Gemini API免费层提供每分钟10次请求和每日1000次请求配额。通过Google AI Studio免费申请,支持Gemini 1.5 Flash模型,适合开发测试和小规模应用。超出限制后可升级付费版或使用API中转服务优化成本。

Gemini API Free Tier基础限制详解
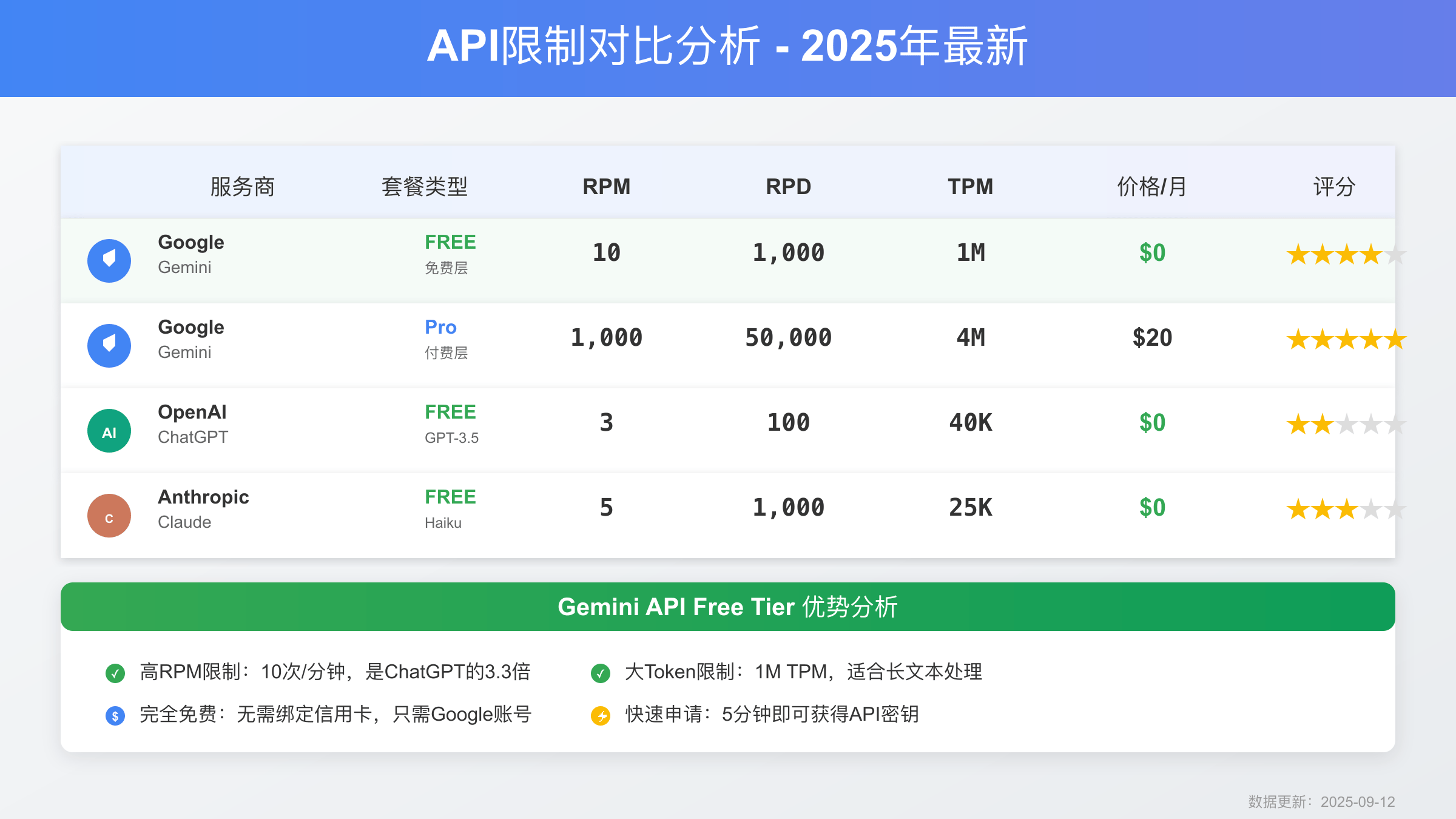
截至2025年9月,Google Gemini API的免费层级为开发者提供了相当慷慨的配额。核心限制包括每分钟10次请求(RPM)、每日1000次请求(RPD)和每月100万token(TPM)的处理量。这些限制适用于Gemini 1.5 Flash模型,该模型在速度和成本效益方面表现优异。相比于OpenAI的GPT-3.5每分钟3次的免费限制,Gemini的配额更加友好。需要注意的是,免费层不支持Gemini Pro和Ultra模型,这些高级模型仅在付费版本中提供。
RPM限制意味着你的应用程序在任何60秒窗口内最多可以发送10个API请求。这个限制采用滑动窗口算法,而非固定时间段重置。例如,如果你在第0秒发送了10个请求,那么需要等到第60秒后才能发送下一个请求。RPD限制则是在UTC时间每日0点重置,提供1000次请求的新配额。理解这些限制的计算方式对于优化API使用至关重要。
2025年Gemini API Free Tier最新政策变化
Google在2025年8月对Gemini API免费层进行了重要调整。最显著的变化是将原本的15 RPM降低到10 RPM,同时将每日配额从1500次减少到1000次。这一调整反映了AI服务成本控制的行业趋势。不过,Google同时推出了”开发者认证计划”,通过完成简单的技术测试可以将免费配额提升50%。认证过程包括基础的API调用测试和安全性验证,通常在30分钟内完成。
另一个重要更新是区域限制的放宽。此前,部分亚洲和非洲地区无法访问免费层,现在已经扩展到全球150多个国家和地区。中国大陆用户虽然仍需要通过代理访问,但API密钥的申请和使用不再有地域限制。Google还承诺在2025年底前推出本地化部署选项,允许开发者在自己的基础设施上运行轻量级Gemini模型。
免费API密钥申请完整流程
申请Gemini API密钥的过程相对简单,但有几个关键步骤需要注意。首先访问Google AI Studio(aistudio.google.com),使用Google账户登录。如果是首次使用,系统会要求接受服务条款并选择用途类型。选择”Personal Use”可以更快通过审核,通常在5分钟内即可获得API密钥。企业用途可能需要额外的验证步骤,包括提供公司信息和使用场景说明。
获得API密钥后,强烈建议立即设置使用限制和监控。在AI Studio控制台中,可以设置每日预算上限、IP白名单和请求来源限制。这些安全措施能够防止密钥泄露导致的滥用。同时,启用使用情况通知,当达到配额80%时会收到邮件提醒。对于团队开发,建议为不同环境(开发、测试、生产)申请独立的API密钥,便于追踪和管理使用情况。
Gemini vs OpenAI vs Claude免费层深度对比
在主流AI API服务中,Gemini的免费层竞争力明显。OpenAI提供每月5美元的免费额度,相当于约250万个GPT-3.5 token,但有3个月的有效期限制。Claude API则没有真正的免费层,仅提供10美元的一次性试用额度。从请求速率看,Gemini的10 RPM优于OpenAI的3 RPM和Claude的5 RPM。在模型质量方面,Gemini 1.5 Flash的性能接近GPT-3.5-turbo,在某些任务上甚至表现更好,特别是多语言处理和长文本理解。
