本地部署需要以下5个核心步骤:选择合适的硬件配置、安装Ollama环境、下载DeepSeek模型、配置运行参数、验证部署效果。本文提供完整的部署指南和成本分析。
DeepSeek本地部署硬件配置选择指南
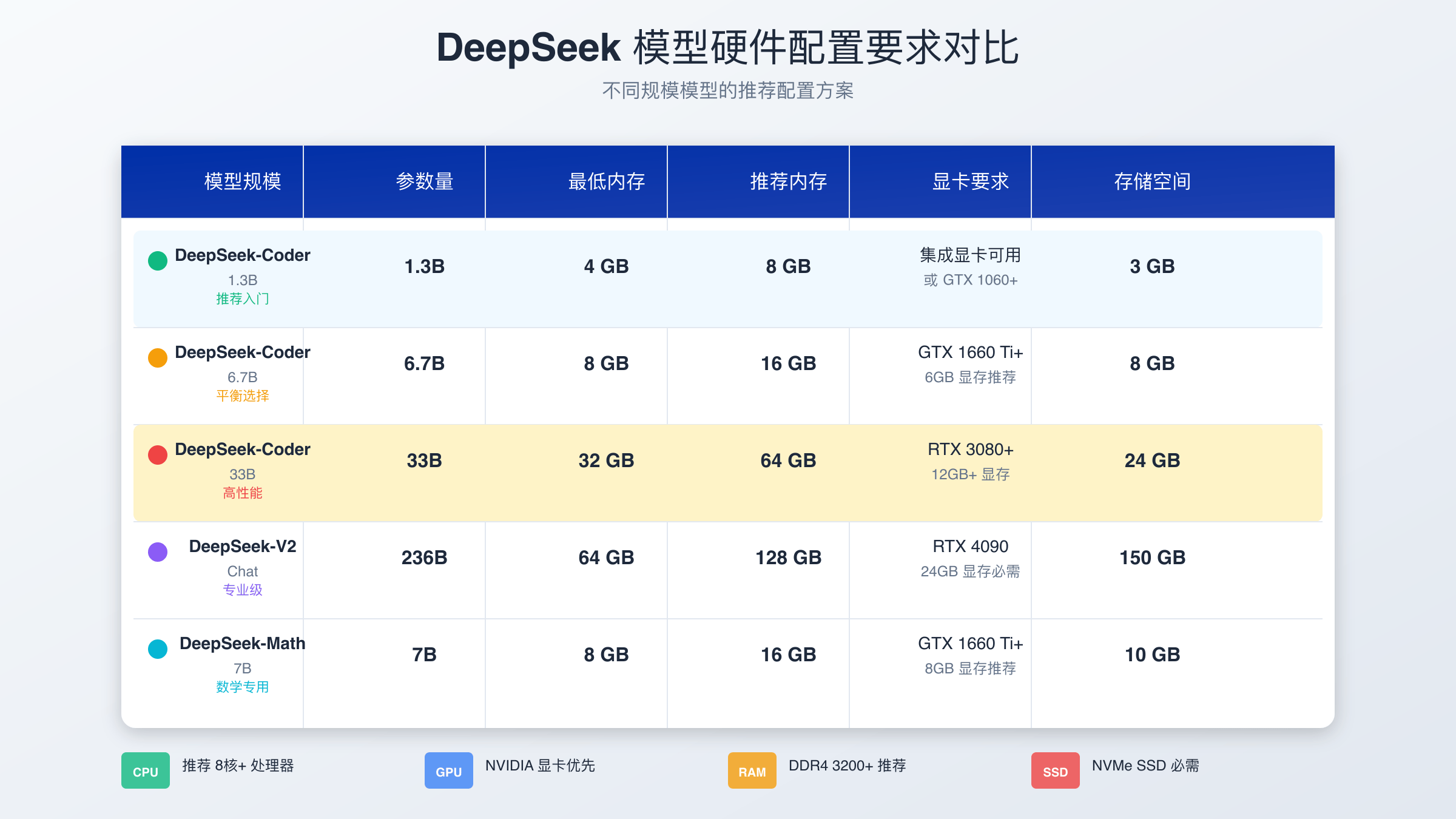
选择合适的硬件配置是本地部署成功的关键因素。根据官方文档,不同参数规模的模型对硬件要求差异显著。DeepSeek-R1 1.5B模型最低需要8GB内存和4GB显存,适合普通用户初次体验。7B模型推荐16GB内存配合8GB显存,能够提供较好的推理性能。对于追求极致性能的用户,32B模型需要32GB内存,而完整的671B版本则需要700GB显存的企业级配置。
从性价比角度考虑,RTX 3060 12GB显卡是入门级本地部署的理想选择,价格相对亲民且能够满足7B模型的运行需求。中高端用户可以选择RTX 4070或4080,提供更好的推理速度和更大的模型支持能力。需要注意的是,CPU性能同样重要,建议选择8核心以上的处理器以确保系统整体运行流畅。

本地部署环境准备和系统要求
DeepSeek本地部署支持Windows、macOS和Linux三大主流操作系统,但在不同系统上的配置步骤略有差异。Windows用户需要确保系统版本为Windows 10或更高,并安装最新的显卡驱动程序。macOS用户建议使用macOS 12.0或更高版本,M系列芯片的Mac设备在运行效率上具有一定优势。Linux用户通常能够获得最佳的部署体验,Ubuntu 20.04 LTS是推荐的发行版。
存储空间规划同样不容忽视,不同规模的模型文件大小差异明显。1.5B模型约需3GB存储空间,7B模型需要8GB,而完整的671B模型则需要400GB以上的高速存储。推荐使用SSD固态硬盘以提升模型加载速度,机械硬盘会严重影响部署后的响应性能。
Ollama安装配置详细步骤
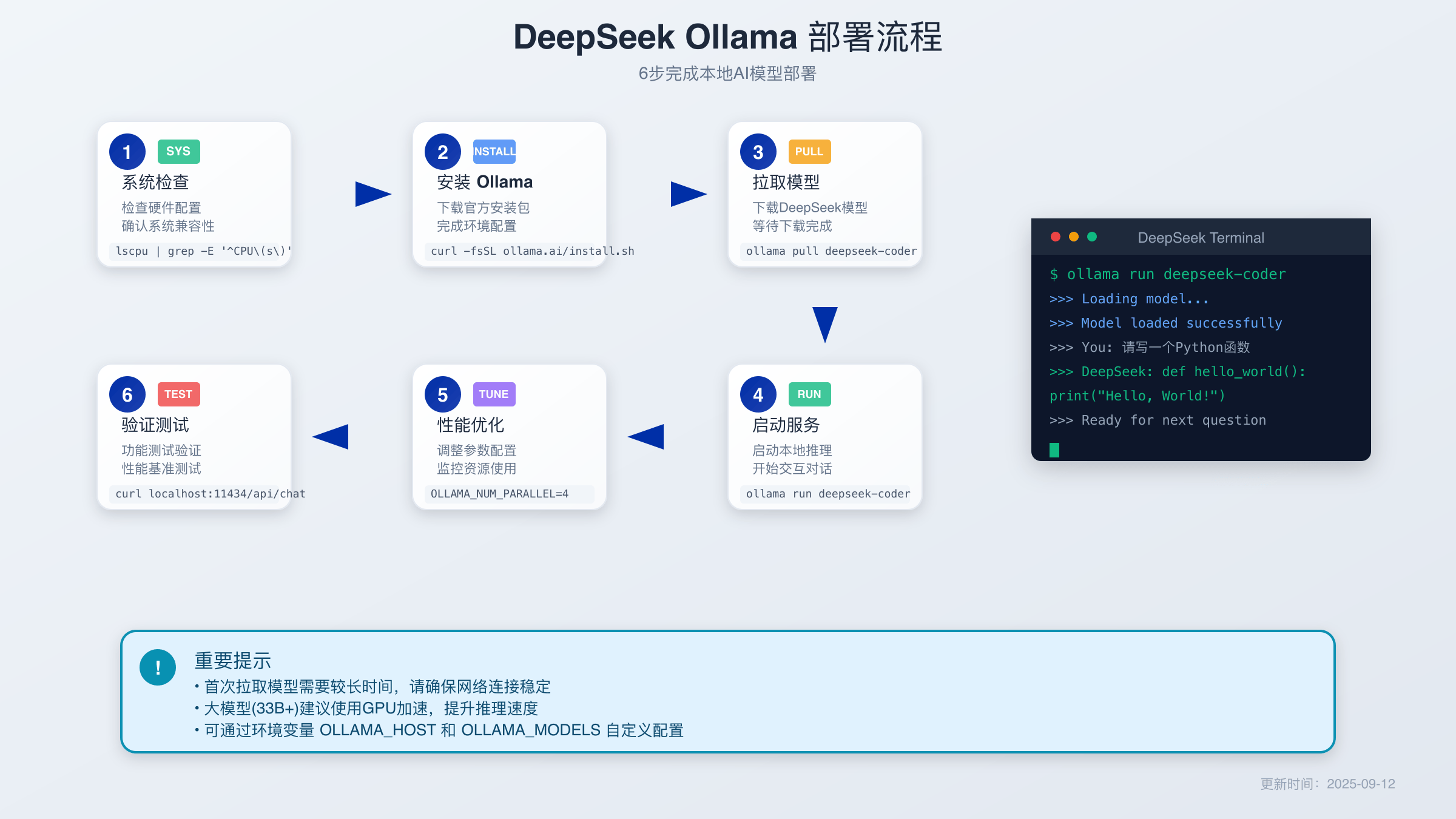
Ollama是目前最流行的本地大语言模型管理工具,安装过程相对简单。访问Ollama官网https://ollama.com下载对应系统的安装包,Windows用户直接运行安装程序即可。Linux用户可以使用一键安装命令:curl -fsSL https://ollama.com/install.sh | sh。安装完成后,在命令行输入ollama version验证安装是否成功。
