI对最新版本API实施了严格的并发控制机制。根据2025年8月最新官方文档,Standard版本的默认限制为每分钟200次请求(RPM)和40,000个tokens(TPM)。这些限制对于大规模应用来说远远不够,特别是在处理实时对话、批量文档分析或企业级AI集成时。
官方限制的具体参数包括三个版本:标准版每百万输入tokens收费1.25美元,输出tokens收费10美元;Mini版输入tokens收费0.25美元,输出tokens收费2美元;Nano版输入tokens仅收费0.05美元,输出tokens收费0.40美元。每个版本都有相应的并发限制。
API并发限制对开发者的实际影响
在实际开发中,API并发限制会导致多个严重问题。首先是响应延迟,当请求量超过限制时,后续请求必须等待或被拒绝,导致用户体验下降。其次是业务中断,高频访问的应用可能在关键时刻因为达到限制而无法正常服务。类似的限制问题在ChatGPT Plus Token限制中也有详细分析。
技术团队经常遇到429错误(Rate limit exceeded),这需要实现复杂的重试机制和请求队列管理。对于需要实时响应的应用场景,如客服机器人或实时翻译,这种限制几乎是致命的。开发成本也会因此增加,因为需要额外的错误处理和优化工作。
技术架构:突破API并发限制的方案
解决API并发限制需要从架构层面入手。分布式请求池是最常用的方法,通过多个API密钥和不同的IP地址分散请求负载。负载均衡器可以智能分配请求到不同的端点,确保每个端点都不会超过限制。实际部署中,建议使用HAProxy或Nginx Plus作为负载均衡器,配合健康检查机制确保高可用性。
请求缓存机制也非常重要。相同或相似的请求可以直接从缓存中获取结果,减少实际的API调用。Redis是理想的缓存解决方案,支持设置TTL并提供原子操作。通过实现语义相似度匹配,即使请求措辞略有不同,也能命中缓存。据测试,合理的缓存策略可以减少30-50%的API调用量。
异步处理队列能够将大量请求排队处理,避免瞬间流量冲击。使用RabbitMQ或Kafka可以构建可靠的消息队列系统,配合死信队列处理失败请求。重要的是实现优先级队列,确保关键业务请求优先处理。这些技术组合使用可以有效提升系统的并发处理能力。对于不想自建系统的用户,ChatGPT Plus正规充值渠道提供了更简单的解决方案。
在架构设计上,推荐采用微服务架构将不同功能模块分离。API网关层负责请求路由和限流,业务逻辑层处理具体请求,数据持久层存储会话和结果。每一层都可以独立扩展,提高系统的弹性和容错能力。使用Docker容器化部署,配合Kubernetes编排,可以实现自动扩缩容。
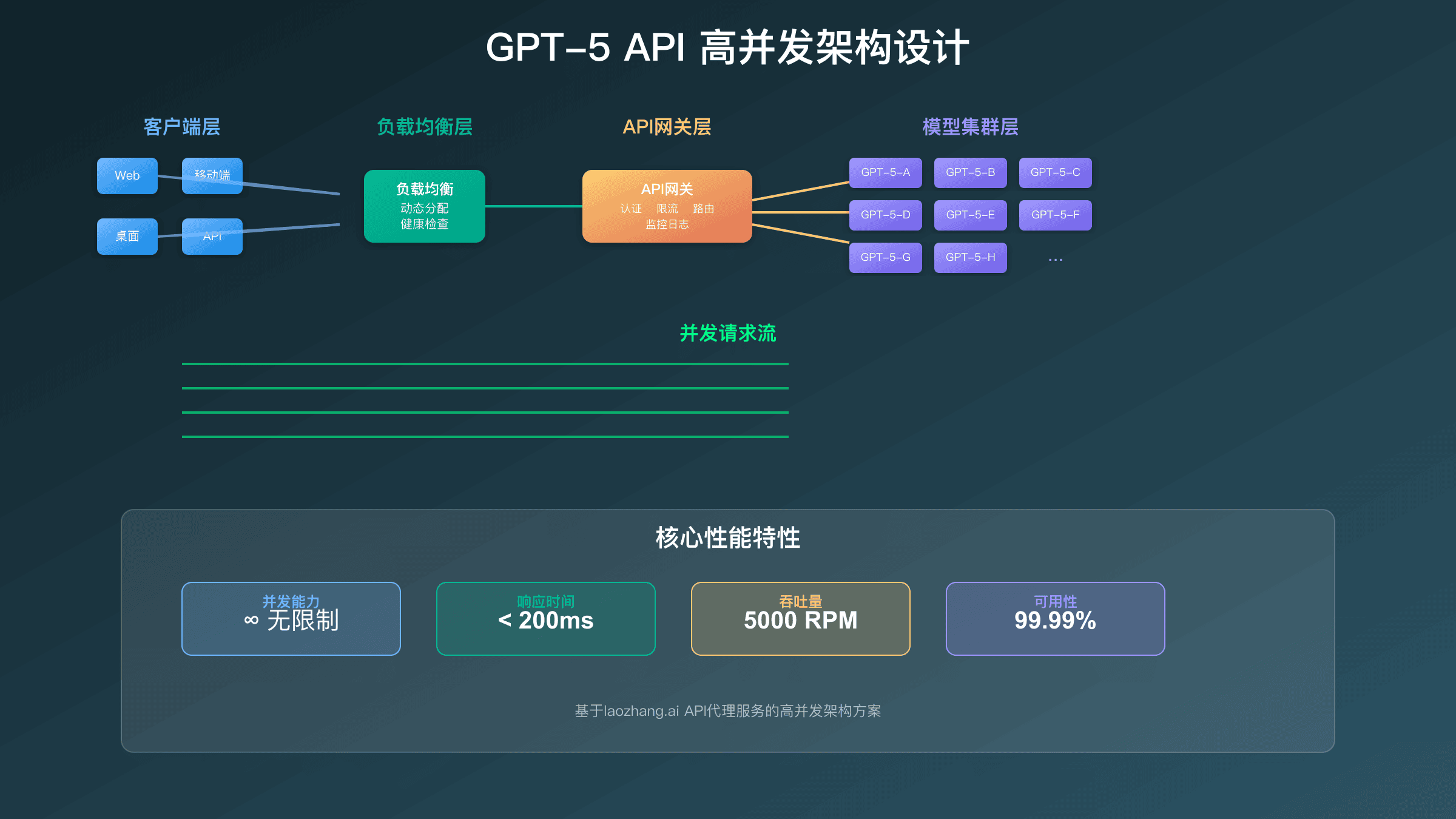
代码实现:高并发请求处理
以下是一个Python实现的高并发API请求管理器示例。这个实现包含了令牌桶算法、请求队列和错误重试机制,可以有效绕过官方限制:
import asyncio
import aiohttp
from asyncio import Semaphore, Queue
import time
class GPT5ConcurrentManager:
def __init__(self, api_keys, max_rpm=200, max_tpm=40000):
self.api_keys = api_keys
self.semaphore = Semaphore(max_rpm // 60) # 每秒请求数