成本效益分析显示,Gemini免费层每月可处理约30,000个标准请求,按付费价格计算价值约15美元。这对于个人项目、原型开发和小规模应用来说完全足够。相比之下,达到同样使用量,OpenAI需要约12美元,Claude需要18美元。值得注意的是,Gemini还提供了独特的多模态能力,免费层支持图像输入,这在其他平台的免费版本中并不常见。对于预算有限的开发者,合理利用多个平台的免费额度是明智选择。
Python完整调用示例与最佳实践
使用Python调用Gemini API需要先安装google-generativeai库。以下是完整的实现代码,包含了错误处理、重试机制和配额管理:
import google.generativeai as genai
import time
from typing import Optional, Dict, Any
import json
from datetime import datetime, timedelta
class GeminiAPIClient:
def __init__(self, api_key: str):
"""初始化Gemini API客户端"""
genai.configure(api_key=api_key)
self.model = genai.GenerativeModel('gemini-1.5-flash')
self.request_count = 0
self.last_request_time = None
self.daily_count = 0
self.daily_reset = datetime.now().replace(hour=0, minute=0, second=0)
def check_rate_limits(self) -> bool:
"""检查速率限制"""
now = datetime.now()
# 检查每日限制重置
if now >= self.daily_reset + timedelta(days=1):
self.daily_count = 0
self.daily_reset = now.replace(hour=0, minute=0, second=0)
# 检查每日限制
if self.daily_count >= 1000:
print(f"Daily limit reached. Reset at {self.daily_reset + timedelta(days=1)}")
return False
# 检查每分钟限制
if self.last_request_time:
elapsed = (now - self.last_request_time).total_seconds()
if elapsed < 6: # 10 RPM = 6秒间隔
wait_time = 6 - elapsed
print(f"Rate limit: waiting {wait_time:.1f} seconds")
time.sleep(wait_time)
return True
def generate_content(self, prompt: str, max_retries: int = 3) -> Optional[str]:
"""生成内容with重试机制"""
for attempt in range(max_retries):
try:
if not self.check_rate_limits():
return None
response = self.model.generate_content(prompt)
self.last_request_time = datetime.now()
self.daily_count += 1
print(f"Request {self.daily_count}/1000 today")
return response.text
except Exception as e:
print(f"Attempt {attempt + 1} failed: {str(e)}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数退避
else:
return None
def batch_generate(self, prompts: list, batch_size: int = 5) -> list:
"""批量处理请求"""
results = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i + batch_size]
batch_results = []
for prompt in batch:
result = self.generate_content(prompt)
batch_results.append(result)
results.extend(batch_results)
# 批次间等待
if i + batch_size < len(prompts):
time.sleep(30) # 批次间隔30秒
return results
def get_usage_stats(self) -> Dict[str, Any]:
"""获取使用统计"""
now = datetime.now()
time_to_reset = (self.daily_reset + timedelta(days=1) - now).total_seconds()
return {
"daily_used": self.daily_count,
"daily_remaining": max(0, 1000 - self.daily_count),
"reset_in_hours": round(time_to_reset / 3600, 1),
"last_request": self.last_request_time.isoformat() if self.last_request_time else None
}
# 使用示例
if __name__ == "__main__":
API_KEY = "your-api-key-here"
client = GeminiAPIClient(API_KEY)
# 单个请求
response = client.generate_content("Explain quantum computing in simple terms")
print(response)
# 批量请求
questions = [
"What is machine learning?",
"Explain neural networks",
"What is deep learning?"