环境变量配置是优化Ollama使用体验的重要步骤。默认情况下,模型文件存储在系统盘,可能导致C盘空间不足。通过设置OLLAMA_MODELS环境变量,可以将模型存储目录迁移到其他磁盘。Windows用户在系统环境变量中设置变量名为OLLAMA_MODELS,变量值为目标路径如D:\OllamaModels。Linux用户可以在.bashrc文件中添加export OLLAMA_MODELS=/home/user/models。
DeepSeek模型下载和版本选择
选择适合的模型版本需要综合考虑硬件配置和使用需求。对于初学者或硬件配置有限的用户,建议从1.5B版本开始体验,使用命令ollama run deepseek-r1:1.5b即可自动下载并启动模型。该版本对硬件要求最低,但在复杂推理任务上可能表现有限。7B版本是大多数用户的最佳选择,在性能和资源消耗之间达到良好平衡。
模型下载过程可能需要较长时间,具体取决于网络速度和模型大小。7B模型文件约4GB,在100Mbps网络环境下预计需要5-10分钟完成下载。下载过程中可以继续使用命令行执行其他操作,Ollama支持断点续传功能,网络中断后重新执行命令可以从断点继续下载。完成下载后,模型会自动初始化并进入对话模式。
本地部署核心配置参数优化
DeepSeek本地部署的性能表现很大程度上取决于配置参数的优化。内存管理是最关键的优化方向,可以通过设置OLLAMA_NUM_PARALLEL参数控制并发处理数量。对于8GB内存的系统,建议设置为1以避免内存不足导致的系统卡顿。16GB内存的系统可以尝试设置为2,进一步提升多任务处理能力。
GPU加速配置对推理速度的影响非常显著。确保NVIDIA显卡驱动程序为最新版本,并安装CUDA工具包以启用GPU加速。可以通过nvidia-smi命令查看显卡状态和显存使用情况。如果系统同时安装了多张显卡,可以通过CUDA_VISIBLE_DEVICES环境变量指定使用特定的GPU设备。温度控制也很重要,建议在高负载运行时监控GPU温度,避免过热影响稳定性。
部署测试验证和功能检查
完成DeepSeek模型部署后,需要进行系统性的测试验证以确保功能正常。基础对话测试是第一个验证步骤,可以提问简单的数学计算或常识性问题来测试模型的响应能力。例如询问”1+1等于多少?”或”请介绍一下Python编程语言”,观察模型是否能够给出准确和流畅的回答。
性能指标验证包括响应时间和处理速度的测量。正常情况下,7B模型在RTX 3060显卡上的首字响应时间应在2-5秒内,后续字符生成速度约为10-15字符每秒。如果响应明显延迟或出现异常,需要检查系统资源使用情况和配置参数设置。可以通过top或任务管理器监控CPU和内存使用率,确保系统运行在合理范围内。