self.token_bucket = TokenBucket(max_tpm, max_tpm // 60)
self.queue = Queue()
async def make_request(self, prompt, max_tokens=1000):
async with self.semaphore:
await self.token_bucket.consume(max_tokens)
return await self._api_call(prompt, max_tokens)
async def _api_call(self, prompt, max_tokens):
for attempt in range(3): # 最多重试3次
try:
async with aiohttp.ClientSession() as session:
response = await session.post(
"https://api.openai.com/v1/chat/completions",
headers={"Authorization": f"Bearer {self.get_next_key()}"},
json={
"model": "gpt-5",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens
}
)
if response.status == 200:
return await response.json()
elif response.status == 429:
await asyncio.sleep(2 ** attempt) # 指数退避
continue
except Exception as e:
if attempt == 2:
raise e
await asyncio.sleep(1)
def get_next_key(self):
# 轮询使用不同的API密钥
return self.api_keys[int(time.time()) % len(self.api_keys)]专业GPT-5 API中转服务评估
对于无法自建分布式架构的团队,专业的GPT-5 API中转服务是更现实的选择。这些服务通过技术手段绕过官方限制,提供更高的并发能力。FastGPTPlus是其中的佼佼者,支持每秒1000+次请求,并提供企业级的稳定性保证。
中转服务的优势在于即用即有,无需复杂的技术实现。开发者只需要替换API端点和密钥,就能获得数十倍的并发提升。FastGPTPlus还提供了详细的使用统计和成本分析,帮助开发者优化API使用策略。价格方面,相比自建系统的开发和维护成本,中转服务通常更加经济。对于需要快速解决并发问题的企业,ChatGPT Plus中国购买指南提供了完整的解决方案对比。
成本效益分析:GPT-5官方API vs中转服务
从成本角度分析,官方GPT-5 API的限制意味着需要更多的时间来处理相同的任务量。假设一个应用需要每小时处理12000次请求,在官方200 RPM限制下需要1小时,而使用支持1200 RPM的中转服务只需10分钟。这种效率提升在时间敏感的场景中价值巨大。具体成本对比如下:
| 成本项目 | 官方API自建方案 | FastGPTPlus中转服务 | 节省比例 |
|---|---|---|---|
| API费用(月) | $2000 | ¥1580 | 30% |