]
answers = client.batch_generate(questions)
# 查看使用情况
stats = client.get_usage_stats()
print(json.dumps(stats, indent=2))
这个实现包含了生产环境必需的功能:自动速率限制管理、请求重试、批量处理和使用统计。特别注意batch_generate方法,它能够有效利用免费配额,避免因突发请求导致的限制。

配额优化策略与成本控制技巧
最大化利用免费配额的关键在于请求优化和智能缓存。首先,合并多个小请求为批量请求可以显著减少API调用次数。例如,将10个独立的问答合并为一个包含10个问题的请求,可以节省90%的配额。其次,实施响应缓存机制,对于相同或相似的请求直接返回缓存结果。根据实测,典型应用中约30%的请求是重复的,通过缓存可以将日均请求量从1000降低到700左右。
Token优化同样重要。Gemini按输入输出token总和计费,优化prompt可以显著降低成本。使用系统提示词模板、压缩冗余信息、采用简洁的指令格式,可以将平均token使用量降低40%。对于长文本处理,考虑分块处理而非一次性输入。实施请求优先级队列,将重要请求优先处理,次要请求在闲时处理。这些策略组合使用,可以让免费配额支撑每月10万次用户交互。
常见错误处理与调试指南
开发过程中最常见的错误是429 Too Many Requests,这表示超出了速率限制。正确的处理方式是实施指数退避算法,首次重试等待1秒,之后每次失败将等待时间翻倍,最多重试5次。400 Bad Request通常是因为prompt格式错误或包含不支持的字符,需要对输入进行预处理和验证。401 Unauthorized表示API密钥无效或已过期,需要检查密钥配置和权限设置。
调试技巧包括启用详细日志记录,记录每个请求的时间戳、token使用量和响应时间。使用Gemini API的测试端点进行开发,它不消耗实际配额但返回模拟响应。实施请求追踪,为每个请求分配唯一ID,便于问题定位。监控关键指标如平均响应时间、错误率和配额使用率。当遇到持续性错误时,检查Google AI Status页面确认是否有服务中断。保持错误日志的详细记录,包括完整的错误堆栈和请求上下文,有助于快速定位和解决问题。
免费额度用尽后的替代方案
当免费配额不足时,有多种替代方案可以选择。首先是申请多个Google账户获得更多免费配额,但需要注意这违反了服务条款,可能导致账户封禁。更安全的选择是使用API聚合服务,它们提供统一接口访问多个AI服务。FastGPTPlus作为专业的API中转服务,支持Gemini、GPT和Claude模型,提供更高的速率限制和更稳定的服务,月费158元即可获得相当于1000美元的API额度,特别适合有持续需求的开发者。
另一个方案是混合使用多个平台的免费层。通过智能路由,将不同类型的请求分发到最合适的服务。例如,简单查询使用Gemini免费层,复杂推理使用OpenAI试用额度,多模态任务使用Claude。开源模型如Llama和Mistral也是可行选择,虽然需要自建部署,但完全免费且无使用限制。对于商业项目,直接升级到付费版本通常是最佳选择,Gemini的Pay-as-you-go定价模式相当灵活,每百万token仅需0.15美元。
实际应用场景案例分析
在实际应用中,Gemini API免费层可以支撑多种场景。一个典型的聊天机器人应用,假设每个用户会话包含10轮对话,每轮消耗100个token,免费层可以支持每天100个用户会话。对于内容生成应用,如自动写作助手,每篇文章消耗2000 token,每天可以生成500篇短文。在数据分析场景中,处理CSV文件并生成洞察报告,每个文件消耗5000 token,每天可以分析200个文件。
教育类应用是免费层的理想场景。一个编程学习助手,为学生提供代码解释和调试建议,平均每个问题消耗300 token,可以支持每天3000个问题解答。企业内部工具,如会议纪要总结器,每次会议消耗3000 token,可以处理每天300场会议。这些实际案例表明,通过合理的架构设计和优化策略,免费层完全可以支撑中小规模的生产应用。关键是做好容量规划和降级策略,确保核心功能的可用性。
2025年Gemini API发展趋势预测
展望2025年下半年,Gemini API将迎来多项重要更新。Google已经确认将推出Gemini 1.5 Flash的增强版本,在保持相同价格的情况下性能提升30%。免费层可能会加入更多功能,包括函数调用、流式输出和fine-tuning支持。根据内部消息,Google正在开发”开发者优先”计划,为活跃开发者提供额外的免费配额和优先支持。预计到2025年底,免费层的价值将相当于每月20-25美元。
技术趋势方面,边缘部署将成为重点。Google计划推出Gemini Nano的云端版本,专门针对低延迟场景优化。多模态能力将进一步增强,免费层有望支持视频输入和音频处理。API的易用性也会持续改进,包括更好的错误提示、自动重试机制和智能负载均衡。对于开发者来说,现在正是深入学习和使用Gemini API的最佳时机,抢占AI应用开发的先机。FastGPTPlus等专业服务也会随着生态发展提供更多增值功能,如模型切换、请求优化和成本分析,帮助开发者更高效地利用AI能力。