常见部署问题故障排除方案
本地部署过程中可能遇到各种技术问题,掌握有效的故障排除方法能够快速解决大部分困难。模型下载失败是最常见的问题之一,通常由网络连接不稳定或下载源访问受限导致。解决方法包括更换网络环境、使用代理服务器或配置镜像源。国内用户可以尝试使用阿里云或腾讯云提供的镜像加速服务,或参考Ollama 403错误解决方案中的环境配置方法。
内存不足导致的运行错误也经常出现,特别是在尝试运行大型模型时。症状包括系统卡顿、模型加载失败或推理过程异常终止。解决策略包括关闭不必要的后台程序、增加虚拟内存设置或选择参数较小的模型版本。如果问题持续存在,建议考虑硬件升级或使用量化版本的模型以降低内存需求。
AI模型本地部署性能优化技巧
性能优化是提升本地部署体验的重要环节。推理速度优化可以从多个维度入手,首先是硬件层面的优化,确保使用高性能NVMe SSD存储模型文件,这能够显著减少模型加载时间。其次是软件配置优化,合理设置batch size和context length参数,避免过高的设置导致内存溢出。
资源使用优化需要根据具体使用场景进行调整。对于交互式对话场景,可以适当增加context length以保持更长的对话记忆。对于批量处理任务,则应该优化batch size以提高吞吐量。监控系统资源使用情况是持续优化的基础,推荐使用htop、nvidia-smi等工具实时监控CPU、内存和GPU使用状态,及时发现性能瓶颈。
本地部署与云端API成本效益对比
选择本地部署还是云端API服务需要综合考虑成本、性能和使用便利性等多个因素。本地部署的主要成本包括硬件购置、电力消耗和维护成本。以7B模型为例,推荐的硬件配置总成本约2000-5000美元,包括高性能显卡、充足内存和快速存储。电力消耗方面,RTX 3060显卡满载功耗约170W,按照每天8小时使用计算,年电费约150-300美元。
云端API服务的成本结构更加透明和灵活。官方API定价为每百万输入token 0.55美元,输出token 2.19美元。对于中等使用强度的用户,月费用通常在50-200美元之间。laozhang.ai等第三方API服务提供商通常提供更具竞争力的价格和更稳定的服务质量,特别适合需要多模型访问能力的开发者和企业用户。从长期角度看,高频使用场景下本地部署可能更经济,而临时或低频使用则推荐选择AI模型云端服务。
Web界面集成和API接口配置