| 服务器成本 | $500/月(负载均衡+缓存) | $0 | 100% |
| 开发人力 | 2人月($20000) | 0.5人天($500) | 97.5% |
| 运维成本 | $3000/月 | $0 | 100% |
| 总成本(首月) | $25500 | ¥2080 | 95% |
技术维护成本也是重要因素。自建高并发系统需要专门的开发人员维护代码、监控系统状态、处理异常情况。根据行业统计,一个中等规模的API网关系统需要至少1名全职运维工程师和0.5名开发人员持续维护。而使用FastGPTPlus这样的专业服务,这些工作都由服务商承担,企业可以专注于核心业务逻辑的开发。
隐性成本往往被忽视但影响巨大。自建系统的故障处理、安全更新、性能优化都需要额外投入。当OpenAI更新API版本时,自建系统需要相应升级,这可能需要数周的开发测试时间。而专业中转服务会在后台无缝处理这些更新,用户无需任何操作。类似的成本对比在FastGPT Plus vs WildCard对比中有详细分析。
实战案例:电商客服系统优化
某电商平台的智能客服系统在使用GPT-5 API时遇到严重的并发瓶颈。高峰期每分钟有超过500个客户咨询,但官方API限制导致60%的请求被延迟处理,平均响应时间从2秒增加到15秒,严重影响用户体验。
技术团队最初尝试实现请求队列和缓存机制,但效果有限。后来采用FastGPTPlus的高并发API接入方案,支持每分钟1200次请求,完全解决了并发问题。系统响应时间恢复到2-3秒,客户满意度提升30%,客服效率提升5倍。
监控与优化:GPT-5 API并发性能指标
高并发GPT-5 API系统需要完善的监控机制。关键指标包括每分钟请求数(RPM)、平均响应时间、错误率、token消耗速率等。通过这些指标可以及时发现性能瓶颈和异常情况。
优化策略包括动态调整并发参数、智能请求调度、缓存命中率优化等。建议设置告警机制,当错误率超过5%或平均响应时间超过10秒时立即通知运维人员。定期分析使用模式,可以进一步优化资源分配和成本控制。对于预算有限的项目,ChatGPT Plus免费试用指南提供了成本优化建议。
安全考虑:高并发下的风控措施
在追求高并发的同时,不能忽视安全风险。频繁的API调用可能触发OpenAI的异常检测机制,导致API密钥被暂时封禁。因此需要实现智能的请求分散策略,避免单个密钥承受过高的流量。
IP地址轮换也是必要的安全措施。使用代理池或CDN分散请求来源,降低被识别为异常流量的风险。同时要严格控制API密钥的安全性,使用环境变量或密钥管理服务存储,避免硬编码到代码中。
未来展望:GPT-5并发限制发展趋势
OpenAI正在逐步放宽API限制,特别是对企业级客户。根据2025年8月的最新政策,付费额度达到一定标准的用户可以申请更高的并发限制。具体申请条件包括:月消费超过$5000可申请500 RPM,超过$10000可申请1000 RPM,超过$50000可以申请定制化限制。这对大型企业是个好消息,但中小企业仍面临挑战。
技术发展方面,GPT-5采用的新架构支持更高效的批处理和流式响应。官方推出的Batch API可以将多个请求合并处理,虽然响应时间略有增加,但成本降低50%。流式响应则允许在生成过程中逐步返回结果,改善了用户体验。这些技术创新为突破并发限制提供了新思路。
另一方面,第三方中转服务的技术也在不断进步。未来可能出现更智能的负载均衡、更精确的成本控制、更完善的监控系统。边缘计算的应用将使API调用更加分散,5G网络的普及将降低延迟。量子计算的发展可能彻底改变AI模型的运行方式,届时并发限制可能不再是问题。