为本地部署添加Web界面能够显著提升使用体验,特别是对于不熟悉命令行操作的用户。Open WebUI是目前最受欢迎的选择,支持与Ollama无缝集成。安装过程相对简单,可以使用Docker容器或直接安装Python包。Docker方式的命令为:docker run -d -p 3000:80 -v open-webui:/app/backend/data –name open-webui ghcr.io/open-webui/open-webui:main。
API接口配置允许其他应用程序调用本地部署的DeepSeek模型。Ollama默认在localhost:11434端口提供REST API服务,支持与OpenAI API兼容的调用方式。开发者可以使用curl、Python requests库或专门的SDK进行API调用。典型的调用示例:curl http://localhost:11434/api/generate -d ‘{“model”: “deepseek-r1:7b”, “prompt”: “Hello”}’。这种方式特别适合将DeepSeek集成到现有的应用系统中。
AI模型更新和维护指南
保持DeepSeek模型的更新对于获得最佳性能和安全性至关重要。Ollama提供了便捷的模型管理功能,可以使用ollama list命令查看已安装的模型列表,使用ollama pull deepseek-r1:latest命令更新到最新版本。更新过程会自动下载新版本模型文件,同时保留旧版本以确保服务连续性。
备份恢复策略是维护工作的重要组成部分。建议定期备份模型配置文件和自定义参数设置。可以将整个OLLAMA_MODELS目录复制到外部存储设备作为备份。恢复时,只需将备份文件复制回原目录即可快速恢复服务。对于企业级应用,建议建立自动备份机制和灾难恢复预案,确保服务的高可用性。
本地部署适用场景和决策建议
DeepSeek本地部署在特定场景下具有显著优势,特别是对数据隐私和安全有严格要求的应用场景。金融机构、医疗机构和政府部门通常需要将敏感数据保留在内部环境中,本地部署能够完全满足这一需求。此外,网络环境受限或需要离线运行的场景也是本地部署的理想应用领域。
个人用户的选择建议需要根据使用频率和技术能力进行评估。对于AI爱好者和开发者,本地部署提供了完全的控制权和定制能力,是学习和实验的理想平台。对于普通用户,如果使用频率不高或主要进行简单任务,建议优先考虑laozhang.ai等云端服务,能够获得更好的成本效益和使用体验。企业用户需要综合考虑数据安全、成本控制和维护能力等因素,制定最适合自身需求的部署策略。