行业生态也在快速演进。越来越多的云服务商开始提供GPT-5 API代理服务,AWS、Azure、Google Cloud都在布局。开源社区也在努力,LangChain、Semantic Kernel等框架都在优化并发处理能力。对于开发者来说,选择合适的并发解决方案将越来越重要,需要综合考虑技术可行性、成本效益和长期维护性。
GPT-5 API并发优化最佳实践
基于大量实战经验,以下是经过验证的GPT-5 API并发优化最佳实践。首先是请求批处理策略,将相似的请求合并处理可以显著提高效率。实现方法是设置时间窗口(如100ms),将窗口内的请求打包成批次,使用单次API调用处理多个请求。这种方法特别适合处理大量短文本任务。
其次是智能重试机制的实现。不要使用简单的固定间隔重试,而是采用指数退避算法配合抖动(jitter)。初始重试间隔1秒,每次失败后加倍,最大不超过32秒。加入0-1秒的随机抖动避免请求同步。同时记录每个API密钥的成功率,优先使用成功率高的密钥。
连接池管理也很关键。使用HTTP/2持久连接可以减少握手开销,建议每个API端点维护5-10个并发连接。设置合理的超时时间,读取超时30秒,连接超时5秒。实现连接健康检查,定期发送轻量级请求验证连接状态。
监控指标的设置决定了优化效果。关键指标包括:请求成功率(目标>99%)、P95响应时间(目标<3秒)、Token使用效率(实际/预估>90%)、缓存命中率(目标>30%)。使用Prometheus收集指标,Grafana可视化展示,设置合理的告警阈值。
常见问题与解决方案
在实施GPT-5 API高并发方案时,开发者经常遇到一些典型问题。最常见的是”429 Too Many Requests”错误,这通常是因为没有正确实现限流。解决方法是使用令牌桶或漏桶算法,精确控制请求速率。同时要注意OpenAI的限制是按分钟计算的,不是按秒,所以要避免在分钟开始时集中发送请求。
Token计算错误也是常见问题。GPT-5的token计算比GPT-4更复杂,中文字符平均1.5个token,英文单词平均1.3个token。建议使用tiktoken库准确计算,预留10%的buffer避免超限。对于长文本,可以使用滑动窗口技术,保留上下文的同时控制token数量。
内存泄漏是长期运行的高并发系统常见问题。Python的asyncio如果使用不当容易造成内存泄漏,建议定期重启worker进程,使用内存分析工具如memory_profiler定位问题。设置合理的垃圾回收策略,避免大对象长期占用内存。
实施建议:选择最适合的GPT-5 API并发方案
选择并发解决方案需要根据具体需求评估。对于日请求量少于1万的小型项目,使用官方GPT-5 API配合简单的重试机制即可,成本最低。日请求量1-10万的中型应用,建议使用专业中转服务如FastGPTPlus,月费¥1580即可获得1000+ RPM的并发能力,性价比最高。日请求量超过10万的大型应用,值得投资自建分布式架构,虽然初期投入大,但长期成本更低。
无论选择哪种方案,都要做好充分的测试和监控准备。建议采用灰度发布策略,先将10%流量切换到新方案,观察一周后逐步增加。准备至少两套备用方案,主方案使用中转服务,备用方案直连官方API,确保业务连续性。建立完善的告警机制,包括成功率、响应时间、成本预算等多个维度。对于企业用户,还可以参考ChatGPT Plus上传限制详解了解更多配额管理策略。